Research
/Security News
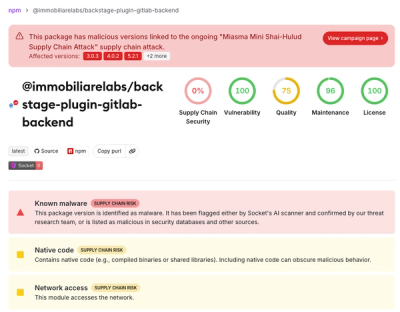
Miasma Mini Shai-Hulud Hits ImmobiliareLabs npm Packages
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.
By Socket Research Team - Jun 26, 2026
superlocalmemory
Advanced tools
Information-geometric agent memory with mathematical guarantees. 4-channel retrieval, Fisher-Rao similarity, zero-LLM mode, EU AI Act compliant. Works with Claude, Cursor, Windsurf, and 17+ AI tools.
![]()
Cache. Compress. Remember. Three surfaces — proxy, MCP tools, or skill. Every setup covered.
To the best of our knowledge, the only zero-cloud agent memory that beats Mem0's zero-LLM score on LoCoMo. Mode A: 74.8% vs Mem0 64.2% — no GPU, no API key, on CPU.
v3.6.16 — Plugin-native. Profile-aware. Distributed-ready.
Proxy: slm wrap claude · MCP: add slm_compress to your config · Skill: zero-config
3 published research papers (arXiv preprints + Zenodo-archived) · arXiv:2603.02240 · arXiv:2603.14588 · arXiv:2604.04514


![]()
Every hosted AI memory platform — Mem0 Cloud, Zep Cloud, Letta Cloud, EverMemOS Cloud — sends your data to cloud LLMs by default. Self-hosted variants exist but require Docker, a separate graph DB, or Ollama config, and most default to OpenAI until you flip env vars. After August 2, 2026, any of those cloud paths becomes a compliance question under the EU AI Act.
SuperLocalMemory V3 uses mathematics instead of cloud compute — differential geometry, algebraic topology, and stochastic analysis replace the work other systems need LLMs to do. Local-first out of the box. No Docker. No graph DB. No API keys. CPU-only.
Benchmark results (evaluated on LoCoMo, the standard long-conversation memory benchmark, published April 2026):
| System | Score | Config | Cloud LLM required? | Open Source | Source |
|---|---|---|---|---|---|
| EverMemOS | 93.05% | Cloud (proprietary) | Yes | Core only | evermind.ai (Feb 2026) |
| Hindsight (LoComo10) | 92.0% | Cloud | Yes | No | benchmarks.hindsight.vectorize.io (Apr 2026) |
| Mem0 (token-efficient) | 91.6% | Hybrid (Cohere/OpenAI) | Yes | Partial | mem0.ai blog (Apr 16 2026) |
| SLM V3 Mode C | 87.7% | Local + optional LLM | Optional (Ollama OK) | Yes (AGPL-3.0) | In-house, arXiv:2603.14588 |
| Zep v3 Cloud | 85.2% | Cloud | Yes | Community deprecated | getzep.com |
| SLM V3 Mode A | 74.8% | Local, CPU-only, zero-LLM | No | Yes (AGPL-3.0) | In-house, arXiv:2603.14588 |
| Mem0 (zero-retrieval-LLM) | 64.2% | Local baseline | No | Partial | Mem0 paper, zero-LLM row |
How to read this table. Scores from different papers use different LoCoMo splits, judge models, and prompt variants. We do NOT claim these numbers are apples-to-apples across rows. Rows marked "In-house" were run by us; cited rows link to the vendor's public source and date. The only apples-to-apples comparison is Mode A 74.8% vs Mem0 zero-retrieval-LLM 64.2% (+10.6pp) — both are zero-LLM configurations. Mem0's 91.6% and EverMemOS's 93.05% use cloud LLMs; Mode C uses a local LLM (Ollama).
What Mode A is: CPU-only, SQLite-only, zero-LLM retrieval on published LoCoMo questions. To the best of our knowledge it is the only publicly-released local-first memory that clears Mem0's zero-LLM baseline on this benchmark. If another fully-local system hits similar numbers, please open an issue so we can update this table.
Mathematical layers contribute +12.7 percentage points average across 6 conversations (n=832 questions), with up to +19.9pp on the most challenging dialogues.
# npm (recommended)
npm install -g superlocalmemory
slm setup # Choose mode (A/B/C)
slm doctor # Verify everything is working
# pip
pip install superlocalmemory
slm setup
slm doctor
# First use
slm remember "Alice works at Google as a Staff Engineer"
slm recall "What does Alice do?"
slm status
# Wrap your agent — starts proxy + sets environment + launches agent
slm wrap claude
# Your first repeat prompt → CACHE HIT → $0.00
# See savings: slm optimize savings --since 1
Upgrading: pip install -U superlocalmemory && slm restart && slm doctor — migration is automatic, no data loss.
Five-channel hybrid retrieval: Semantic (Fisher-Rao geodesic distance) + BM25 + Entity Graph + Temporal + Hopfield (associative/partial-query completion). RRF fusion, cross-encoder reranking, adaptive LightGBM ranking. All data stays local — SQLite + optional LanceDB/CozoDB.
Three mathematical contributions replace cloud LLM dependency:
Auto-capture hooks (slm hooks install) fire only on real signals — topic pivot, web call, file edit — never on a timer. Fail-open, <10ms p99 hot path.
Multi-scope memory (v3.6.15, opt-in): keep memories personal (default), shared with named profiles, or global across the machine. Off by default — recall only ever returns your own facts until you turn sharing on, per call or in config. See docs/shared-memory.md.
Multilingual: plug in any OpenAI-compatible embedding endpoint — Ollama, vLLM, LiteLLM, bge-m3, multilingual-e5, Qwen3-Embedding. The math layer is language-agnostic; 30+ languages work at full retrieval quality. No cloud dependency, no code changes.
One engine, three ways in — choose the surface that fits your setup:
| Surface | How you use it | Requires proxy? | Window effect | Cache scope |
|---|---|---|---|---|
| A — Proxy | slm wrap claude or ANTHROPIC_BASE_URL=http://127.0.0.1:8765 | Yes | Shrinks | Full-turn cache — every call |
| B — MCP tools | Add 5 tools to MCP config; call slm_compress, slm_cache_set/get | No | Preserved (1M) | Results you explicitly route through SLM |
| C — Skill | Copy skills/slm-optimize/SKILL.md → ~/.claude/skills/ | No | Preserved (1M) | Auto-applied by the agent per skill rules |
The hard constraint: The primary Claude conversation turn cannot be cached without a proxy. The MCP/skill path caches results you explicitly route through SLM (tool outputs, file reads, sub-model calls) — without a proxy the main conversation turn is not intercepted.
How to choose:
Cache: exact-match SQLite lookup (SHA-256, zero false hits) + vCache-gated semantic (opt-in). 100% cost saved on a hit (input + output tokens).
Compress: safe mode = lossless normalization (JSON/code/tool outputs, 60-95% fewer tokens); aggressive mode = LLMLingua-2 prose only (opt-in). CCR stores originals for byte-exact reversal. Anthropic 90% / OpenAI 50% prefix-cache discount alignment included. [CITATION-NEEDED-ONLINE: live provider prefix-cache discount rates]
Savings dashboard: slm optimize savings --since 7 — live USD/INR/tokens saved. Hot-reload config, fail-open.
Run SLM on multiple machines and have agents coordinate as one team — no external broker, no Docker. HTTP-based sync every 30s, mDNS discovery (SLM_MESH_DISCOVERY=on), graceful offline queue.
# Machine A (broker)
export SLM_MESH_HOST=192.168.1.100
export SLM_MESH_SHARED_SECRET=my-secret-key
slm init
# Machine B (client)
export SLM_MESH_PEER_URL=http://192.168.1.100:8765
export SLM_MESH_SHARED_SECRET=my-secret-key
slm init
8 mesh MCP tools: mesh_peers, mesh_send, mesh_broadcast, mesh_project, mesh_inbox, mesh_pending, mesh_state, mesh_lock.
Full docs: docs/multi-machine.md · docs/distributed-deployment.md
| Path | Command | When |
|---|---|---|
| npm (recommended) | npm install -g superlocalmemory | Node 14+, installs Python deps automatically |
| pip | pip install superlocalmemory | Python 3.11+, direct install |
| Claude Code Plugin (WP-06) | /plugin marketplace add qualixar/superlocalmemory then /plugin install superlocalmemory@qualixar | Self-bootstraps venv, isolated SLM_DATA_DIR, additive — 14-tool core. Ships the skills/agents/hooks/commands |
| Portable / IDE connect (WP-08) | slm connect <ide> [--here] | Wire any IDE without reinstalling; slm connect claude-code → plugin pointer |
After any install path: slm setup → slm doctor → slm warmup (optional, pre-downloads ~500MB embedding model).
| Component | Size | When |
|---|---|---|
| Core libraries (numpy, scipy, networkx) | ~50MB | During install |
| Dashboard & MCP server (fastapi, uvicorn) | ~20MB | During install |
| Learning engine (lightgbm) | ~10MB | During install |
| Search engine (sentence-transformers, torch) | ~200MB | During install |
| Embedding model (nomic-embed-text-v1.5, 768d) | ~500MB | First use or slm warmup |
Mode B requires Ollama + a model (ollama pull llama3.2) | ~2GB | Manual |
SLM supports two MCP transports:
HTTP (recommended, v3.6.7+):
{ "mcpServers": { "superlocalmemory": { "type": "http", "url": "http://127.0.0.1:8765/mcp/" } } }
Or: claude mcp add --transport http superlocalmemory http://127.0.0.1:8765/mcp/
stdio (universal fallback):
{ "mcpServers": { "superlocalmemory": { "command": "slm", "args": ["mcp"] } } }
Control tool surface via SLM_MCP_PROFILE:
| Profile | Tools | Use case |
|---|---|---|
core14 (default) | 14 | Memory core — remember, recall, forget, session_init, + mesh |
mesh8 | 8 | Mesh-only — multi-machine coordination |
full38 | 38 | Core + optimize + evolution + trust |
power50 | 50 | Full38 + admin + ingestion + compliance |
whole81 | 81 | Every tool (SLM_MCP_ALL_TOOLS=1) |
Precedence: ALL > TOOLS > PROFILE > default
export SLM_MCP_PROFILE=full38 # or core14 / mesh8 / power50 / whole81
slm mcp
Per-IDE configs available for Claude Code, Cursor, Windsurf, VS Code Copilot, Continue, Gemini CLI, JetBrains, Zed, and more (15 configs in ide/configs/). See docs/ide-setup.md.
Install directly in Claude Code — no system-level npm/pip needed. This is how you get the skills, agents, hooks, commands, and rules (the MCP server is bootstrapped automatically). It is a two-step flow — add the marketplace once, then install:
# 1. Add the Qualixar marketplace (one-time — the repo IS the marketplace)
/plugin marketplace add qualixar/superlocalmemory
# 2. Install the plugin
/plugin install superlocalmemory@qualixar
SLM_DATA_DIRcore14 profile by default)slm connect claude-code detects an existing plugin install and links themPlugin vs
pip/npm:pip install superlocalmemory/npm i -g superlocalmemorygive you theslmCLI + the MCP server (the tools). The skills/agents/hooks/ commands come only through the plugin above. Use the plugin for Claude Code; use pip/npm for the CLI or other IDEs.
To update later: /plugin marketplace update qualixar then /plugin install superlocalmemory@qualixar.
| Mode | What | Cloud? | EU AI Act | Best For |
|---|---|---|---|---|
| A | Local Guardian | None | Compliant | Privacy-first, air-gapped, enterprise |
| B | Smart Local | Local only (Ollama) | Compliant | Better answers, data stays local |
| C | Full Power | Cloud LLM | Partial | Maximum accuracy, research |
slm mode a # Zero-cloud (default)
slm mode b # Local Ollama
slm mode c # Cloud LLM
Mode A is, to the best of our knowledge, the only publicly-released agent memory that runs with zero cloud calls while clearing Mem0's published LoCoMo score. All data stays on your device. No API keys. No GPU. Runs on 2 vCPUs + 4GB RAM.
The EU AI Act (Regulation 2024/1689) takes full effect August 2, 2026.
| Requirement | Mode A | Mode B | Mode C |
|---|---|---|---|
| Data sovereignty (Art. 10) | Pass | Pass | Requires DPA |
| Right to erasure (GDPR Art. 17) | Pass | Pass | Pass |
| Transparency (Art. 13) | Pass | Pass | Pass |
| No network calls during memory ops | Yes | Yes | No |
To the best of our knowledge, no existing agent memory system addresses EU AI Act compliance by architectural design. Modes A and B pass all checks — no personal data leaves the device during any memory operation.
Built-in compliance tools: GDPR Article 15/17 export + complete erasure, tamper-proof SHA-256 audit chain, data provenance tracking, ABAC policy enforcement. See docs/compliance.md.
| Topic | Link |
|---|---|
| Full optimize docs | docs/optimize-overview.md · docs/optimize-cli.md · docs/optimize-config.md |
| Distributed deployment | docs/distributed-deployment.md |
| Multi-machine mesh | docs/multi-machine.md |
| Auto-memory hooks | docs/auto-memory.md |
| Architecture + math | docs/ARCHITECTURE.md |
| CLI reference | docs/cli-reference.md |
| MCP tools reference | docs/mcp-tools.md |
| Getting started | docs/getting-started.md |
| IDE setup (15 configs) | docs/ide-setup.md |
| Skill evolution | docs/skill-evolution.md |
| V2 migration | docs/migration-from-v2.md |
| Configuration | docs/configuration.md |
| Wiki | github.com/qualixar/superlocalmemory/wiki |
Web dashboard:
slm dashboard # Opens at http://localhost:8765
17-tab sidebar with Knowledge Graph (Sigma.js WebGL, community detection), Health Monitor, Entity Explorer, Mesh Peers, Ingestion Status, Privacy blur mode. Cross-platform: macOS + Windows + Linux.
Release history:
| Version | Codename | Key Features |
|---|---|---|
| v3.6.16 | Docs | Corrected Claude Code plugin install — adds the required /plugin marketplace add step; clarifies plugin vs pip/npm delivery |
| v3.6.15 | Multi-scope | Opt-in shared memory (personal/shared/global, off by default), default-deny scope at every read path, recall scope-race fix, contributor PRs #42/#43/#44, fixes #46–#49 |
| v3.6.14 | Plugin-native | Claude Code Plugin (WP-06), MCP profiles (WP-01), IDE connect (WP-08), asset consolidation, UI polish (WP-12) |
| v3.6.x | Optimize Everywhere / Distributed-ready | Three surfaces (proxy/MCP/skill), SLM_REMOTE=1 LAN mode, remote dashboard, custom LLM endpoints |
| v3.5.0 | Scale-Ready | CozoDB/LanceDB, 6-channel recall <1s, Core Memory Block, context injection v2, score normalization |
| v3.4.x | Scale-Ready (foundation) | Tiered storage, graph pruning, Hopfield channel, LightGBM ranking, mDNS mesh discovery |
| v3.3.x | Foundation | BM25Plus, Fisher-Rao, sqlite-vec, RRF fusion, cross-encoder rerank. 3 published papers |
SuperLocalMemory is backed by three published research papers (arXiv preprints + Zenodo DOIs). These are preprints — not conference-accepted or journal-published yet.
SuperLocalMemory V3.3: The Living Brain — Biologically-Inspired Forgetting, Cognitive Quantization, and Multi-Channel Retrieval for Zero-LLM Agent Memory Systems Varun Pratap Bhardwaj (2026) arXiv:2604.04514 · Zenodo DOI: 10.5281/zenodo.19435120
SuperLocalMemory V3: Information-Geometric Foundations for Zero-LLM Enterprise Agent Memory Varun Pratap Bhardwaj (2026) arXiv:2603.14588 · Zenodo DOI: 10.5281/zenodo.19038659
SuperLocalMemory: A Structured Local Memory Architecture for Persistent AI Agent Context Varun Pratap Bhardwaj (2026) arXiv:2603.02240 · Zenodo DOI: 10.5281/zenodo.18709670
@article{bhardwaj2026slmv33,
title={SuperLocalMemory V3.3: The Living Brain — Biologically-Inspired
Forgetting, Cognitive Quantization, and Multi-Channel Retrieval
for Zero-LLM Agent Memory Systems},
author={Bhardwaj, Varun Pratap},
journal={arXiv preprint arXiv:2604.04514},
year={2026},
url={https://arxiv.org/abs/2604.04514}
}
@article{bhardwaj2026slmv3,
title={Information-Geometric Foundations for Zero-LLM Enterprise Agent Memory},
author={Bhardwaj, Varun Pratap},
journal={arXiv preprint arXiv:2603.14588},
year={2026}
}
@article{bhardwaj2026slm,
title={A Structured Local Memory Architecture for Persistent AI Agent Context},
author={Bhardwaj, Varun Pratap},
journal={arXiv preprint arXiv:2603.02240},
year={2026}
}
See CONTRIBUTING.md for guidelines. Wiki for detailed documentation.
GNU Affero General Public License v3.0 (AGPL-3.0). See LICENSE.
For commercial licensing (closed-source, proprietary, or hosted use), see COMMERCIAL-LICENSE.md or contact varun.pratap.bhardwaj@gmail.com.
Copyright (c) 2026 Varun Pratap Bhardwaj / Qualixar.
Part of Qualixar · Author: Varun Pratap Bhardwaj
slm ingest --source ecc. We recommend ECC for Claude Code users who want the deepest learning experience alongside SLM.Qualixar is building the open-source infrastructure for AI agent reliability engineering. Seven products, one coherent platform:
| Product | Purpose | Install |
|---|---|---|
| SuperLocalMemory | Persistent memory + learning | npm install -g superlocalmemory |
| Qualixar OS | Universal agent runtime | npx qualixar-os |
| SLM Mesh | P2P coordination across sessions | npm i slm-mesh |
| SLM MCP Hub | Federate 430+ MCP tools | pip install slm-mcp-hub |
| AgentAssay | Token-efficient agent testing | pip install agentassay |
| AgentAssert | Behavioral contracts + drift detection | pip install agentassert-abc |
| SkillFortify | Formal verification for agent skills | pip install skillfortify |
Zero cloud dependency. Local-first. EU AI Act compliant.
Start here → qualixar.com · All papers on Qualixar HuggingFace
Built with mathematical rigor. Not in the race — here to help everyone build better AI memory systems.
If this project solves a real problem for you, please star the repo — it helps other developers discover Qualixar and signals that the AI agent reliability community is growing.
FAQs
Information-geometric agent memory with mathematical guarantees. 4-channel retrieval, Fisher-Rao similarity, zero-LLM mode, EU AI Act compliant. Works with Claude, Cursor, Windsurf, and 17+ AI tools.
The npm package superlocalmemory receives a total of 1,111 weekly downloads. As such, superlocalmemory popularity was classified as popular.
We found that superlocalmemory demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
/Security News
Miasma Mini Shai-Hulud hits @immobiliarelabs Backstage plugins, targeting GitLab and LDAP auth packages on npm.

Security News
Rolldown paused Rust React Compiler integration after a 5MB binary size increase raised concerns about shipping React-specific code to all Vite users.

Security News
/Research
Mini Shai-Hulud expands into the Go ecosystem after hitting LeoPlatform npm packages and targeting GitHub Actions workflows.