Research
/Security News
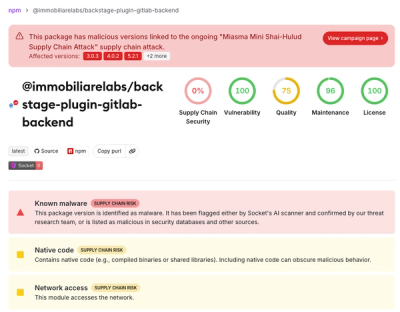
Miasma Mini Shai-Hulud Hits ImmobiliareLabs npm Packages
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.
By Socket Research Team - Jun 26, 2026
Persistent project memory for AI coding agents — semantic search, AST-aware chunking, dependency graphs, and conversation history
Named after Mímir, the Norse god of wisdom and knowledge.
Persistent project memory for AI coding agents. One command to set up, nothing to maintain.


Your agent starts every session blind — guessing filenames, grepping for keywords, burning context on irrelevant files, and forgetting everything you discussed yesterday.
On one real project, a typical prompt was burning 380K tokens and ~12 seconds end-to-end.
After indexing with mimirs: 91K tokens, ~3 seconds — a 76% drop on that codebase. Your numbers will vary with repo size, query, and model.

Bun (curl -fsSL https://bun.sh/install | bash) and, on macOS, a modern SQLite — Apple's bundled one doesn't support extensions:
brew install sqlite
Linux and Windows ship with a compatible SQLite already.
bunx mimirs init --ide claude # or: cursor, windsurf, copilot, jetbrains, all
This creates the MCP server config, editor rules, .mimirs/config.json, and .gitignore entry. Run with --ide all to set up every supported editor at once.
init covers Claude Code, Cursor, Windsurf, Copilot, and JetBrains (Junie). For everything else — Codex, Zed, custom clients — copy one of the snippets below.
The mimirs MCP server runs over stdio. Every client needs the same three things: a command (bunx), args (["mimirs@latest", "serve"]), and a RAG_PROJECT_DIR env var pointing at your project root.
.mcp.json in project root{
"mcpServers": {
"mimirs": {
"command": "bunx",
"args": ["mimirs@latest", "serve"],
"env": {
"RAG_PROJECT_DIR": "/absolute/path/to/your/project"
}
}
}
}
.cursor/mcp.json in project root{
"mcpServers": {
"mimirs": {
"command": "bunx",
"args": ["mimirs@latest", "serve"],
"env": {
"RAG_PROJECT_DIR": "/absolute/path/to/your/project"
}
}
}
}
~/.codeium/windsurf/mcp_config.json (global)Windsurf reads MCP servers from your home directory, not the project. JetBrains plugin variant uses ~/.codeium/mcp_config.json.
{
"mcpServers": {
"mimirs": {
"command": "bunx",
"args": ["mimirs@latest", "serve"],
"env": {
"RAG_PROJECT_DIR": "/absolute/path/to/your/project"
}
}
}
}
.junie/mcp.json in project root{
"mcpServers": {
"mimirs": {
"command": "bunx",
"args": ["mimirs@latest", "serve"],
"env": {
"RAG_PROJECT_DIR": "/absolute/path/to/your/project"
}
}
}
}
.vscode/mcp.json in project rootVS Code's Copilot uses a servers map (not mcpServers) and a type field.
{
"servers": {
"mimirs": {
"type": "stdio",
"command": "bunx",
"args": ["mimirs@latest", "serve"],
"env": {
"RAG_PROJECT_DIR": "/absolute/path/to/your/project"
}
}
}
}
~/.codex/config.toml (global)Codex uses TOML, not JSON, and reads from ~/.codex/config.toml. One block per project — pick a unique table name if you wire up multiple repos (mimirs-frontend, mimirs-api, etc).
[mcp_servers.mimirs]
command = "bunx"
args = ["mimirs@latest", "serve"]
env = { RAG_PROJECT_DIR = "/absolute/path/to/your/project" }
Or, equivalently, with an expanded env table:
[mcp_servers.mimirs]
command = "bunx"
args = ["mimirs@latest", "serve"]
[mcp_servers.mimirs.env]
RAG_PROJECT_DIR = "/absolute/path/to/your/project"
If the project lives in a read-only mount, set RAG_DB_DIR to a writable location. The index lives there instead of <project>/.mimirs/.
{
"mcpServers": {
"mimirs": {
"command": "bunx",
"args": ["mimirs@latest", "serve"],
"env": {
"RAG_PROJECT_DIR": "/read/only/project",
"RAG_DB_DIR": "/home/me/.cache/mimirs/myproject"
}
}
}
}
The MCP server indexes lazily on the first query, so once it's wired up you can just ask your agent something. To force a full index up front (useful for large repos):
bunx mimirs index # current directory
bunx mimirs status # how many files, chunks, embeddings
bunx mimirs demo
init)init is a convenience: it wires up your editor (MCP config, agent rules, .gitignore, .mimirs/config.json). It does not build the index, and nothing below needs it — the index and a default config are created automatically the first time you index or query.
1. Add the MCP server by hand. Drop the snippet for your client from the manual reference above: command: "bunx", args: ["mimirs@latest", "serve"], and RAG_PROJECT_DIR pointing at your project root. That is the entire MCP setup.
Without
initthere's no agent-rules file, so your assistant won't know the tools exist. Either mention mimirs in your prompt, or copy the tool list from CLAUDE.md into your editor's rules.
2. Build the index. The MCP server indexes lazily on the first tool call, so through an agent you can skip this step. To index up front (recommended for large repos, and required before the CLI search/read below):
bunx mimirs index # current directory
bunx mimirs index /path/to/repo # a specific directory
bunx mimirs index --patterns "src/**/*.ts,*.md" # restrict to globs
bunx mimirs status # files, chunks, embeddings
No init and no config file required — defaults are applied and the index is written to <project>/.mimirs/.
3. Query from the CLI. Two read commands, both running against the index in the current directory (use --dir to point elsewhere):
# Where is it? — ranked file paths + snippet previews
bunx mimirs search "where is auth handled" --top 10
# What is it? — the actual matching code chunks (functions, classes, sections)
bunx mimirs read "jwt validation" --top 8 --threshold 0.3
Scope either with --ext .ts,.tsx, --in src,packages/core, or --exclude tests. Note: the CLI search/read do not auto-index — run mimirs index first (only the MCP server indexes on demand).
For deeper integration, mimirs is also available as a Claude Code plugin. In a Claude Code session:
/plugin marketplace add https://github.com/TheWinci/mimirs.git
/plugin install mimirs
The plugin wires the MCP server, three hooks — SessionStart (context summary), PostToolUse (auto-reindex on edit), SessionEnd (auto-checkpoint) — and a set of workflow skills that orchestrate the tools for common jobs: explore, plan, review, debug, research, recall, catch-up, handoff, doc-gaps, scout, and wiki.
Want the skills without the plugin? They're plain SKILL.md files under skills/. Copy any you like into your project's .claude/skills/<name>/ (shared with the repo) or ~/.claude/skills/<name>/ (all your projects) and Claude Code picks them up next session. Skills are a Claude Code feature, so they don't apply to other editors — but the MCP tools themselves work everywhere.
89–97% Recall@10, 97–100% Recall@20, MRR 0.69–0.77. Benchmarked on four real codebases across three languages with stratified, difficulty-mixed query sets (72–120 queries each, ~⅓ hard), re-measured 2026-06-04 on the current pipeline. Full methodology in BENCHMARKS.md.
| Codebase | Language | Files | Queries | Recall@10 | MRR | Zero-miss |
|---|---|---|---|---|---|---|
| mimirs | TypeScript | 244 | 74 | 95.3% | 0.759 | 4.1% |
| Excalidraw | TypeScript | 693 | 72 | 90.3% | 0.773 | 9.7% |
| Django | Python | 3,181 | 116 | 97.4% | 0.727 | 2.6% |
| Kubernetes | Go | 8,792 | 120 | 89.2% | 0.689 | 10.8% |
The larger repos (Kubernetes, Excalidraw) are big enough that some correct files rank just past the top-10; recall reaches 97–100% by top-20, so set searchTopK: 15–20 on large repos.
We also ran mimirs on ContextBench (gold-context retrieval on real repos), whose other entries are full coding agents — multi-step explorers — not single-call tools. Given a focused query (what an LLM sends after reading the issue), one mimirs retrieval call ranks like this against whole agent trajectories:
| metric | mimirs | rank | field |
|---|---|---|---|
| File coverage | 0.799 | #1 | above OpenHands, SWE-agent, Agentless… |
| Line coverage | 0.341 | #1 | above Agentless, mini-SWE… |
| Line precision | 0.316 | #2 | behind only Agentless (0.376) |
| File precision | 0.192 | #6 | low by design — recall-first |
mimirs leads both coverage metrics as a single call. File precision is last on purpose: a missed gold file is fatal (the LLM never sees the code to fix), an extra file reference is cheap to filter — so mimirs maximizes recall and lets the model do the precision pass. And that low file precision is mostly an artifact of the metric: ~86% of the non-gold files mimirs returns are relevant context coupled to the fix (callers, types, sibling implementations), not noise — measured against gold the precision is 0.19, against relevance it is 0.87.
Same recall, a fraction of the cost. Head-to-head against a grep-only agent (raw issue, no index, no peeking at the fix) localizing the same 15 issues: mimirs delivers the relevant cluster in one ~15 ms call with zero LLM tokens; the agent took ~11.5 tool calls per issue (each an LLM step) to converge — and stopped at the primary file. On multi-file fixes the agent reached 22% of the gold files, mimirs 56% in that single call — the dependency graph surfaces the secondary files the issue never names.
n=15 sample vs the agents' 500-set — directional; agent tool-calls self-reported and capped. Full leaderboards, caveats, relevance + cost tables in BENCHMARKS.md.
| mimirs | No tool (grep + Read) | Context stuffing | Cloud RAG services | |
|---|---|---|---|---|
| Setup | One command | Nothing | Nothing | API keys, accounts |
| Token cost | ~91K/prompt | ~380K/prompt | Entire codebase | Varies |
| Search quality | 89–97% Recall@10 | Depends on keywords | N/A (everything loaded) | Varies |
| Code understanding | AST-aware (24 langs) | Line-level | None | Usually line-level |
| Cross-session memory | Conversations + checkpoints | None | None | Some |
| Privacy | Fully local | Local | Local | Data leaves your machine |
| Price | Free | Free | High token bills | $10-50/mo + tokens |
@codebase — closest overlap (local RAG, open source), but retrieval lives inside the editor extension. Mimirs is a standalone MCP server with explicit tools (search, read_relevant, project_map, search_conversation, annotate) the agent can plan around, plus conversation tailing and a wiki generator built in.bunx away and never leaves your machine.Parse & chunk — Splits content using type-matched strategies: function/class boundaries for code (via tree-sitter across 24 languages), headings for markdown, top-level keys for YAML/JSON. Chunks that exceed the embedding model's token limit are windowed and merged.
Embed — Each chunk becomes a 384-dimensional vector using all-MiniLM-L6-v2 (in-process via Transformers.js + ONNX, no API calls). Vectors are stored in sqlite-vec.
Build dependency graph — Import specifiers and exported symbols are captured during AST chunking, then resolved to build a file-level dependency graph and a symbol-level call graph. impact walks the transitive callers of a function (blast radius + tests to run); trace finds how one symbol reaches another; the mimirs affected CLI turns a git diff into the exact set of tests to run.
Hybrid search — Queries run vector similarity and BM25 in parallel, combined by reciprocal-rank fusion (weighted, default 0.5) — robust to the two scorers' very different score scales. Identifiers are split (camelCase/snake_case) so a search for depends matches getDependsOn. Results are then boosted by dependency graph centrality and path heuristics. read_relevant returns individual chunks with entity names and exact line ranges (path:start-end).
Watch & re-index — File changes are detected with a 2-second debounce. Changed files are re-indexed; deleted files are pruned.
Conversation & checkpoints — Tails Claude Code's JSONL transcripts in real time. Agents can create checkpoints at important moments for future sessions to search.
Annotations — Notes attached to files or symbols surface as [NOTE] blocks inline in read_relevant results.
Analytics — Every query is logged. Analytics surface zero-result queries, low-relevance queries, and period-over-period trends.
mimirs runs entirely on your machine. It indexes files your repo tracks plus
untracked-but-not-gitignored files (so a .env you forgot to gitignore could be
read — common secret patterns like .env, *.pem, *.key, and SSH keys are
excluded by default; add your own to exclude in .mimirs/config.json). File
content and embeddings are stored in <project>/.mimirs/index.db, a local
SQLite file. Conversation indexing reads only the current project's transcripts
under ~/.claude/projects/<this-project>/.
The only network call is a one-time download of the embedding model
(Xenova/all-MiniLM-L6-v2) from huggingface.co, cached at
~/.cache/mimirs/models. Your code never leaves your machine — nothing is sent
to any server.
AST-aware chunking via bun-chunk with tree-sitter grammars:
TypeScript, JavaScript, Python, Go, Rust, Java, C, C++, C#, Ruby, PHP, Scala, Kotlin, Lua, Zig, Elixir, Haskell, OCaml, Dart, Bash/Zsh, TOML, YAML, HTML, CSS/SCSS/LESS
Also indexes: Markdown, JSON, XML, SQL, GraphQL, Protobuf, Terraform, Dockerfiles, Makefiles, and more. Files without a known extension fall back to paragraph splitting.
| Layer | Choice |
|---|---|
| Runtime | Bun (built-in SQLite, fast TS) |
| AST chunking | bun-chunk — tree-sitter grammars for 24 languages |
| Embeddings | Transformers.js + ONNX (in-process, no daemon) |
| Embedding model | all-MiniLM-L6-v2 (~23MB, 384 dimensions) — configurable |
| Vector store | sqlite-vec (single .db file) |
| MCP | @modelcontextprotocol/sdk (stdio transport) |
| Plugin | Claude Code plugin with skills + hooks |
All data lives in .mimirs/ inside your project — add it to .gitignore.
FAQs
Persistent project memory for AI coding agents — semantic search, AST-aware chunking, dependency graphs, and conversation history
The npm package mimirs receives a total of 90 weekly downloads. As such, mimirs popularity was classified as not popular.
We found that mimirs demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.

Security News
Rolldown paused Rust React Compiler integration after a 5MB binary size increase raised concerns about shipping React-specific code to all Vite users.

Security News
/Research
Mini Shai-Hulud expands into the Go ecosystem after hitting LeoPlatform npm packages and targeting GitHub Actions workflows.