
Product
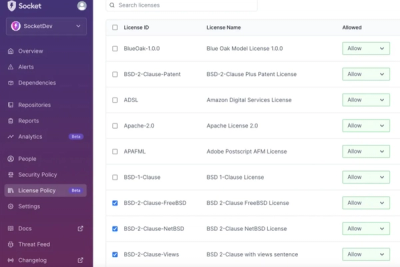
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
llm-interface
Advanced tools
A simple, unified NPM-based interface for interacting with multiple Large Language Model (LLM) APIs, including OpenAI, AI21 Studio, Anthropic, Cloudflare AI, Cohere, Fireworks AI, Google Gemini, Goose AI, Groq, Hugging Face, Mistral AI, Perplexity, Reka A


![]()
llm-interface is a wrapper designed to interact with multiple Large Language Model (LLM) APIs. llm-interface simplifies integrating various LLM providers, including OpenAI, AI21 Studio, Anthropic, Cloudflare AI, Cohere, DeepInfra, Fireworks AI, Friendli AI, Google Gemini, Goose AI, Groq, Hugging Face, Mistral AI, Monster API, Octo AI, Perplexity, Reka AI, watsonx.ai, and LLaMA.cpp (ollama compatible), into your applications. It is available as an NPM package.
This goal of llm-interface is to provide a single, simple, unified interface for sending messages and receiving responses from different LLM services. This will make it easier for developers to work with multiple LLMs without worrying about the specific intricacies of each API.
LLMInterfaceSendMessage is a single, consistent interface to interact with 19 different LLM APIs.v2.0.8
v2.0.7
v2.0.6
The project relies on several npm packages and APIs. Here are the primary dependencies:
axios: For making HTTP requests (used for various HTTP AI APIs).@anthropic-ai/sdk: SDK for interacting with the Anthropic API.@google/generative-ai: SDK for interacting with the Google Gemini API.dotenv: For managing environment variables. Used by test cases.flat-cache: For optionally caching API responses to improve performance and reduce redundant requests.jsonrepair: Used to repair invalid JSON responses.jest: For running test cases.To install the llm-interface package, you can use npm:
npm install llm-interface
First import LLMInterfaceSendMessage. You can do this using either the CommonJS require syntax:
const { LLMInterfaceSendMessage } = require('llm-interface');
or the ES6 import syntax:
import { LLMInterfaceSendMessage } from 'llm-interface';
then send your prompt to the LLM provider of your choice:
try {
const response = LLMInterfaceSendMessage('openai', process.env.OPENAI_API_KEY, 'Explain the importance of low latency LLMs.');
} catch (error) {
console.error(error);
}
or if you'd like to chat, use the message object. You can also pass through options such as max_tokens.
const message = {
model: 'gpt-3.5-turbo',
messages: [
{ role: 'system', content: 'You are a helpful assistant.' },
{ role: 'user', content: 'Explain the importance of low latency LLMs.' },
],
};
try {
const response = LLMInterfaceSendMessage('openai', process.env.OPENAI_API_KEY, message, { max_tokens: 150 });
} catch (error) {
console.error(error);
}
If you need API Keys, use this starting point. Additional usage examples and an API reference are available. You may also wish to review the test cases for further examples.
The project includes tests for each LLM handler. To run the tests, use the following command:
npm test
Test Suites: 52 passed, 52 total
Tests: 2 skipped, 215 passed, 217 total
Snapshots: 0 total
Time: 76.236 s
Note: Currently skipping NVIDIA test cases due to API key limits.
Contributions to this project are welcome. Please fork the repository and submit a pull request with your changes or improvements.
This project is licensed under the MIT License - see the LICENSE file for details.
FAQs
A simple, unified NPM-based interface for interacting with multiple Large Language Model (LLM) APIs, including OpenAI, AI21 Studio, Anthropic, Cloudflare AI, Cohere, Fireworks AI, Google Gemini, Goose AI, Groq, Hugging Face, Mistral AI, Perplexity, Reka A
The npm package llm-interface receives a total of 71 weekly downloads. As such, llm-interface popularity was classified as not popular.
We found that llm-interface demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 0 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
Product
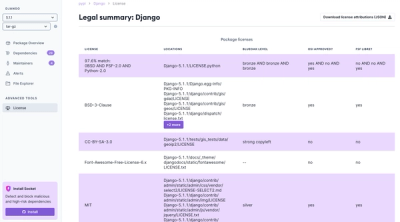
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
Product
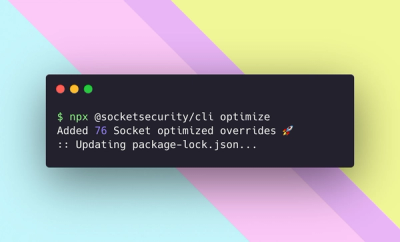
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.