text-annotator
Advanced tools
text-annotator - npm Package Compare versions
Comparing version 0.8.8 to 1.0.0
@@ -8,722 +8,265 @@ "use strict"; | ||
| var _htmlEntities = require("html-entities"); | ||
| var _sbd = _interopRequireDefault(require("./ext/sbd")); | ||
| function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; } | ||
| // div inside span is a bad idea | ||
| const blockElements = ['address', 'article', 'aside', 'blockquote', 'canvas', 'dd', 'div', 'dl', 'dt', 'fieldset', 'figcaption', 'figure', 'footer', 'form', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'header', 'hgroup', 'hr', 'li', 'main', 'nav', 'noscript', 'ol', 'output', 'p', 'pre', 'section', 'table', 'tfoot', 'ul', 'video']; | ||
| class TextAnnotator { | ||
| constructor(options = {}) { | ||
| const content = options.content; // isHTML is used to reduce the memory used: stripedHTML is empty if isHTML is false | ||
| constructor(html) { | ||
| this.html = html; | ||
| const isHTML = options.isHTML === undefined || options.isHTML; // annotatedContent is introduced in order to avoid passing content in the methods | ||
| const { | ||
| text, | ||
| tags | ||
| } = this._stripHTMLTags(html); | ||
| this.originalContent = this.annotatedContent = content; | ||
| this.isHTML = isHTML; // stripedHTML and tagLocations are needed only when the content is HTML | ||
| this.text = text; // [{ index, length, isCloseTag, annotationIndex* }]; ordered by index | ||
| this.stripedHTML = ''; | ||
| this.tagLocations = []; // sentences are used in sentence-based fuzzy search | ||
| this.tags = tags; // [{ index, length }]; unordered | ||
| this.sentences = []; // future work: one highlight can have more than one location because of the potential issue in tag insertion | ||
| this.annotations = []; | ||
| } | ||
| this.highlights = []; | ||
| search(searchText, { | ||
| prefix = '', | ||
| postfix = '', | ||
| trim = true, | ||
| caseSensitive = false, | ||
| offset = 0 | ||
| } = {}) { | ||
| const { | ||
| text, | ||
| annotations | ||
| } = this; | ||
| let str = prefix + searchText + postfix; | ||
| str = trim ? str.trim() : str; | ||
| str = caseSensitive ? str : str.toLowerCase(); | ||
| const index = (caseSensitive ? text : text.toLowerCase()).indexOf(str, offset); | ||
| const prefixLength = trim ? prefix.replace(/^\s+/, '').length : prefix.length; | ||
| const postfixLength = trim ? postfix.replace(/\s+$/, '').length : postfix.length; | ||
| return index === -1 ? -1 : annotations.push({ | ||
| index: index + prefixLength, | ||
| length: str.substring(prefixLength, str.length - postfixLength).length | ||
| }) - 1; | ||
| } | ||
| if (isHTML) { | ||
| this.stripAndStoreHTMLTags(); | ||
| } | ||
| } // the order of directSearch => fuzzy search => eager search is tailored for specific feature, it is now the default way of search but it can be customized via options. More customizations can be done by composing functions | ||
| searchAll(searchText, options) { | ||
| let offset = 0; | ||
| const annotationIndexes = []; | ||
| let annotationIndex = -1; // do not mutate param | ||
| const newOptions = Object.assign({}, options); | ||
| search(str, options = {}) { | ||
| let prefix = options.prefix || ''; | ||
| let postfix = options.postfix || ''; | ||
| const directSearchOptions = options.directSearchOptions || {}; | ||
| const fuzzySearchOptions = options.fuzzySearchOptions; | ||
| const eagerSearchOptions = options.eagerSearchOptions; // trim by default | ||
| do { | ||
| annotationIndex = this.search(searchText, newOptions); | ||
| const trim = options.trim === undefined || options.trim; // used unless overwritten | ||
| const caseSensitive = options.caseSensitive; | ||
| if (trim) { | ||
| const res = TextAnnotator.trim(prefix, str, postfix); | ||
| prefix = res.prefix; | ||
| str = res.str; | ||
| postfix = res.postfix; | ||
| } | ||
| let highlightIndex = -1; // direct search will always be performed | ||
| highlightIndex = this.directSearch(prefix, str, postfix, Object.assign({ | ||
| caseSensitive | ||
| }, directSearchOptions)); | ||
| if (highlightIndex !== -1) { | ||
| return highlightIndex; | ||
| } // experimental feature | ||
| if (fuzzySearchOptions) { | ||
| highlightIndex = this.fuzzySearch(prefix, str, postfix, Object.assign({ | ||
| caseSensitive | ||
| }, fuzzySearchOptions)); | ||
| if (highlightIndex !== -1) { | ||
| return highlightIndex; | ||
| if (annotationIndex !== -1) { | ||
| offset = this.annotations[annotationIndex].index + 1; | ||
| newOptions.offset = offset; | ||
| annotationIndexes.push(annotationIndex); | ||
| } | ||
| } // experimental feature | ||
| // eager search only works in (particular) browsers | ||
| } while (annotationIndex !== -1); | ||
| return annotationIndexes; | ||
| } | ||
| if (eagerSearchOptions) { | ||
| highlightIndex = this.eagerSearch(prefix, str, postfix, Object.assign({ | ||
| caseSensitive | ||
| }, eagerSearchOptions)); | ||
| annotate(annotationIndex, { | ||
| tagName = 'span', | ||
| baseClassName = 'annotation', | ||
| classPattern = 'annotation-' | ||
| } = {}) { | ||
| const { | ||
| tags, | ||
| annotations, | ||
| _insert, | ||
| _binaryInsert | ||
| } = this; | ||
| const annotation = annotations[annotationIndex]; // [start, end, offset] | ||
| if (highlightIndex !== -1) { | ||
| return highlightIndex; | ||
| } | ||
| } | ||
| const annotationLocation = [annotation.index, annotation.index + annotation.length, 0]; // partition | ||
| return highlightIndex; | ||
| } // experimental feature | ||
| // only support direct search for now | ||
| const annotatorLocations = [[...annotationLocation]]; | ||
| for (let i = 0; i < tags.length; i++) { | ||
| const { | ||
| index: tagIndex, | ||
| length: tagLength | ||
| } = tags[i]; | ||
| searchAll(str, options = {}) { | ||
| const highlightIndexes = []; | ||
| if (tagIndex <= annotationLocation[0]) { | ||
| annotatorLocations[0][2] += tagLength; | ||
| } else if (tagIndex < annotationLocation[1]) { | ||
| const lastTagIndex = i === 0 ? 0 : tags[i - 1].index; | ||
| const lastAnnotatorLocation = annotatorLocations[annotatorLocations.length - 1]; | ||
| const continueSearch = (str, options) => { | ||
| const highlightIndex = this.search(str, options); | ||
| if (highlightIndex !== -1) { | ||
| highlightIndexes.push(highlightIndex); | ||
| options.directSearchOptions = options.directSearchOptions || {}; | ||
| options.directSearchOptions.lastHighlightIndex = highlightIndex; | ||
| continueSearch(str, options); | ||
| if (tagIndex === lastTagIndex) { | ||
| lastAnnotatorLocation[2] += tagLength; | ||
| } else { | ||
| const annotatorLocationEnd = lastAnnotatorLocation[1]; | ||
| lastAnnotatorLocation[1] = tagIndex; | ||
| annotatorLocations.push([lastAnnotatorLocation[1], annotatorLocationEnd, lastAnnotatorLocation[2] + tagLength]); | ||
| } | ||
| } else { | ||
| break; | ||
| } | ||
| }; | ||
| } // insert annotator tags into tag list and html | ||
| continueSearch(str, options); | ||
| return highlightIndexes; | ||
| } | ||
| highlight(highlightIndex, options = {}) { | ||
| const highlightTagName = options.highlightTagName || 'span'; | ||
| const highlightClass = options.highlightClass || 'highlight'; | ||
| const highlightIdPattern = options.highlightIdPattern || 'highlight-'; | ||
| const openTag = TextAnnotator.createOpenTag(highlightTagName, highlightIdPattern, highlightIndex, highlightClass); | ||
| const loc = this.adjustLoc(highlightTagName, highlightIdPattern, highlightIndex, highlightClass); | ||
| this.annotatedContent = TextAnnotator.insert(this.annotatedContent, openTag, loc[0]); | ||
| this.annotatedContent = TextAnnotator.insert(this.annotatedContent, TextAnnotator.createCloseTag(highlightTagName), loc[1] + openTag.length); // it has to be set after adjustLoc so that it will not be checked | ||
| const annotatorOpenTag = `<${tagName} class="${baseClassName} ${classPattern}${annotationIndex}">`; | ||
| const annotatorCloseTag = `</${tagName}>`; | ||
| const annotatorOpenTagLength = annotatorOpenTag.length; | ||
| const annotatorCloseTagLength = annotatorCloseTag.length; | ||
| let locInc = 0; | ||
| this.highlights[highlightIndex].highlighted = true; | ||
| return this.annotatedContent; | ||
| } // experimental feature | ||
| for (let i = 0; i < annotatorLocations.length; i++) { | ||
| const annotatorLocation = annotatorLocations[i]; | ||
| _binaryInsert(tags, { | ||
| index: annotatorLocation[0], | ||
| length: annotatorOpenTagLength, | ||
| isCloseTag: false, | ||
| annotationIndex | ||
| }, (a, b) => { | ||
| return a.index <= b.index ? -1 : 1; | ||
| }); | ||
| highlightAll(highlightIndexes, options = {}) { | ||
| for (let i = 0; i < highlightIndexes.length; i++) { | ||
| this.annotatedContent = this.highlight(highlightIndexes[i], options); | ||
| } | ||
| _binaryInsert(tags, { | ||
| index: annotatorLocation[1], | ||
| length: annotatorCloseTagLength, | ||
| isCloseTag: true, | ||
| annotationIndex | ||
| }, (a, b) => a.index - b.index); | ||
| return this.annotatedContent; | ||
| } | ||
| searchAndHighlight(str, options = {}) { | ||
| const highlightIndex = this.search(str, options.searchOptions); | ||
| if (highlightIndex !== -1) { | ||
| return { | ||
| highlightIndex, | ||
| content: this.highlight(highlightIndex, options.highlightOptions) | ||
| }; | ||
| this.html = _insert(this.html, annotatorOpenTag, annotatorLocation[0] + annotatorLocation[2] + locInc); | ||
| this.html = _insert(this.html, annotatorCloseTag, annotatorLocation[1] + annotatorLocation[2] + locInc + annotatorOpenTagLength); | ||
| locInc += annotatorOpenTagLength + annotatorCloseTagLength; | ||
| } | ||
| } | ||
| unhighlight(highlightIndex, options = {}) { | ||
| const highlightTagName = options.highlightTagName || 'span'; | ||
| const highlightClass = options.highlightClass || 'highlight'; | ||
| const highlightIdPattern = options.highlightIdPattern || 'highlight-'; // it has to be set before adjustLoc so that it will not be checked | ||
| this.highlights[highlightIndex].highlighted = false; // need to change when one annotation => more than one highlight | ||
| const loc = this.adjustLoc(highlightTagName, highlightIdPattern, highlightIndex, highlightClass); | ||
| const openTagLength = TextAnnotator.getOpenTagLength(highlightTagName, highlightIdPattern, highlightIndex, highlightClass); | ||
| const substr1 = this.annotatedContent.substring(loc[0], loc[1] + openTagLength + TextAnnotator.getCloseTagLength(highlightTagName)); | ||
| const substr2 = this.annotatedContent.substring(loc[0] + openTagLength, loc[1] + openTagLength); | ||
| this.annotatedContent = this.annotatedContent.replace(substr1, substr2); | ||
| return this.annotatedContent; | ||
| return this.html; | ||
| } | ||
| stripAndStoreHTMLTags() { | ||
| let tag; | ||
| this.stripedHTML = this.originalContent; | ||
| const tagRegEx = /<[^>]+>/; | ||
| let indexInc = 0; | ||
| while (tag = this.stripedHTML.match(tagRegEx)) { | ||
| this.stripedHTML = this.stripedHTML.replace(tag, ''); | ||
| const tagLength = tag[0].length; // tagLocations will be used in adjustLoc | ||
| this.tagLocations.push([tag.index, tagLength, indexInc]); | ||
| indexInc += tagLength; | ||
| } | ||
| annotateAll(annotationIndexes, options) { | ||
| annotationIndexes.forEach(annotationIndex => { | ||
| this.annotate(annotationIndex, options); | ||
| }); | ||
| return this.html; | ||
| } | ||
| directSearch(prefix, str, postfix, directSearchOptions = {}) { | ||
| const caseSensitive = directSearchOptions.caseSensitive; // experimental option; used for specific feature | ||
| const ifEncode = directSearchOptions.encode; | ||
| const lastHighlightIndex = directSearchOptions.lastHighlightIndex; | ||
| let strWithFixes = prefix + str + postfix; | ||
| let text = this.isHTML ? this.stripedHTML : this.originalContent; | ||
| if (!caseSensitive) { | ||
| strWithFixes = strWithFixes.toLowerCase(); | ||
| text = text.toLowerCase(); | ||
| } // for searchAll | ||
| let offset = 0; | ||
| if (lastHighlightIndex !== undefined) { | ||
| offset = this.highlights[lastHighlightIndex].loc[1] + 1; | ||
| } | ||
| let highlightIndex = -1; | ||
| const index = text.indexOf(strWithFixes, offset); // experimental feature: if the text to be searched does not work, try to encode it | ||
| if (ifEncode && index === -1) { | ||
| const encodedStrWithFixes = (0, _htmlEntities.encode)(strWithFixes); | ||
| const index = text.indexOf(encodedStrWithFixes, offset); | ||
| if (index !== -1) { | ||
| const loc = []; | ||
| loc[0] = index + (0, _htmlEntities.encode)(prefix).length; | ||
| loc[1] = loc[0] + (0, _htmlEntities.encode)(str).length; | ||
| highlightIndex = this.highlights.push({ | ||
| loc | ||
| }) - 1; | ||
| unannotate(annotationIndex) { | ||
| // annotatorIndexesInTags amd annotators have the same size | ||
| const annotatorIndexesInTags = []; | ||
| const annotators = this.tags.filter((tag, index) => { | ||
| if (tag.annotationIndex === annotationIndex) { | ||
| annotatorIndexesInTags.push(index); | ||
| } | ||
| } else if (index !== -1) { | ||
| const loc = []; | ||
| loc[0] = index + prefix.length; | ||
| loc[1] = loc[0] + str.length; | ||
| highlightIndex = this.highlights.push({ | ||
| loc | ||
| }) - 1; | ||
| } | ||
| return highlightIndex; | ||
| } | ||
| return tag.annotationIndex === annotationIndex; | ||
| }); | ||
| const otherTags = this.tags.filter(tag => tag.annotationIndex !== annotationIndex); // find index difference | ||
| eagerSearch(prefix, str, postfix, eagerSearchOptions = {}) { | ||
| const caseSensitive = eagerSearchOptions.caseSensitive; | ||
| const containerId = eagerSearchOptions.containerId; | ||
| const threshold = eagerSearchOptions.threshold || 0.74; | ||
| const strWithFixes = prefix + str + postfix; | ||
| let highlightIndex = -1; // IE is not considered | ||
| for (let i = 0; i < annotators.length; i++) { | ||
| const annotator = annotators[i]; | ||
| let indexInc = 0; | ||
| if (window.find) { | ||
| document.designMode = 'on'; // step 1: ask the browser to highlight the found | ||
| for (let j = 0; j < otherTags.length; j++) { | ||
| const otherTag = otherTags[j]; | ||
| const sel = window.getSelection(); | ||
| sel.collapse(document.body, 0); | ||
| while (window.find(strWithFixes, caseSensitive)) { | ||
| document.execCommand('hiliteColor', true, 'rgba(255, 255, 255, 0)'); | ||
| sel.collapseToEnd(); // step 2: locate the found within the container where the annotator is applied | ||
| // selector may become better | ||
| const found = document.querySelector('#' + containerId + ' [style="background-color: rgba(255, 255, 255, 0);"]'); | ||
| if (found) { | ||
| const foundStr = found.innerHTML.replace(/<[^>]*>/g, ''); | ||
| const result = TextAnnotator.getBestSubstring(foundStr, str, threshold); | ||
| if (result.similarity) { | ||
| const text = this.isHTML ? this.stripedHTML : this.originalContent; | ||
| const index = text.indexOf(foundStr); | ||
| if (index !== -1) { | ||
| highlightIndex = this.highlights.push({ | ||
| loc: [index + result.loc[0], index + result.loc[1]] | ||
| }) - 1; | ||
| } | ||
| } | ||
| if (annotator.index < otherTag.index) { | ||
| break; | ||
| } | ||
| } // step 3: remove the highlights created by the browser | ||
| document.execCommand('undo'); | ||
| document.designMode = 'off'; | ||
| } | ||
| return highlightIndex; | ||
| } | ||
| fuzzySearch(prefix, str, postfix, fuzzySearchOptions = {}) { | ||
| const caseSensitive = fuzzySearchOptions.caseSensitive; | ||
| const tokenBased = fuzzySearchOptions.tokenBased; | ||
| let tbThreshold = fuzzySearchOptions.tbThreshold || 0.68; // sentence-based fuzzy search is enabled by default | ||
| const sentenceBased = fuzzySearchOptions.sentenceBased === undefined || fuzzySearchOptions.sentenceBased; | ||
| let sbThreshold = fuzzySearchOptions.sbThreshold || 0.85; | ||
| const maxLengthDiff = fuzzySearchOptions.maxLengthDiff || 0.1; | ||
| const lenRatio = fuzzySearchOptions.lenRatio || 2; | ||
| const processSentence = fuzzySearchOptions.processSentence; | ||
| let highlightIndex = -1; | ||
| const text = this.isHTML ? this.stripedHTML : this.originalContent; // token-based | ||
| if (tokenBased || prefix || postfix) { | ||
| // step 1: find all indexes of str | ||
| const strIndexes = []; | ||
| let i = -1; | ||
| while ((i = text.indexOf(str, i + 1)) !== -1) { | ||
| strIndexes.push(i); | ||
| } // step 2: find the index of the most similar "fragment" - the str with pre- and post- fixes | ||
| let strIndex = -1; | ||
| const fragment = prefix + str + postfix; | ||
| for (let i = 0; i < strIndexes.length; i++) { | ||
| const si = strIndexes[i]; // f can be wider | ||
| const f = text.substring(si - prefix.length, si) + str + text.substring(si + str.length, si + str.length + postfix.length); | ||
| const similarity = TextAnnotator.getSimilarity(f, fragment, caseSensitive); | ||
| if (similarity >= tbThreshold) { | ||
| tbThreshold = similarity; | ||
| strIndex = si; | ||
| } | ||
| } // step 3: check whether the most similar enough "fragment" is found, if yes return its location | ||
| if (strIndex !== -1) { | ||
| highlightIndex = this.highlights.push({ | ||
| loc: [strIndex, strIndex + str.length] | ||
| }) - 1; | ||
| } | ||
| } // sentence-based | ||
| else if (sentenceBased) { | ||
| // step 1: sentenize the text if has not done so | ||
| let sentences = []; | ||
| if (this.sentences.length) { | ||
| sentences = this.sentences; | ||
| } else if (annotator.index > otherTag.index) { | ||
| indexInc += otherTag.length; | ||
| } else { | ||
| sentences = this.sentences = TextAnnotator.sentenize(text); | ||
| } // step 2 (for efficiency only): filter sentences by words of the str | ||
| const words = str.split(/\s/); | ||
| const filteredSentences = []; | ||
| for (let i = 0; i < sentences.length; i++) { | ||
| for (let j = 0; j < words.length; j++) { | ||
| if (sentences[i].raw.includes(words[j])) { | ||
| filteredSentences.push(sentences[i]); | ||
| break; | ||
| if (otherTag.annotationIndex === undefined) { | ||
| if (!annotator.isCloseTag) { | ||
| indexInc += otherTag.length; | ||
| } | ||
| } | ||
| } //step 3 (optional) | ||
| if (processSentence) { | ||
| let index = 0; // for each sentence | ||
| for (let i = 0; i < filteredSentences.length; i++) { | ||
| const fs = filteredSentences[i]; | ||
| let raw = fs.raw; // loc without tags | ||
| const loc = [fs.index, fs.index + raw.length]; | ||
| let locInc = 0; // add loc of all tags before the one being checked so as to derive the actual loc | ||
| const tagLocations = this.tagLocations; // for each loc of tag whose loc is larger than the last sentence | ||
| for (let j = index; j < tagLocations.length; j++) { | ||
| const tagLoc = tagLocations[j]; | ||
| if (tagLoc[0] >= loc[0] && tagLoc[0] <= loc[1]) { | ||
| const tag = this.originalContent.substring(tagLoc[0] + tagLoc[2], tagLoc[0] + tagLoc[2] + tagLoc[1]); | ||
| const insertIndex = tagLoc[0] + locInc - loc[0]; | ||
| raw = raw.slice(0, insertIndex) + tag + raw.slice(insertIndex); | ||
| locInc += tagLoc[1]; | ||
| } else if (tagLoc[0] > loc[1]) { | ||
| index = j; // not sure this part | ||
| break; | ||
| } else { | ||
| if (annotator.annotationIndex < otherTag.annotationIndex) { | ||
| if (otherTag.isCloseTag) { | ||
| indexInc += otherTag.length; | ||
| } | ||
| } | ||
| raw = processSentence(raw); | ||
| raw = raw.replace(/(<([^>]+)>)/gi, ''); | ||
| const copy = fs.raw; // update the sentence if it got reduced | ||
| if (copy !== raw) { | ||
| fs.raw = raw; | ||
| fs.index = fs.index + copy.indexOf(raw); | ||
| } | ||
| } | ||
| } // step 4: find the most possible sentence | ||
| let mostPossibleSentence = null; | ||
| for (let i = 0; i < filteredSentences.length; i++) { | ||
| const sentence = filteredSentences[i]; | ||
| const similarity = TextAnnotator.getSimilarity(sentence.raw, str, caseSensitive); | ||
| if (similarity >= sbThreshold) { | ||
| sbThreshold = similarity; | ||
| mostPossibleSentence = sentence; | ||
| } else if (i !== filteredSentences.length - 1) { | ||
| // combine two sentences to reduce the inaccuracy of sentenizing text | ||
| const newSentenceRaw = sentence.raw + filteredSentences[i + 1].raw; | ||
| const lengthDiff = Math.abs(newSentenceRaw.length - str.length) / str.length; | ||
| if (lengthDiff <= maxLengthDiff) { | ||
| const newSimilarity = TextAnnotator.getSimilarity(newSentenceRaw, str, caseSensitive); | ||
| if (newSimilarity >= sbThreshold) { | ||
| sbThreshold = newSimilarity; | ||
| mostPossibleSentence = { | ||
| raw: newSentenceRaw, | ||
| index: sentence.index | ||
| }; | ||
| } else { | ||
| if (!annotator.isCloseTag) { | ||
| indexInc += otherTag.length; | ||
| } | ||
| } | ||
| } | ||
| } // step 5: if the most possible sentence is found, derive and return the location of the most similar str from it | ||
| if (mostPossibleSentence) { | ||
| const result = TextAnnotator.getBestSubstring(mostPossibleSentence.raw, str, sbThreshold, lenRatio, caseSensitive, true); | ||
| if (result.loc) { | ||
| let index = mostPossibleSentence.index; | ||
| highlightIndex = this.highlights.push({ | ||
| loc: [index + result.loc[0], index + result.loc[1]] | ||
| }) - 1; | ||
| } | ||
| } | ||
| } | ||
| } // remove annotators one by one | ||
| return highlightIndex; | ||
| } // future work: further improvement when one annotation binds with more than one highlight | ||
| // includeRequiredTag used in = condition only | ||
| includeRequiredTag(i, highlightLoc, tag) { | ||
| const isCloseTag = tag.startsWith('</'); | ||
| const tagName = isCloseTag ? tag.split('</')[1].split('>')[0] : tag.split(' ')[0].split('<')[1].split('>')[0]; | ||
| let included = false; | ||
| let requiredTagNumber = 1; | ||
| let requiredTagCount = 0; // if both the start tag and the end tag are at the borders, place the tags outside the borders | ||
| // if the close tag is at the border, check backwards until the start of the highlight | ||
| if (isCloseTag) { | ||
| for (let i2 = i - 1; i2 >= 0; i2--) { | ||
| const tagLoc2 = this.tagLocations[i2]; | ||
| if (highlightLoc[0] > tagLoc2[0]) { | ||
| break; | ||
| } else { | ||
| const tag2 = this.originalContent.substring(tagLoc2[0] + tagLoc2[2], tagLoc2[0] + tagLoc2[2] + tagLoc2[1]); | ||
| if (tag2.startsWith('</' + tagName)) { | ||
| requiredTagNumber++; | ||
| } else if (tag2.startsWith('<' + tagName)) { | ||
| requiredTagCount++; | ||
| } | ||
| if (requiredTagNumber === requiredTagCount) { | ||
| included = true; | ||
| break; | ||
| } | ||
| } | ||
| } | ||
| } // if the start tag is at the border, check forwards until the end of the highlight | ||
| else { | ||
| for (let i2 = i + 1; i2 < this.tagLocations.length; i2++) { | ||
| const tagLoc2 = this.tagLocations[i2]; | ||
| if (highlightLoc[1] < tagLoc2[0]) { | ||
| break; | ||
| } else { | ||
| const tag2 = this.originalContent.substring(tagLoc2[0] + tagLoc2[2], tagLoc2[0] + tagLoc2[2] + tagLoc2[1]); | ||
| if (tag2.startsWith('<' + tagName)) { | ||
| requiredTagNumber++; | ||
| } else if (tag2.startsWith('</' + tagName)) { | ||
| requiredTagCount++; | ||
| } | ||
| if (requiredTagNumber === requiredTagCount) { | ||
| included = true; | ||
| break; | ||
| } | ||
| } | ||
| } | ||
| } | ||
| return included; | ||
| } | ||
| adjustLoc(highlightTagName = 'span', highlightIdPattern, highlightIndex, highlightClass) { | ||
| const highlightLoc = this.highlights[highlightIndex].loc; | ||
| const locInc = [0, 0]; // step 1: check locations of tags | ||
| const length = this.tagLocations.length; | ||
| for (let i = 0; i < length; i++) { | ||
| const tagLoc = this.tagLocations[i]; // start end tag | ||
| if (highlightLoc[1] < tagLoc[0]) { | ||
| break; | ||
| } // start end&tag | ||
| else if (highlightLoc[1] === tagLoc[0]) { | ||
| const tag = this.originalContent.substring(tagLoc[0] + tagLoc[2], tagLoc[0] + tagLoc[2] + tagLoc[1]); // if end tag, not block element and include the required close tag, add right to the tag | ||
| if (!tag.endsWith('/>') && tag.startsWith('</') && !blockElements.includes(tag.split('</')[1].split('>')[0]) && this.includeRequiredTag(i, highlightLoc, tag)) { | ||
| locInc[1] += tagLoc[1]; | ||
| } | ||
| } // start tag end | ||
| else if (highlightLoc[1] > tagLoc[0]) { | ||
| locInc[1] += tagLoc[1]; // start&tag end | ||
| if (highlightLoc[0] === tagLoc[0]) { | ||
| const tag = this.originalContent.substring(tagLoc[0] + tagLoc[2], tagLoc[0] + tagLoc[2] + tagLoc[1]); // if self close tag or end tag or block element or not include the required close tag, add right to the tag | ||
| if (tag.startsWith('</') || tag.endsWith('/>') || blockElements.includes(tag.split(' ')[0].split('<')[1].split('>')[0]) || !this.includeRequiredTag(i, highlightLoc, tag)) { | ||
| locInc[0] += tagLoc[1]; | ||
| } | ||
| } // tag start end | ||
| else if (highlightLoc[0] > tagLoc[0]) { | ||
| locInc[0] += tagLoc[1]; | ||
| } | ||
| } | ||
| } // step 2: check locations of other highlights | ||
| // all span (no blocks) | ||
| // stored in a different array than tags | ||
| // can intersect | ||
| for (let i = 0; i < this.highlights.length; i++) { | ||
| const highlight = this.highlights[i]; // only check the highlighted | ||
| if (highlight.highlighted) { | ||
| const openTagLength = TextAnnotator.getOpenTagLength(highlightTagName, highlightIdPattern, i, highlightClass); | ||
| const closeTagLength = TextAnnotator.getCloseTagLength(highlightTagName); | ||
| const loc = highlight.loc; | ||
| if (highlightLoc[0] >= loc[1]) { | ||
| locInc[0] += openTagLength + closeTagLength; | ||
| locInc[1] += openTagLength + closeTagLength; | ||
| } // syntactical correct but semantical incorrect | ||
| else if (highlightLoc[0] < loc[1] && highlightLoc[0] > loc[0] && highlightLoc[1] > loc[1]) { | ||
| locInc[0] += openTagLength; | ||
| locInc[1] += openTagLength + closeTagLength; | ||
| } else if (highlightLoc[0] <= loc[0] && highlightLoc[1] >= loc[1]) { | ||
| locInc[1] += openTagLength + closeTagLength; | ||
| } // syntactical correct but semantical incorrect | ||
| else if (highlightLoc[0] < loc[0] && highlightLoc[1] > loc[0] && highlightLoc[1] < loc[1]) { | ||
| locInc[1] += openTagLength; | ||
| } else if (highlightLoc[0] >= loc[0] && highlightLoc[1] <= loc[1]) { | ||
| locInc[0] += openTagLength; | ||
| locInc[1] += openTagLength; | ||
| } | ||
| } | ||
| this.html = this.html.slice(0, annotator.index + indexInc) + this.html.slice(annotator.index + indexInc + annotator.length); | ||
| this.tags.splice(annotatorIndexesInTags[i] - i, 1); | ||
| } | ||
| return [highlightLoc[0] + locInc[0], highlightLoc[1] + locInc[1]]; | ||
| return this.html; | ||
| } | ||
| static createOpenTag(highlightTagName = 'span', highlightIdPattern, highlightIndex, highlightClass) { | ||
| return `<${highlightTagName} id="${highlightIdPattern + highlightIndex}" class="${highlightClass}">`; | ||
| } | ||
| unannotateAll(annotationIndexes) { | ||
| annotationIndexes.forEach(annotationIndex => { | ||
| this.unannotate(annotationIndex); | ||
| }); | ||
| return this.html; | ||
| } // pure function | ||
| static createCloseTag(highlightTagName = 'span') { | ||
| return `</${highlightTagName}>`; | ||
| } | ||
| static getOpenTagLength(highlightTagName = 'span', highlightIdPattern, highlightIndex, highlightClass) { | ||
| return TextAnnotator.createOpenTag(highlightTagName, highlightIdPattern, highlightIndex, highlightClass).length; | ||
| } | ||
| _stripHTMLTags(html) { | ||
| let text = html; | ||
| const tags = []; | ||
| let tag; | ||
| const tagRegEx = /<[^>]+>/; | ||
| static getCloseTagLength(highlightTagName = 'span') { | ||
| return TextAnnotator.createCloseTag(highlightTagName).length; | ||
| } | ||
| static trim(prefix, str, postfix) { | ||
| prefix = prefix.replace(/^\s+/, ''); | ||
| postfix = postfix.replace(/\s+$/, ''); | ||
| if (!prefix) { | ||
| str = str.replace(/^\s+/, ''); | ||
| while (tag = text.match(tagRegEx)) { | ||
| text = text.replace(tag, ''); | ||
| tags.push({ | ||
| index: tag.index, | ||
| length: tag[0].length, | ||
| isCloseTag: tag[0].startsWith('</') | ||
| }); | ||
| } | ||
| if (!postfix) { | ||
| str = str.replace(/\s+$/, ''); | ||
| } | ||
| return { | ||
| prefix, | ||
| str, | ||
| postfix | ||
| text, | ||
| tags | ||
| }; | ||
| } | ||
| } // pure function | ||
| static insert(str1, str2, index) { | ||
| _insert(str1, str2, index) { | ||
| return str1.slice(0, index) + str2 + str1.slice(index); | ||
| } | ||
| } // pure function | ||
| static sentenize(text) { | ||
| const options = { | ||
| newline_boundaries: false, | ||
| html_boundaries: false, | ||
| sanitize: false, | ||
| allowed_tags: false, | ||
| preserve_whitespace: true, | ||
| abbreviations: null | ||
| }; | ||
| return (0, _sbd.default)(text, options).map(raw => { | ||
| // future work: can tokenizer return location directly | ||
| const index = text.indexOf(raw); | ||
| return { | ||
| raw, | ||
| index | ||
| }; | ||
| }); | ||
| } | ||
| static getBestSubstring(str, substr, threshold, lenRatio, caseSensitive, skipFirstRun) { | ||
| let result = {}; | ||
| let similarity = skipFirstRun ? threshold : TextAnnotator.getSimilarity(str, substr, caseSensitive); | ||
| if (similarity >= threshold) { | ||
| // step 1: derive best substr | ||
| // future work: /s may be better | ||
| const words = str.split(' '); | ||
| while (words.length) { | ||
| const firstWord = words.shift(); | ||
| const newStr = words.join(' '); | ||
| let newSimilarity = TextAnnotator.getSimilarity(newStr, substr, caseSensitive); | ||
| if (newSimilarity < similarity) { | ||
| words.unshift(firstWord); | ||
| const lastWord = words.pop(); | ||
| newSimilarity = TextAnnotator.getSimilarity(words.join(' '), substr, caseSensitive); | ||
| if (newSimilarity < similarity) { | ||
| words.push(lastWord); | ||
| break; | ||
| } else { | ||
| similarity = newSimilarity; | ||
| } | ||
| } else { | ||
| similarity = newSimilarity; | ||
| } | ||
| } | ||
| const bestSubstr = words.join(' '); // step 2: return the best substr and its loc if found and if it meets the threshold and the length ratio | ||
| if (!lenRatio || bestSubstr.length / substr.length <= lenRatio) { | ||
| const loc = []; | ||
| loc[0] = str.indexOf(bestSubstr); | ||
| loc[1] = loc[0] + bestSubstr.length; | ||
| result = { | ||
| similarity, | ||
| loc | ||
| }; | ||
| } | ||
| _binaryInsert(arr, val, comparator) { | ||
| if (arr.length === 0 || comparator(arr[0], val) >= 0) { | ||
| arr.splice(0, 0, val); | ||
| return arr; | ||
| } else if (arr.length > 0 && comparator(arr[arr.length - 1], val) <= 0) { | ||
| arr.splice(arr.length, 0, val); | ||
| return arr; | ||
| } | ||
| return result; | ||
| } | ||
| let left = 0, | ||
| right = arr.length; | ||
| let leftLast = 0, | ||
| rightLast = right; | ||
| static getSimilarity(str1, str2, caseSensitive) { | ||
| if (!caseSensitive) { | ||
| str1 = str1.toLowerCase(); | ||
| str2 = str2.toLowerCase(); | ||
| } | ||
| while (left < right) { | ||
| const inPos = Math.floor((right + left) / 2); | ||
| const compared = comparator(arr[inPos], val); | ||
| if (str1 === str2) return 1; // set str2 to denominator | ||
| return TextAnnotator.lcsLength(str1, str2) / str2.length; | ||
| } // copy from the code in https://www.npmjs.com/package/longest-common-subsequence | ||
| static lcsLength(firstSequence, secondSequence, caseSensitive) { | ||
| function createArray(dimension) { | ||
| const array = []; | ||
| for (let i = 0; i < dimension; i++) { | ||
| array[i] = []; | ||
| if (compared < 0) { | ||
| left = inPos; | ||
| } else if (compared > 0) { | ||
| right = inPos; | ||
| } else { | ||
| right = inPos; | ||
| left = inPos; | ||
| } | ||
| return array; | ||
| } | ||
| const firstString = caseSensitive ? firstSequence : firstSequence.toLowerCase(); | ||
| const secondString = caseSensitive ? secondSequence : secondSequence.toLowerCase(); | ||
| if (firstString === secondString) { | ||
| return firstString.length; | ||
| } | ||
| if ((firstString || secondString) === '') { | ||
| return ''.length; | ||
| } | ||
| const firstStringLength = firstString.length; | ||
| const secondStringLength = secondString.length; | ||
| const lcsMatrix = createArray(secondStringLength + 1); | ||
| let i; | ||
| let j; | ||
| for (i = 0; i <= firstStringLength; i++) { | ||
| lcsMatrix[0][i] = 0; | ||
| } | ||
| for (i = 0; i <= secondStringLength; i++) { | ||
| lcsMatrix[i][0] = 0; | ||
| } | ||
| for (i = 1; i <= secondStringLength; i++) { | ||
| for (j = 1; j <= firstStringLength; j++) { | ||
| if (firstString[j - 1] === secondString[i - 1]) { | ||
| lcsMatrix[i][j] = lcsMatrix[i - 1][j - 1] + 1; | ||
| } else { | ||
| lcsMatrix[i][j] = Math.max(lcsMatrix[i - 1][j], lcsMatrix[i][j - 1]); | ||
| } | ||
| if (leftLast === left && rightLast === right) { | ||
| break; | ||
| } | ||
| } | ||
| let lcs = ''; | ||
| i = secondStringLength; | ||
| j = firstStringLength; | ||
| while (i > 0 && j > 0) { | ||
| if (firstString[j - 1] === secondString[i - 1]) { | ||
| lcs = firstString[j - 1] + lcs; | ||
| i--; | ||
| j--; | ||
| } else if (Math.max(lcsMatrix[i - 1][j], lcsMatrix[i][j - 1]) === lcsMatrix[i - 1][j]) { | ||
| i--; | ||
| } else { | ||
| j--; | ||
| } | ||
| leftLast = left; | ||
| rightLast = right; | ||
| } | ||
| return lcs.length; | ||
| arr.splice(right, 0, val); | ||
| return arr; | ||
| } | ||
@@ -730,0 +273,0 @@ |
| { | ||
| "name": "text-annotator", | ||
| "version": "0.8.8", | ||
| "version": "1.0.0", | ||
| "description": "A JavaScript library for locating and annotating plain text in HTML", | ||
@@ -34,3 +34,2 @@ "main": "build/text-annotator.js", | ||
| "babel-jest": "^26.6.3", | ||
| "dotenv": "^8.0.0", | ||
| "eslint": "^7.21.0", | ||
@@ -44,2 +43,3 @@ "eslint-config-prettier": "^8.1.0", | ||
| "sync-directory": "^2.2.17", | ||
| "typescript": "^4.3.2", | ||
| "webpack": "^4.46.0", | ||
@@ -90,6 +90,3 @@ "webpack-cli": "^3.3.12" | ||
| "test" | ||
| ], | ||
| "dependencies": { | ||
| "html-entities": "^2.1.0" | ||
| } | ||
| ] | ||
| } |
105
README.md
@@ -1,2 +0,2 @@ | ||
| # text-annotator | ||
| # text-annotator-v2 | ||
| A JavaScript library for annotating plain text in the HTML<br /> | ||
@@ -6,10 +6,11 @@ The annotation process is: | ||
| 2. **Annotate**: Annotate the found text given its index<br /> | ||
| It can be seen that in order to annotate a piece of text, two steps, **search** and **annotate**, are taken. The idea of decomposing the annotation process into the two steps is to allow more flexibility, e.g., the user can search for all pieces of text first, and then annotate (some of) them later when required (e.g., when clicking a button). There is also a function combining the two steps, as can be seen in the **An example of the usage** section.<br /> | ||
| *text-annotator* can be used in the browser or the Node.js server. | ||
| It can be seen that in order to annotate a piece of text, two steps, **search** and **annotate**, are taken. The idea of decomposing the annotation process into the two steps is to allow more flexibility, e.g., the user can search for all pieces of text first, and then annotate (some of) them later when required (e.g., when clicking a button). <br /> | ||
| *text-annotator-v2* can be used in the browser or the Node.js server.<br /> | ||
| *text-annotator-v2* evolved from [text-annotator](https://www.npmjs.com/package/text-annotator). See *Comparing text-annotator-v2 and text-annotator* at the end of this document. | ||
| ## Import | ||
| ### install it via npm | ||
| `npm install --save text-annotator` | ||
| `npm install --save text-annotator-v2` | ||
| ```javascript | ||
| import TextAnnotator from 'text-annotator' | ||
| import TextAnnotator from 'text-annotator-v2' | ||
| ``` | ||
@@ -23,58 +24,34 @@ ### include it into the head tag | ||
| ```javascript | ||
| // below is the HTML | ||
| // <div id="content"><p><b>Europe PMC</b> is an <i>open science platform</i> that enables access to a worldwide collection of life science publications and preprints from trusted sources around the globe.</p></p>Europe PMC is <i>developed by <b>EMBL-EBI</b></i>. It is a partner of <b>PubMed Central</b> and a repository of choice for many international science funders.</p></div> | ||
| /* | ||
| below is the HTML | ||
| <div id="content"><p><i>JavaScript</i> is the <b>world's most popular programming language</b>.</p><p><i>JavaScript</i> is the programming language of the Web. JavaScript is easy to learn.</p></div> | ||
| */ | ||
| // create an instance of TextAnnotator | ||
| // content is the HTML string within which a piece of text can be annotated | ||
| var annotator = new TextAnnotator({content: document.getElementById('content').innerHTML}) | ||
| // create an instance of TextAnnotator by passing the html to be annotated | ||
| var annotator = new TextAnnotator(document.getElementById('content').innerHTML) | ||
| // search for 'EMBL-EBI' in the HTML | ||
| // if found, store the location of 'EMBL-EBI' and then return the index; otherwise return -1 | ||
| var highlightIndex = annotator.search('EMBL-EBI') | ||
| // highlightIndex = 0 | ||
| // annotate 'EMBL-EBI' in the HTML | ||
| if (highlightIndex !== -1) { | ||
| document.getElementById('content').innerHTML = annotator.highlight(highlightIndex) | ||
| // <span id="highlight-0" class="highlight"> is used to annotate 'EMBL-EBI', see below | ||
| // <div id="content"><p><b>Europe PMC</b> is an <i>open science platform</i> that enables access to a worldwide collection of life science publications and preprints from trusted sources around the globe.</p></p>Europe PMC is <i>developed by <span id="highlight-0" class="highlight"><b>EMBL-EBI</b></span></i>. It is a partner of <b>PubMed Central</b> and a repository of choice for many international science funders.</p></div> | ||
| // search for text "JavaScript is the world's most popular programming language.JavaScript is the programming language of the Web." within the HTML | ||
| var annotationIndex = annotator.search('JavaScript is the world\'s most popular programming language.JavaScript is the programming language of the Web.') | ||
| // annotate the text if finding it | ||
| if (annotationIndex !== -1) { | ||
| document.getElementById('content').innerHTML = annotator.annotate(annotationIndex) | ||
| } | ||
| // search for all occurances of 'Europe PMC' in the HTML | ||
| var highlightIndexes = annotator.searchAll('Europe PMC') | ||
| // highlightIndexes = [1, 2] | ||
| // annotate all the found occurances of 'Europe PMC' given their indexes | ||
| if (highlightIndexes.length) { | ||
| document.getElementById('content').innerHTML = annotator.highlightAll(highlightIndexes) | ||
| // <span id="highlight-1" class="highlight"> and <span id="highlight-2" class="highlight"> are used to annotate 'Europe PMC', see below | ||
| // <div id="content"><p><span id="highlight-1" class="highlight"><b>Europe PMC</b><span> is an <i>open science platform</i> that enables access to a worldwide collection of life science publications and preprints from trusted sources around the globe.</p><p><span id="highlight-2" class="highlight">Europe PMC</span> is <i>developed by <span id="highlight-0" class="highlight"><b>EMBL-EBI</b></span></i>. It is a partner of <b>PubMed Central</b> and a repository of choice for many international science funders.</p></div> | ||
| // search for all occurances of "JavaScript" in the HTML | ||
| var annotationIndexes = annotator.searchAll('JavaScript') | ||
| // annotate all the found occurances of 'Javascript' given their indexes | ||
| if (annotationIndexes.length) { | ||
| document.getElementById('content').innerHTML = annotator.annotateAll(annotationIndexes) | ||
| } | ||
| // search for and then annotate 'a partner of PubMed Central' | ||
| document.getElementById('content').innerHTML = annotator.searchAndHighlight('a partner of PubMed Central').content | ||
| // searchAndHighlight returns { content, highlightIndex } | ||
| // <span id="highlight-3" class="highlight"> is used to annotate 'a partner of PubMed Central', see below | ||
| // <div id="content"><p><span id="highlight-1" class="highlight"><b>Europe PMC</b><span> is an <i>open science platform</i> that enables access to a worldwide collection of life science publications and preprints from trusted sources around the globe.</p><p><span id="highlight-2" class="highlight">Europe PMC</span> is <i>developed by <span id="highlight-0" class="highlight"><b>EMBL-EBI</b></span></i>. It is <span id="highlight-3" class="highlight">a partner of <b>PubMed Central</b></span> and a repository of choice for many international science funders.</p></div> | ||
| // remove annotation 'EMBL-EBI' given its index | ||
| // the index is 0 as shown above | ||
| document.getElementById('content').innerHTML = annotator.unhighlight(highlightIndex) | ||
| // annotation <span id="highlight-0" class="highlight"> is removed, see below | ||
| // <div id="content"><p><span id="highlight-1" class="highlight"><b>Europe PMC</b><span> is an <i>open science platform</i> that enables access to a worldwide collection of life science publications and preprints from trusted sources around the globe.</p><p><span id="highlight-2" class="highlight">Europe PMC</span> is <i>developed by <b>EMBL-EBI</b></i>. It is <span id="highlight-3" class="highlight">a partner of <b>PubMed Central</b></span> and a repository of choice for many international science funders.</p></div> | ||
| // help annotate one occurance of 'science' - the one within 'international science funders', by providing the prefix and postfix of 'Europe PMC' | ||
| var highlightIndex = annotator.search('science', { prefix: 'international ', postfix: ' funders' }) | ||
| if (highlightIndex !== -1) { | ||
| document.getElementById('content').innerHTML = annotator.highlight(highlightIndex) | ||
| } | ||
| // <span id="highlight-4" class="highlight"> is used to annotate 'science' within 'international science funders', see below | ||
| // <div id="content"><p><span id="highlight-1" class="highlight"><b>Europe PMC</b><span> is an <i>open science platform</i> that enables access to a worldwide collection of life science publications and preprints from trusted sources around the globe.</p><p><span id="highlight-2" class="highlight">Europe PMC</span> is <i>developed by <b>EMBL-EBI</b></i>. It is <span id="highlight-3" class="highlight">a partner of <b>PubMed Central</b></span> and a repository of choice for many international <span id="highlight-4" class="highlight">science</span> funders.</p></div> | ||
| // unannotate all the previously annotated text | ||
| document.getElementById('content').innerHTML = annotator.unannotate(annotationIndex) | ||
| document.getElementById('content').innerHTML = annotator.unannotateAll(annotationIndexes) | ||
| ``` | ||
| ## Constructor options | ||
| #### new TextAnnotator(*options*) | ||
| #### new TextAnnotator(html) | ||
| | Prop | Type | Description | | ||
| | ---- | ---- | ---- | | ||
| | content | string | The HTML string within which a piece of text can be annotated. | | ||
| | html | string | The HTML string within which a piece of text can be annotated. | | ||
@@ -92,26 +69,16 @@ ## Search options | ||
| ## Annotate options | ||
| #### highlight(highlightIndex, *options*) | ||
| #### highlightAll(highlightIndexes, *options*) | ||
| #### unhighlight(highlightIndex, *options*) | ||
| #### annotate(annotationIndex, *options*) | ||
| #### annotationAll(annotationIndexes, *options*) | ||
| #### unannotate(annotationIndex) | ||
| #### unannotateAll(annotationIndexes) | ||
| | Prop | Type | Description | | ||
| | ---- | ---- | ---- | | ||
| | highlightTagName | string | The name of the annotation tag. Default is *span* so that the tag is *<span ...>*. | | ||
| | highlightClass | string | The class name of the annotation tag. Default is *highlight* so that the tag is *<span class="highlight" ...>*. | | ||
| | highlightIdPattern | string | The ID pattern of the annotation tag. Default is *highlight-* so that the tag is *<span id="highlight-[highlightIndex]" ...>*. | | ||
| | tagName | string | The tag name of the annotation tag. Default is *span* so that the tag is *<span ...>*. | | ||
| | baseClassName | string | The base class name of the annotation tag. Default is *annotation* so that the tag is *<span class="annotation" ...>*. | | ||
| | classPattern | string | The pattern of the class used as the ID of the annotation. Default is *annotation-* so that the tag is *<span class="annotation-[annotation]" ...>*. | | ||
| ## searchAndHighlight options | ||
| *searchAndHighlight(str, **options**)*, where *options = { searchOptions, highlightOptions }*, *searchOptions* and *highlightOptions* are described above in the Annotate options table. | ||
| ## Comparing text-annotator-v2 and text-annotator | ||
| TBC | ||
| ## Examples from Europe PMC | ||
| text-annotator has been widely used in [Europe PMC](https://europepmc.org "Europe PMC"), an open science platform that enables access to a worldwide collection of life science publications. Here is a list of examples: | ||
| 1. Article title highlighting: https://europepmc.org/search?query=cancer | ||
| 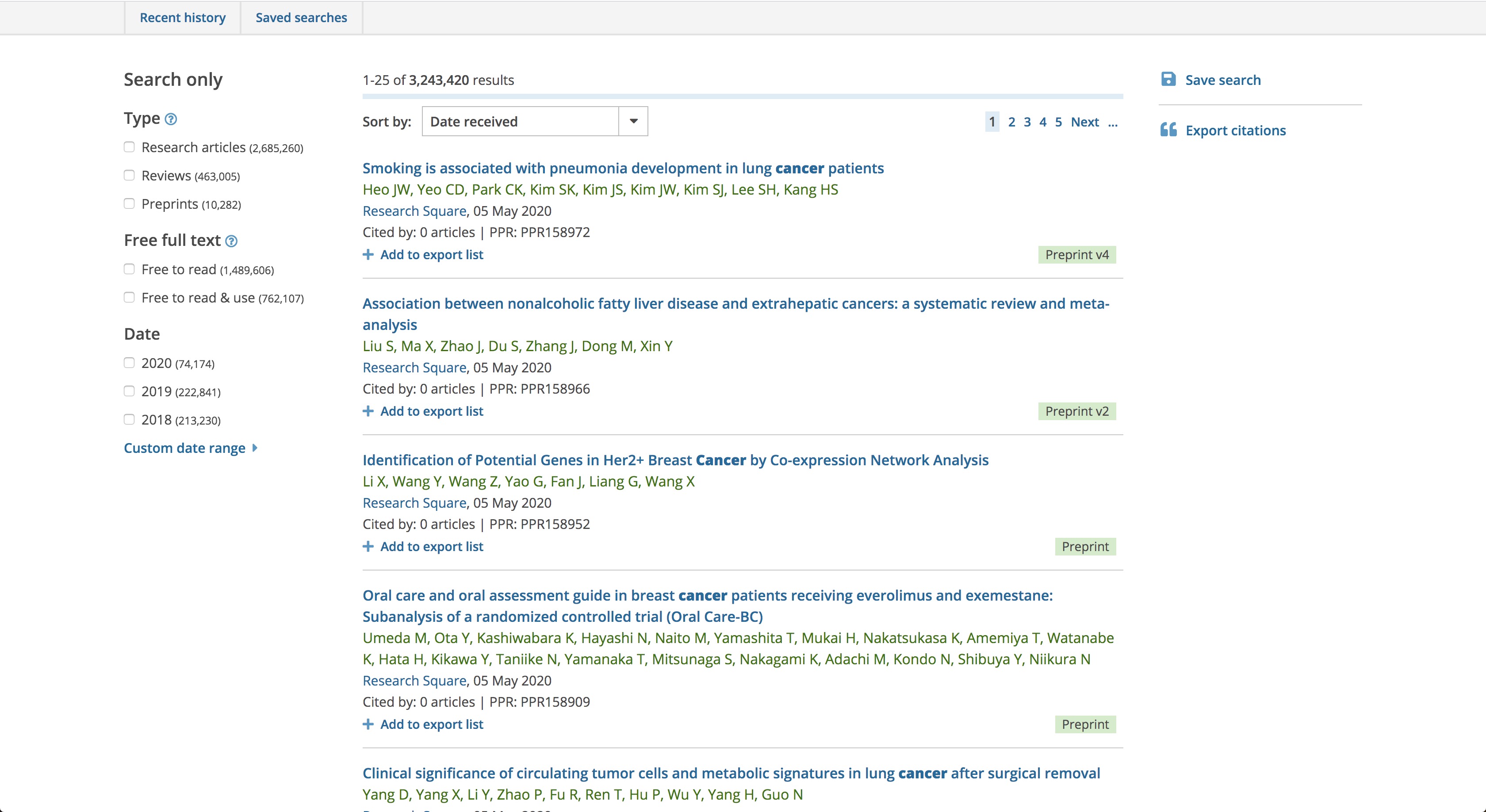 | ||
| 2. Snippets: https://europepmc.org/article/PPR/PPR158972 (Visit from https://europepmc.org/search?query=cancer) | ||
|  | ||
| 3. SciLite: https://europepmc.org/article/PPR/PPR158972 (Click the Annotations link in the right panel) | ||
|  | ||
| 4. Linkback: https://europepmc.org/article/PPR/PPR158972#europepmc-6e6312219dcad15c9a7dda8f71dce9af (In the popup shown in Example 3, click "Share" to get this linkback URL) | ||
|  | ||
| ## Contact | ||
| [Zhan Huang](mailto:z2hm@outlook.com "Zhan Huang") |
@@ -1,487 +0,201 @@ | ||
| import { encode } from 'html-entities' | ||
| import getSentences from './ext/sbd' | ||
| // div inside span is a bad idea | ||
| const blockElements = [ | ||
| 'address', | ||
| 'article', | ||
| 'aside', | ||
| 'blockquote', | ||
| 'canvas', | ||
| 'dd', | ||
| 'div', | ||
| 'dl', | ||
| 'dt', | ||
| 'fieldset', | ||
| 'figcaption', | ||
| 'figure', | ||
| 'footer', | ||
| 'form', | ||
| 'h1', | ||
| 'h2', | ||
| 'h3', | ||
| 'h4', | ||
| 'h5', | ||
| 'h6', | ||
| 'header', | ||
| 'hgroup', | ||
| 'hr', | ||
| 'li', | ||
| 'main', | ||
| 'nav', | ||
| 'noscript', | ||
| 'ol', | ||
| 'output', | ||
| 'p', | ||
| 'pre', | ||
| 'section', | ||
| 'table', | ||
| 'tfoot', | ||
| 'ul', | ||
| 'video', | ||
| ] | ||
| class TextAnnotator { | ||
| constructor(options = {}) { | ||
| const content = options.content | ||
| // isHTML is used to reduce the memory used: stripedHTML is empty if isHTML is false | ||
| const isHTML = options.isHTML === undefined || options.isHTML | ||
| // annotatedContent is introduced in order to avoid passing content in the methods | ||
| this.originalContent = this.annotatedContent = content | ||
| this.isHTML = isHTML | ||
| // stripedHTML and tagLocations are needed only when the content is HTML | ||
| this.stripedHTML = '' | ||
| this.tagLocations = [] | ||
| // sentences are used in sentence-based fuzzy search | ||
| this.sentences = [] | ||
| // future work: one highlight can have more than one location because of the potential issue in tag insertion | ||
| this.highlights = [] | ||
| if (isHTML) { | ||
| this.stripAndStoreHTMLTags() | ||
| } | ||
| constructor(html) { | ||
| this.html = html | ||
| const { text, tags } = this._stripHTMLTags(html) | ||
| this.text = text | ||
| // [{ index, length, isCloseTag, annotationIndex* }]; ordered by index | ||
| this.tags = tags | ||
| // [{ index, length }]; unordered | ||
| this.annotations = [] | ||
| } | ||
| // the order of directSearch => fuzzy search => eager search is tailored for specific feature, it is now the default way of search but it can be customized via options. More customizations can be done by composing functions | ||
| search(str, options = {}) { | ||
| let prefix = options.prefix || '' | ||
| let postfix = options.postfix || '' | ||
| const directSearchOptions = options.directSearchOptions || {} | ||
| const fuzzySearchOptions = options.fuzzySearchOptions | ||
| const eagerSearchOptions = options.eagerSearchOptions | ||
| // trim by default | ||
| const trim = options.trim === undefined || options.trim | ||
| // used unless overwritten | ||
| const caseSensitive = options.caseSensitive | ||
| search( | ||
| searchText, | ||
| { | ||
| prefix = '', | ||
| postfix = '', | ||
| trim = true, | ||
| caseSensitive = false, | ||
| offset = 0, | ||
| } = {} | ||
| ) { | ||
| const { text, annotations } = this | ||
| let str = prefix + searchText + postfix | ||
| str = trim ? str.trim() : str | ||
| str = caseSensitive ? str : str.toLowerCase() | ||
| if (trim) { | ||
| const res = TextAnnotator.trim(prefix, str, postfix) | ||
| prefix = res.prefix | ||
| str = res.str | ||
| postfix = res.postfix | ||
| } | ||
| let highlightIndex = -1 | ||
| // direct search will always be performed | ||
| highlightIndex = this.directSearch( | ||
| prefix, | ||
| const index = (caseSensitive ? text : text.toLowerCase()).indexOf( | ||
| str, | ||
| postfix, | ||
| Object.assign({ caseSensitive }, directSearchOptions) | ||
| offset | ||
| ) | ||
| if (highlightIndex !== -1) { | ||
| return highlightIndex | ||
| } | ||
| // experimental feature | ||
| if (fuzzySearchOptions) { | ||
| highlightIndex = this.fuzzySearch( | ||
| prefix, | ||
| str, | ||
| postfix, | ||
| Object.assign({ caseSensitive }, fuzzySearchOptions) | ||
| ) | ||
| if (highlightIndex !== -1) { | ||
| return highlightIndex | ||
| } | ||
| } | ||
| const prefixLength = trim | ||
| ? prefix.replace(/^\s+/, '').length | ||
| : prefix.length | ||
| const postfixLength = trim | ||
| ? postfix.replace(/\s+$/, '').length | ||
| : postfix.length | ||
| return index === -1 | ||
| ? -1 | ||
| : annotations.push({ | ||
| index: index + prefixLength, | ||
| length: str.substring(prefixLength, str.length - postfixLength) | ||
| .length, | ||
| }) - 1 | ||
| } | ||
| // experimental feature | ||
| // eager search only works in (particular) browsers | ||
| if (eagerSearchOptions) { | ||
| highlightIndex = this.eagerSearch( | ||
| prefix, | ||
| str, | ||
| postfix, | ||
| Object.assign({ caseSensitive }, eagerSearchOptions) | ||
| ) | ||
| if (highlightIndex !== -1) { | ||
| return highlightIndex | ||
| searchAll(searchText, options) { | ||
| let offset = 0 | ||
| const annotationIndexes = [] | ||
| let annotationIndex = -1 | ||
| // do not mutate param | ||
| const newOptions = Object.assign({}, options) | ||
| do { | ||
| annotationIndex = this.search(searchText, newOptions) | ||
| if (annotationIndex !== -1) { | ||
| offset = this.annotations[annotationIndex].index + 1 | ||
| newOptions.offset = offset | ||
| annotationIndexes.push(annotationIndex) | ||
| } | ||
| } | ||
| return highlightIndex | ||
| } while (annotationIndex !== -1) | ||
| return annotationIndexes | ||
| } | ||
| // experimental feature | ||
| // only support direct search for now | ||
| searchAll(str, options = {}) { | ||
| const highlightIndexes = [] | ||
| annotate( | ||
| annotationIndex, | ||
| { | ||
| tagName = 'span', | ||
| baseClassName = 'annotation', | ||
| classPattern = 'annotation-', | ||
| } = {} | ||
| ) { | ||
| const { tags, annotations, _insert, _binaryInsert } = this | ||
| const annotation = annotations[annotationIndex] | ||
| // [start, end, offset] | ||
| const annotationLocation = [ | ||
| annotation.index, | ||
| annotation.index + annotation.length, | ||
| 0, | ||
| ] | ||
| const continueSearch = (str, options) => { | ||
| const highlightIndex = this.search(str, options) | ||
| if (highlightIndex !== -1) { | ||
| highlightIndexes.push(highlightIndex) | ||
| options.directSearchOptions = options.directSearchOptions || {} | ||
| options.directSearchOptions.lastHighlightIndex = highlightIndex | ||
| continueSearch(str, options) | ||
| // partition | ||
| const annotatorLocations = [[...annotationLocation]] | ||
| for (let i = 0; i < tags.length; i++) { | ||
| const { index: tagIndex, length: tagLength } = tags[i] | ||
| if (tagIndex <= annotationLocation[0]) { | ||
| annotatorLocations[0][2] += tagLength | ||
| } else if (tagIndex < annotationLocation[1]) { | ||
| const lastTagIndex = i === 0 ? 0 : tags[i - 1].index | ||
| const lastAnnotatorLocation = | ||
| annotatorLocations[annotatorLocations.length - 1] | ||
| if (tagIndex === lastTagIndex) { | ||
| lastAnnotatorLocation[2] += tagLength | ||
| } else { | ||
| const annotatorLocationEnd = lastAnnotatorLocation[1] | ||
| lastAnnotatorLocation[1] = tagIndex | ||
| annotatorLocations.push([ | ||
| lastAnnotatorLocation[1], | ||
| annotatorLocationEnd, | ||
| lastAnnotatorLocation[2] + tagLength, | ||
| ]) | ||
| } | ||
| } else { | ||
| break | ||
| } | ||
| } | ||
| continueSearch(str, options) | ||
| // insert annotator tags into tag list and html | ||
| const annotatorOpenTag = `<${tagName} class="${baseClassName} ${classPattern}${annotationIndex}">` | ||
| const annotatorCloseTag = `</${tagName}>` | ||
| const annotatorOpenTagLength = annotatorOpenTag.length | ||
| const annotatorCloseTagLength = annotatorCloseTag.length | ||
| let locInc = 0 | ||
| for (let i = 0; i < annotatorLocations.length; i++) { | ||
| const annotatorLocation = annotatorLocations[i] | ||
| _binaryInsert( | ||
| tags, | ||
| { | ||
| index: annotatorLocation[0], | ||
| length: annotatorOpenTagLength, | ||
| isCloseTag: false, | ||
| annotationIndex, | ||
| }, | ||
| (a, b) => { | ||
| return a.index <= b.index ? -1 : 1 | ||
| } | ||
| ) | ||
| _binaryInsert( | ||
| tags, | ||
| { | ||
| index: annotatorLocation[1], | ||
| length: annotatorCloseTagLength, | ||
| isCloseTag: true, | ||
| annotationIndex, | ||
| }, | ||
| (a, b) => a.index - b.index | ||
| ) | ||
| return highlightIndexes | ||
| } | ||
| this.html = _insert( | ||
| this.html, | ||
| annotatorOpenTag, | ||
| annotatorLocation[0] + annotatorLocation[2] + locInc | ||
| ) | ||
| this.html = _insert( | ||
| this.html, | ||
| annotatorCloseTag, | ||
| annotatorLocation[1] + | ||
| annotatorLocation[2] + | ||
| locInc + | ||
| annotatorOpenTagLength | ||
| ) | ||
| locInc += annotatorOpenTagLength + annotatorCloseTagLength | ||
| } | ||
| highlight(highlightIndex, options = {}) { | ||
| const highlightTagName = options.highlightTagName || 'span' | ||
| const highlightClass = options.highlightClass || 'highlight' | ||
| const highlightIdPattern = options.highlightIdPattern || 'highlight-' | ||
| const openTag = TextAnnotator.createOpenTag( | ||
| highlightTagName, | ||
| highlightIdPattern, | ||
| highlightIndex, | ||
| highlightClass | ||
| ) | ||
| const loc = this.adjustLoc( | ||
| highlightTagName, | ||
| highlightIdPattern, | ||
| highlightIndex, | ||
| highlightClass | ||
| ) | ||
| this.annotatedContent = TextAnnotator.insert( | ||
| this.annotatedContent, | ||
| openTag, | ||
| loc[0] | ||
| ) | ||
| this.annotatedContent = TextAnnotator.insert( | ||
| this.annotatedContent, | ||
| TextAnnotator.createCloseTag(highlightTagName), | ||
| loc[1] + openTag.length | ||
| ) | ||
| // it has to be set after adjustLoc so that it will not be checked | ||
| this.highlights[highlightIndex].highlighted = true | ||
| return this.annotatedContent | ||
| return this.html | ||
| } | ||
| // experimental feature | ||
| highlightAll(highlightIndexes, options = {}) { | ||
| for (let i = 0; i < highlightIndexes.length; i++) { | ||
| this.annotatedContent = this.highlight(highlightIndexes[i], options) | ||
| } | ||
| return this.annotatedContent | ||
| annotateAll(annotationIndexes, options) { | ||
| annotationIndexes.forEach((annotationIndex) => { | ||
| this.annotate(annotationIndex, options) | ||
| }) | ||
| return this.html | ||
| } | ||
| searchAndHighlight(str, options = {}) { | ||
| const highlightIndex = this.search(str, options.searchOptions) | ||
| if (highlightIndex !== -1) { | ||
| return { | ||
| highlightIndex, | ||
| content: this.highlight(highlightIndex, options.highlightOptions), | ||
| unannotate(annotationIndex) { | ||
| // annotatorIndexesInTags amd annotators have the same size | ||
| const annotatorIndexesInTags = [] | ||
| const annotators = this.tags.filter((tag, index) => { | ||
| if (tag.annotationIndex === annotationIndex) { | ||
| annotatorIndexesInTags.push(index) | ||
| } | ||
| } | ||
| } | ||
| unhighlight(highlightIndex, options = {}) { | ||
| const highlightTagName = options.highlightTagName || 'span' | ||
| const highlightClass = options.highlightClass || 'highlight' | ||
| const highlightIdPattern = options.highlightIdPattern || 'highlight-' | ||
| // it has to be set before adjustLoc so that it will not be checked | ||
| this.highlights[highlightIndex].highlighted = false | ||
| // need to change when one annotation => more than one highlight | ||
| const loc = this.adjustLoc( | ||
| highlightTagName, | ||
| highlightIdPattern, | ||
| highlightIndex, | ||
| highlightClass | ||
| return tag.annotationIndex === annotationIndex | ||
| }) | ||
| const otherTags = this.tags.filter( | ||
| (tag) => tag.annotationIndex !== annotationIndex | ||
| ) | ||
| const openTagLength = TextAnnotator.getOpenTagLength( | ||
| highlightTagName, | ||
| highlightIdPattern, | ||
| highlightIndex, | ||
| highlightClass | ||
| ) | ||
| const substr1 = this.annotatedContent.substring( | ||
| loc[0], | ||
| loc[1] + openTagLength + TextAnnotator.getCloseTagLength(highlightTagName) | ||
| ) | ||
| const substr2 = this.annotatedContent.substring( | ||
| loc[0] + openTagLength, | ||
| loc[1] + openTagLength | ||
| ) | ||
| this.annotatedContent = this.annotatedContent.replace(substr1, substr2) | ||
| return this.annotatedContent | ||
| } | ||
| stripAndStoreHTMLTags() { | ||
| let tag | ||
| this.stripedHTML = this.originalContent | ||
| const tagRegEx = /<[^>]+>/ | ||
| let indexInc = 0 | ||
| while ((tag = this.stripedHTML.match(tagRegEx))) { | ||
| this.stripedHTML = this.stripedHTML.replace(tag, '') | ||
| const tagLength = tag[0].length | ||
| // tagLocations will be used in adjustLoc | ||
| this.tagLocations.push([tag.index, tagLength, indexInc]) | ||
| indexInc += tagLength | ||
| } | ||
| } | ||
| directSearch(prefix, str, postfix, directSearchOptions = {}) { | ||
| const caseSensitive = directSearchOptions.caseSensitive | ||
| // experimental option; used for specific feature | ||
| const ifEncode = directSearchOptions.encode | ||
| const lastHighlightIndex = directSearchOptions.lastHighlightIndex | ||
| let strWithFixes = prefix + str + postfix | ||
| let text = this.isHTML ? this.stripedHTML : this.originalContent | ||
| if (!caseSensitive) { | ||
| strWithFixes = strWithFixes.toLowerCase() | ||
| text = text.toLowerCase() | ||
| } | ||
| // for searchAll | ||
| let offset = 0 | ||
| if (lastHighlightIndex !== undefined) { | ||
| offset = this.highlights[lastHighlightIndex].loc[1] + 1 | ||
| } | ||
| let highlightIndex = -1 | ||
| const index = text.indexOf(strWithFixes, offset) | ||
| // experimental feature: if the text to be searched does not work, try to encode it | ||
| if (ifEncode && index === -1) { | ||
| const encodedStrWithFixes = encode(strWithFixes) | ||
| const index = text.indexOf(encodedStrWithFixes, offset) | ||
| if (index !== -1) { | ||
| const loc = [] | ||
| loc[0] = index + encode(prefix).length | ||
| loc[1] = loc[0] + encode(str).length | ||
| highlightIndex = this.highlights.push({ loc }) - 1 | ||
| } | ||
| } else if (index !== -1) { | ||
| const loc = [] | ||
| loc[0] = index + prefix.length | ||
| loc[1] = loc[0] + str.length | ||
| highlightIndex = this.highlights.push({ loc }) - 1 | ||
| } | ||
| return highlightIndex | ||
| } | ||
| eagerSearch(prefix, str, postfix, eagerSearchOptions = {}) { | ||
| const caseSensitive = eagerSearchOptions.caseSensitive | ||
| const containerId = eagerSearchOptions.containerId | ||
| const threshold = eagerSearchOptions.threshold || 0.74 | ||
| const strWithFixes = prefix + str + postfix | ||
| let highlightIndex = -1 | ||
| // IE is not considered | ||
| if (window.find) { | ||
| document.designMode = 'on' | ||
| // step 1: ask the browser to highlight the found | ||
| const sel = window.getSelection() | ||
| sel.collapse(document.body, 0) | ||
| while (window.find(strWithFixes, caseSensitive)) { | ||
| document.execCommand('hiliteColor', true, 'rgba(255, 255, 255, 0)') | ||
| sel.collapseToEnd() | ||
| // step 2: locate the found within the container where the annotator is applied | ||
| // selector may become better | ||
| const found = document.querySelector( | ||
| '#' + | ||
| containerId + | ||
| ' [style="background-color: rgba(255, 255, 255, 0);"]' | ||
| ) | ||
| if (found) { | ||
| const foundStr = found.innerHTML.replace(/<[^>]*>/g, '') | ||
| const result = TextAnnotator.getBestSubstring( | ||
| foundStr, | ||
| str, | ||
| threshold | ||
| ) | ||
| if (result.similarity) { | ||
| const text = this.isHTML ? this.stripedHTML : this.originalContent | ||
| const index = text.indexOf(foundStr) | ||
| if (index !== -1) { | ||
| highlightIndex = | ||
| this.highlights.push({ | ||
| loc: [index + result.loc[0], index + result.loc[1]], | ||
| }) - 1 | ||
| } | ||
| } | ||
| // find index difference | ||
| for (let i = 0; i < annotators.length; i++) { | ||
| const annotator = annotators[i] | ||
| let indexInc = 0 | ||
| for (let j = 0; j < otherTags.length; j++) { | ||
| const otherTag = otherTags[j] | ||
| if (annotator.index < otherTag.index) { | ||
| break | ||
| } | ||
| } | ||
| // step 3: remove the highlights created by the browser | ||
| document.execCommand('undo') | ||
| document.designMode = 'off' | ||
| } | ||
| return highlightIndex | ||
| } | ||
| fuzzySearch(prefix, str, postfix, fuzzySearchOptions = {}) { | ||
| const caseSensitive = fuzzySearchOptions.caseSensitive | ||
| const tokenBased = fuzzySearchOptions.tokenBased | ||
| let tbThreshold = fuzzySearchOptions.tbThreshold || 0.68 | ||
| // sentence-based fuzzy search is enabled by default | ||
| const sentenceBased = | ||
| fuzzySearchOptions.sentenceBased === undefined || | ||
| fuzzySearchOptions.sentenceBased | ||
| let sbThreshold = fuzzySearchOptions.sbThreshold || 0.85 | ||
| const maxLengthDiff = fuzzySearchOptions.maxLengthDiff || 0.1 | ||
| const lenRatio = fuzzySearchOptions.lenRatio || 2 | ||
| const processSentence = fuzzySearchOptions.processSentence | ||
| let highlightIndex = -1 | ||
| const text = this.isHTML ? this.stripedHTML : this.originalContent | ||
| // token-based | ||
| if (tokenBased || prefix || postfix) { | ||
| // step 1: find all indexes of str | ||
| const strIndexes = [] | ||
| let i = -1 | ||
| while ((i = text.indexOf(str, i + 1)) !== -1) { | ||
| strIndexes.push(i) | ||
| } | ||
| // step 2: find the index of the most similar "fragment" - the str with pre- and post- fixes | ||
| let strIndex = -1 | ||
| const fragment = prefix + str + postfix | ||
| for (let i = 0; i < strIndexes.length; i++) { | ||
| const si = strIndexes[i] | ||
| // f can be wider | ||
| const f = | ||
| text.substring(si - prefix.length, si) + | ||
| str + | ||
| text.substring(si + str.length, si + str.length + postfix.length) | ||
| const similarity = TextAnnotator.getSimilarity( | ||
| f, | ||
| fragment, | ||
| caseSensitive | ||
| ) | ||
| if (similarity >= tbThreshold) { | ||
| tbThreshold = similarity | ||
| strIndex = si | ||
| } | ||
| } | ||
| // step 3: check whether the most similar enough "fragment" is found, if yes return its location | ||
| if (strIndex !== -1) { | ||
| highlightIndex = | ||
| this.highlights.push({ loc: [strIndex, strIndex + str.length] }) - 1 | ||
| } | ||
| } | ||
| // sentence-based | ||
| else if (sentenceBased) { | ||
| // step 1: sentenize the text if has not done so | ||
| let sentences = [] | ||
| if (this.sentences.length) { | ||
| sentences = this.sentences | ||
| } else { | ||
| sentences = this.sentences = TextAnnotator.sentenize(text) | ||
| } | ||
| // step 2 (for efficiency only): filter sentences by words of the str | ||
| const words = str.split(/\s/) | ||
| const filteredSentences = [] | ||
| for (let i = 0; i < sentences.length; i++) { | ||
| for (let j = 0; j < words.length; j++) { | ||
| if (sentences[i].raw.includes(words[j])) { | ||
| filteredSentences.push(sentences[i]) | ||
| break | ||
| } | ||
| } | ||
| } | ||
| //step 3 (optional) | ||
| if (processSentence) { | ||
| let index = 0 | ||
| // for each sentence | ||
| for (let i = 0; i < filteredSentences.length; i++) { | ||
| const fs = filteredSentences[i] | ||
| let raw = fs.raw | ||
| // loc without tags | ||
| const loc = [fs.index, fs.index + raw.length] | ||
| let locInc = 0 | ||
| // add loc of all tags before the one being checked so as to derive the actual loc | ||
| const tagLocations = this.tagLocations | ||
| // for each loc of tag whose loc is larger than the last sentence | ||
| for (let j = index; j < tagLocations.length; j++) { | ||
| const tagLoc = tagLocations[j] | ||
| if (tagLoc[0] >= loc[0] && tagLoc[0] <= loc[1]) { | ||
| const tag = this.originalContent.substring( | ||
| tagLoc[0] + tagLoc[2], | ||
| tagLoc[0] + tagLoc[2] + tagLoc[1] | ||
| ) | ||
| const insertIndex = tagLoc[0] + locInc - loc[0] | ||
| raw = raw.slice(0, insertIndex) + tag + raw.slice(insertIndex) | ||
| locInc += tagLoc[1] | ||
| } else if (tagLoc[0] > loc[1]) { | ||
| index = j // not sure this part | ||
| break | ||
| } else if (annotator.index > otherTag.index) { | ||
| indexInc += otherTag.length | ||
| } else { | ||
| if (otherTag.annotationIndex === undefined) { | ||
| if (!annotator.isCloseTag) { | ||
| indexInc += otherTag.length | ||
| } | ||
| } | ||
| raw = processSentence(raw) | ||
| raw = raw.replace(/(<([^>]+)>)/gi, '') | ||
| const copy = fs.raw | ||
| // update the sentence if it got reduced | ||
| if (copy !== raw) { | ||
| fs.raw = raw | ||
| fs.index = fs.index + copy.indexOf(raw) | ||
| } | ||
| } | ||
| } | ||
| // step 4: find the most possible sentence | ||
| let mostPossibleSentence = null | ||
| for (let i = 0; i < filteredSentences.length; i++) { | ||
| const sentence = filteredSentences[i] | ||
| const similarity = TextAnnotator.getSimilarity( | ||
| sentence.raw, | ||
| str, | ||
| caseSensitive | ||
| ) | ||
| if (similarity >= sbThreshold) { | ||
| sbThreshold = similarity | ||
| mostPossibleSentence = sentence | ||
| } else if (i !== filteredSentences.length - 1) { | ||
| // combine two sentences to reduce the inaccuracy of sentenizing text | ||
| const newSentenceRaw = sentence.raw + filteredSentences[i + 1].raw | ||
| const lengthDiff = | ||
| Math.abs(newSentenceRaw.length - str.length) / str.length | ||
| if (lengthDiff <= maxLengthDiff) { | ||
| const newSimilarity = TextAnnotator.getSimilarity( | ||
| newSentenceRaw, | ||
| str, | ||
| caseSensitive | ||
| ) | ||
| if (newSimilarity >= sbThreshold) { | ||
| sbThreshold = newSimilarity | ||
| mostPossibleSentence = { | ||
| raw: newSentenceRaw, | ||
| index: sentence.index, | ||
| } else { | ||
| if (annotator.annotationIndex < otherTag.annotationIndex) { | ||
| if (otherTag.isCloseTag) { | ||
| indexInc += otherTag.length | ||
| } | ||
| } else { | ||
| if (!annotator.isCloseTag) { | ||
| indexInc += otherTag.length | ||
| } | ||
| } | ||
@@ -492,403 +206,80 @@ } | ||
| // step 5: if the most possible sentence is found, derive and return the location of the most similar str from it | ||
| if (mostPossibleSentence) { | ||
| const result = TextAnnotator.getBestSubstring( | ||
| mostPossibleSentence.raw, | ||
| str, | ||
| sbThreshold, | ||
| lenRatio, | ||
| caseSensitive, | ||
| true | ||
| ) | ||
| if (result.loc) { | ||
| let index = mostPossibleSentence.index | ||
| highlightIndex = | ||
| this.highlights.push({ | ||
| loc: [index + result.loc[0], index + result.loc[1]], | ||
| }) - 1 | ||
| } | ||
| } | ||
| // remove annotators one by one | ||
| this.html = | ||
| this.html.slice(0, annotator.index + indexInc) + | ||
| this.html.slice(annotator.index + indexInc + annotator.length) | ||
| this.tags.splice(annotatorIndexesInTags[i] - i, 1) | ||
| } | ||
| return highlightIndex | ||
| } | ||
| // future work: further improvement when one annotation binds with more than one highlight | ||
| // includeRequiredTag used in = condition only | ||
| includeRequiredTag(i, highlightLoc, tag) { | ||
| const isCloseTag = tag.startsWith('</') | ||
| const tagName = isCloseTag | ||
| ? tag.split('</')[1].split('>')[0] | ||
| : tag.split(' ')[0].split('<')[1].split('>')[0] | ||
| let included = false | ||
| let requiredTagNumber = 1 | ||
| let requiredTagCount = 0 | ||
| // if both the start tag and the end tag are at the borders, place the tags outside the borders | ||
| // if the close tag is at the border, check backwards until the start of the highlight | ||
| if (isCloseTag) { | ||
| for (let i2 = i - 1; i2 >= 0; i2--) { | ||
| const tagLoc2 = this.tagLocations[i2] | ||
| if (highlightLoc[0] > tagLoc2[0]) { | ||
| break | ||
| } else { | ||
| const tag2 = this.originalContent.substring( | ||
| tagLoc2[0] + tagLoc2[2], | ||
| tagLoc2[0] + tagLoc2[2] + tagLoc2[1] | ||
| ) | ||
| if (tag2.startsWith('</' + tagName)) { | ||
| requiredTagNumber++ | ||
| } else if (tag2.startsWith('<' + tagName)) { | ||
| requiredTagCount++ | ||
| } | ||
| if (requiredTagNumber === requiredTagCount) { | ||
| included = true | ||
| break | ||
| } | ||
| } | ||
| } | ||
| } | ||
| // if the start tag is at the border, check forwards until the end of the highlight | ||
| else { | ||
| for (let i2 = i + 1; i2 < this.tagLocations.length; i2++) { | ||
| const tagLoc2 = this.tagLocations[i2] | ||
| if (highlightLoc[1] < tagLoc2[0]) { | ||
| break | ||
| } else { | ||
| const tag2 = this.originalContent.substring( | ||
| tagLoc2[0] + tagLoc2[2], | ||
| tagLoc2[0] + tagLoc2[2] + tagLoc2[1] | ||
| ) | ||
| if (tag2.startsWith('<' + tagName)) { | ||
| requiredTagNumber++ | ||
| } else if (tag2.startsWith('</' + tagName)) { | ||
| requiredTagCount++ | ||
| } | ||
| if (requiredTagNumber === requiredTagCount) { | ||
| included = true | ||
| break | ||
| } | ||
| } | ||
| } | ||
| } | ||
| return included | ||
| return this.html | ||
| } | ||
| adjustLoc( | ||
| highlightTagName = 'span', | ||
| highlightIdPattern, | ||
| highlightIndex, | ||
| highlightClass | ||
| ) { | ||
| const highlightLoc = this.highlights[highlightIndex].loc | ||
| const locInc = [0, 0] | ||
| // step 1: check locations of tags | ||
| const length = this.tagLocations.length | ||
| for (let i = 0; i < length; i++) { | ||
| const tagLoc = this.tagLocations[i] | ||
| // start end tag | ||
| if (highlightLoc[1] < tagLoc[0]) { | ||
| break | ||
| } | ||
| // start end&tag | ||
| else if (highlightLoc[1] === tagLoc[0]) { | ||
| const tag = this.originalContent.substring( | ||
| tagLoc[0] + tagLoc[2], | ||
| tagLoc[0] + tagLoc[2] + tagLoc[1] | ||
| ) | ||
| // if end tag, not block element and include the required close tag, add right to the tag | ||
| if ( | ||
| !tag.endsWith('/>') && | ||
| tag.startsWith('</') && | ||
| !blockElements.includes(tag.split('</')[1].split('>')[0]) && | ||
| this.includeRequiredTag(i, highlightLoc, tag) | ||
| ) { | ||
| locInc[1] += tagLoc[1] | ||
| } | ||
| } | ||
| // start tag end | ||
| else if (highlightLoc[1] > tagLoc[0]) { | ||
| locInc[1] += tagLoc[1] | ||
| // start&tag end | ||
| if (highlightLoc[0] === tagLoc[0]) { | ||
| const tag = this.originalContent.substring( | ||
| tagLoc[0] + tagLoc[2], | ||
| tagLoc[0] + tagLoc[2] + tagLoc[1] | ||
| ) | ||
| // if self close tag or end tag or block element or not include the required close tag, add right to the tag | ||
| if ( | ||
| tag.startsWith('</') || | ||
| tag.endsWith('/>') || | ||
| blockElements.includes( | ||
| tag.split(' ')[0].split('<')[1].split('>')[0] | ||
| ) || | ||
| !this.includeRequiredTag(i, highlightLoc, tag) | ||
| ) { | ||
| locInc[0] += tagLoc[1] | ||
| } | ||
| } | ||
| // tag start end | ||
| else if (highlightLoc[0] > tagLoc[0]) { | ||
| locInc[0] += tagLoc[1] | ||
| } | ||
| } | ||
| } | ||
| // step 2: check locations of other highlights | ||
| // all span (no blocks) | ||
| // stored in a different array than tags | ||
| // can intersect | ||
| for (let i = 0; i < this.highlights.length; i++) { | ||
| const highlight = this.highlights[i] | ||
| // only check the highlighted | ||
| if (highlight.highlighted) { | ||
| const openTagLength = TextAnnotator.getOpenTagLength( | ||
| highlightTagName, | ||
| highlightIdPattern, | ||
| i, | ||
| highlightClass | ||
| ) | ||
| const closeTagLength = TextAnnotator.getCloseTagLength(highlightTagName) | ||
| const loc = highlight.loc | ||
| if (highlightLoc[0] >= loc[1]) { | ||
| locInc[0] += openTagLength + closeTagLength | ||
| locInc[1] += openTagLength + closeTagLength | ||
| } | ||
| // syntactical correct but semantical incorrect | ||
| else if ( | ||
| highlightLoc[0] < loc[1] && | ||
| highlightLoc[0] > loc[0] && | ||
| highlightLoc[1] > loc[1] | ||
| ) { | ||
| locInc[0] += openTagLength | ||
| locInc[1] += openTagLength + closeTagLength | ||
| } else if (highlightLoc[0] <= loc[0] && highlightLoc[1] >= loc[1]) { | ||
| locInc[1] += openTagLength + closeTagLength | ||
| } | ||
| // syntactical correct but semantical incorrect | ||
| else if ( | ||
| highlightLoc[0] < loc[0] && | ||
| highlightLoc[1] > loc[0] && | ||
| highlightLoc[1] < loc[1] | ||
| ) { | ||
| locInc[1] += openTagLength | ||
| } else if (highlightLoc[0] >= loc[0] && highlightLoc[1] <= loc[1]) { | ||
| locInc[0] += openTagLength | ||
| locInc[1] += openTagLength | ||
| } | ||
| } | ||
| } | ||
| return [highlightLoc[0] + locInc[0], highlightLoc[1] + locInc[1]] | ||
| unannotateAll(annotationIndexes) { | ||
| annotationIndexes.forEach((annotationIndex) => { | ||
| this.unannotate(annotationIndex) | ||
| }) | ||
| return this.html | ||
| } | ||
| static createOpenTag( | ||
| highlightTagName = 'span', | ||
| highlightIdPattern, | ||
| highlightIndex, | ||
| highlightClass | ||
| ) { | ||
| return `<${highlightTagName} id="${ | ||
| highlightIdPattern + highlightIndex | ||
| }" class="${highlightClass}">` | ||
| } | ||
| // pure function | ||
| _stripHTMLTags(html) { | ||
| let text = html | ||
| const tags = [] | ||
| static createCloseTag(highlightTagName = 'span') { | ||
| return `</${highlightTagName}>` | ||
| } | ||
| static getOpenTagLength( | ||
| highlightTagName = 'span', | ||
| highlightIdPattern, | ||
| highlightIndex, | ||
| highlightClass | ||
| ) { | ||
| return TextAnnotator.createOpenTag( | ||
| highlightTagName, | ||
| highlightIdPattern, | ||
| highlightIndex, | ||
| highlightClass | ||
| ).length | ||
| } | ||
| static getCloseTagLength(highlightTagName = 'span') { | ||
| return TextAnnotator.createCloseTag(highlightTagName).length | ||
| } | ||
| static trim(prefix, str, postfix) { | ||
| prefix = prefix.replace(/^\s+/, '') | ||
| postfix = postfix.replace(/\s+$/, '') | ||
| if (!prefix) { | ||
| str = str.replace(/^\s+/, '') | ||
| let tag | ||
| const tagRegEx = /<[^>]+>/ | ||
| while ((tag = text.match(tagRegEx))) { | ||
| text = text.replace(tag, '') | ||
| tags.push({ | ||
| index: tag.index, | ||
| length: tag[0].length, | ||
| isCloseTag: tag[0].startsWith('</'), | ||
| }) | ||
| } | ||
| if (!postfix) { | ||
| str = str.replace(/\s+$/, '') | ||
| } | ||
| return { prefix, str, postfix } | ||
| return { text, tags } | ||
| } | ||
| static insert(str1, str2, index) { | ||
| // pure function | ||
| _insert(str1, str2, index) { | ||
| return str1.slice(0, index) + str2 + str1.slice(index) | ||
| } | ||
| static sentenize(text) { | ||
| const options = { | ||
| newline_boundaries: false, | ||
| html_boundaries: false, | ||
| sanitize: false, | ||
| allowed_tags: false, | ||
| preserve_whitespace: true, | ||
| abbreviations: null, | ||
| // pure function | ||
| _binaryInsert(arr, val, comparator) { | ||
| if (arr.length === 0 || comparator(arr[0], val) >= 0) { | ||
| arr.splice(0, 0, val) | ||
| return arr | ||
| } else if (arr.length > 0 && comparator(arr[arr.length - 1], val) <= 0) { | ||
| arr.splice(arr.length, 0, val) | ||
| return arr | ||
| } | ||
| return getSentences(text, options).map((raw) => { | ||
| // future work: can tokenizer return location directly | ||
| const index = text.indexOf(raw) | ||
| return { raw, index } | ||
| }) | ||
| } | ||
| static getBestSubstring( | ||
| str, | ||
| substr, | ||
| threshold, | ||
| lenRatio, | ||
| caseSensitive, | ||
| skipFirstRun | ||
| ) { | ||
| let result = {} | ||
| let similarity = skipFirstRun | ||
| ? threshold | ||
| : TextAnnotator.getSimilarity(str, substr, caseSensitive) | ||
| if (similarity >= threshold) { | ||
| // step 1: derive best substr | ||
| // future work: /s may be better | ||
| const words = str.split(' ') | ||
| while (words.length) { | ||
| const firstWord = words.shift() | ||
| const newStr = words.join(' ') | ||
| let newSimilarity = TextAnnotator.getSimilarity( | ||
| newStr, | ||
| substr, | ||
| caseSensitive | ||
| ) | ||
| if (newSimilarity < similarity) { | ||
| words.unshift(firstWord) | ||
| const lastWord = words.pop() | ||
| newSimilarity = TextAnnotator.getSimilarity( | ||
| words.join(' '), | ||
| substr, | ||
| caseSensitive | ||
| ) | ||
| if (newSimilarity < similarity) { | ||
| words.push(lastWord) | ||
| break | ||
| } else { | ||
| similarity = newSimilarity | ||
| } | ||
| } else { | ||
| similarity = newSimilarity | ||
| } | ||
| let left = 0, | ||
| right = arr.length | ||
| let leftLast = 0, | ||
| rightLast = right | ||
| while (left < right) { | ||
| const inPos = Math.floor((right + left) / 2) | ||
| const compared = comparator(arr[inPos], val) | ||
| if (compared < 0) { | ||
| left = inPos | ||
| } else if (compared > 0) { | ||
| right = inPos | ||
| } else { | ||
| right = inPos | ||
| left = inPos | ||
| } | ||
| const bestSubstr = words.join(' ') | ||
| // step 2: return the best substr and its loc if found and if it meets the threshold and the length ratio | ||
| if (!lenRatio || bestSubstr.length / substr.length <= lenRatio) { | ||
| const loc = [] | ||
| loc[0] = str.indexOf(bestSubstr) | ||
| loc[1] = loc[0] + bestSubstr.length | ||
| result = { similarity, loc } | ||
| if (leftLast === left && rightLast === right) { | ||
| break | ||
| } | ||
| leftLast = left | ||
| rightLast = right | ||
| } | ||
| return result | ||
| arr.splice(right, 0, val) | ||
| return arr | ||
| } | ||
| static getSimilarity(str1, str2, caseSensitive) { | ||
| if (!caseSensitive) { | ||
| str1 = str1.toLowerCase() | ||
| str2 = str2.toLowerCase() | ||
| } | ||
| if (str1 === str2) return 1 | ||
| // set str2 to denominator | ||
| return TextAnnotator.lcsLength(str1, str2) / str2.length | ||
| } | ||
| // copy from the code in https://www.npmjs.com/package/longest-common-subsequence | ||
| static lcsLength(firstSequence, secondSequence, caseSensitive) { | ||
| function createArray(dimension) { | ||
| const array = [] | ||
| for (let i = 0; i < dimension; i++) { | ||
| array[i] = [] | ||
| } | ||
| return array | ||
| } | ||
| const firstString = caseSensitive | ||
| ? firstSequence | ||
| : firstSequence.toLowerCase() | ||
| const secondString = caseSensitive | ||
| ? secondSequence | ||
| : secondSequence.toLowerCase() | ||
| if (firstString === secondString) { | ||
| return firstString.length | ||
| } | ||
| if ((firstString || secondString) === '') { | ||
| return ''.length | ||
| } | ||
| const firstStringLength = firstString.length | ||
| const secondStringLength = secondString.length | ||
| const lcsMatrix = createArray(secondStringLength + 1) | ||
| let i | ||
| let j | ||
| for (i = 0; i <= firstStringLength; i++) { | ||
| lcsMatrix[0][i] = 0 | ||
| } | ||
| for (i = 0; i <= secondStringLength; i++) { | ||
| lcsMatrix[i][0] = 0 | ||
| } | ||
| for (i = 1; i <= secondStringLength; i++) { | ||
| for (j = 1; j <= firstStringLength; j++) { | ||
| if (firstString[j - 1] === secondString[i - 1]) { | ||
| lcsMatrix[i][j] = lcsMatrix[i - 1][j - 1] + 1 | ||
| } else { | ||
| lcsMatrix[i][j] = Math.max(lcsMatrix[i - 1][j], lcsMatrix[i][j - 1]) | ||
| } | ||
| } | ||
| } | ||
| let lcs = '' | ||
| i = secondStringLength | ||
| j = firstStringLength | ||
| while (i > 0 && j > 0) { | ||
| if (firstString[j - 1] === secondString[i - 1]) { | ||
| lcs = firstString[j - 1] + lcs | ||
| i-- | ||
| j-- | ||
| } else if ( | ||
| Math.max(lcsMatrix[i - 1][j], lcsMatrix[i][j - 1]) === | ||
| lcsMatrix[i - 1][j] | ||
| ) { | ||
| i-- | ||
| } else { | ||
| j-- | ||
| } | ||
| } | ||
| return lcs.length | ||
| } | ||
| } | ||
| export default TextAnnotator |
| import TextAnnotator from '../src/text-annotator' | ||
| const content = | ||
| '"I am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan Huang' | ||
| const html = | ||
| '"I am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| const closeTag = '</span>' | ||
| test('annotate text without surrounding/inside tags', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const searchText = 'EMBL-EBI' | ||
| const annotatedHtml = textAnnotator.annotate(textAnnotator.search(searchText)) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in <span class="annotation annotation-0">EMBL-EBI</span>. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| }) | ||
| describe('test main scenarios', () => { | ||
| test('direct search', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const highlightIndex = annotator.search('I') | ||
| const newContent = annotator.highlight(highlightIndex) | ||
| const openTag = TextAnnotator.createOpenTag( | ||
| 'span', | ||
| 'highlight-', | ||
| highlightIndex, | ||
| 'highlight' | ||
| ) | ||
| expect(newContent).toBe( | ||
| `"${openTag}I${closeTag} am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan Huang` | ||
| ) | ||
| }) | ||
| test('annotate text with surrounding tags', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const searchText = 'frontend developer' | ||
| const annotatedHtml = textAnnotator.annotate(textAnnotator.search(searchText)) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i>Zhan Huang</i></b>, a <b><span class="annotation annotation-0">frontend developer</span></b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| }) | ||
| test('search all', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const highlightIndexes = annotator.searchAll('Zhan Huang') | ||
| const newContent = annotator.highlightAll(highlightIndexes) | ||
| const openTag1 = TextAnnotator.createOpenTag( | ||
| 'span', | ||
| 'highlight-', | ||
| highlightIndexes[0], | ||
| 'highlight' | ||
| ) | ||
| const openTag2 = TextAnnotator.createOpenTag( | ||
| 'span', | ||
| 'highlight-', | ||
| highlightIndexes[1], | ||
| 'highlight' | ||
| ) | ||
| expect(newContent).toBe( | ||
| `"I am ${openTag1}<b><i>Zhan Huang</i></b>${closeTag}, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - ${openTag2}Zhan Huang${closeTag}` | ||
| ) | ||
| }) | ||
| test('annotate text with inside open tag', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const searchText = 'a frontend developer' | ||
| const annotatedHtml = textAnnotator.annotate(textAnnotator.search(searchText)) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i>Zhan Huang</i></b>, <span class="annotation annotation-0">a </span><b><span class="annotation annotation-0">frontend developer</span></b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| }) | ||
| test('token-based fuzzy search', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const highlightIndex = annotator.search('frontend developer', { | ||
| prefix: 'a ', | ||
| postfix: ' in EMBLEBI', | ||
| fuzzySearchOptions: {}, | ||
| }) | ||
| const newContent = annotator.highlight(highlightIndex) | ||
| const openTag = TextAnnotator.createOpenTag( | ||
| 'span', | ||
| 'highlight-', | ||
| highlightIndex, | ||
| 'highlight' | ||
| ) | ||
| expect(newContent).toBe( | ||
| `"I am <b><i>Zhan Huang</i></b>, a ${openTag}<b>frontend developer</b>${closeTag} in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan Huang` | ||
| ) | ||
| }) | ||
| test('annotate text with inside close tag', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const searchText = 'frontend developer in EMBL-EBI' | ||
| const annotatedHtml = textAnnotator.annotate(textAnnotator.search(searchText)) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i>Zhan Huang</i></b>, a <b><span class="annotation annotation-0">frontend developer</span></b><span class="annotation annotation-0"> in EMBL-EBI</span>. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| }) | ||
| test('sentence-based fuzzy search', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const highlightIndex = annotator.search('I like fool', { | ||
| fuzzySearchOptions: {}, | ||
| }) | ||
| const newContent = annotator.highlight(highlightIndex) | ||
| const openTag = TextAnnotator.createOpenTag( | ||
| 'span', | ||
| 'highlight-', | ||
| highlightIndex, | ||
| 'highlight' | ||
| ) | ||
| expect(newContent).toBe( | ||
| `"I am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. ${openTag}I like food${closeTag} and sports. My favourite food is udon noodles." - Zhan Huang` | ||
| ) | ||
| }) | ||
| test('annotate text with multiple tags surrounding/inside', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const searchText = 'Zhan Huang, a frontend developer in EMBL-EBI' | ||
| const annotatedHtml = textAnnotator.annotate(textAnnotator.search(searchText)) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i><span class="annotation annotation-0">Zhan Huang</span></i></b><span class="annotation annotation-0">, a </span><b><span class="annotation annotation-0">frontend developer</span></b><span class="annotation annotation-0"> in EMBL-EBI</span>. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| }) | ||
| test('combination of searching and highlighting', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const result = annotator.searchAndHighlight('sports') | ||
| const openTag = TextAnnotator.createOpenTag( | ||
| 'span', | ||
| 'highlight-', | ||
| result.highlightIndex, | ||
| 'highlight' | ||
| ) | ||
| expect(result.content).toBe( | ||
| `"I am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and ${openTag}sports${closeTag}. My favourite food is udon noodles." - Zhan Huang` | ||
| ) | ||
| }) | ||
| test('annotate all occurrences of the text', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const searchText = 'Zhan Huang' | ||
| const annotationIndexes = textAnnotator.searchAll(searchText) | ||
| const annotatedHtml = textAnnotator.annotateAll(annotationIndexes) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i><span class="annotation annotation-0">Zhan Huang</span></i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - <span class="annotation annotation-1">Zhan HUANG</span>' | ||
| ) | ||
| }) | ||
| test('removal of a highlight', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const result = annotator.searchAndHighlight('udon noodles') | ||
| expect( | ||
| annotator.unhighlight(result.highlightIndex, { | ||
| content: result.content, | ||
| }) | ||
| ).toBe(content) | ||
| }) | ||
| test('annotate multiple pieces of text', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| textAnnotator.annotate(textAnnotator.search('Zhan Huang')) | ||
| textAnnotator.annotate(textAnnotator.search('food and sports')) | ||
| const annotatedHtml = textAnnotator.annotate( | ||
| textAnnotator.search('a frontend developer in EMBL-EBI') | ||
| ) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i><span class="annotation annotation-0">Zhan Huang</span></i></b>, <span class="annotation annotation-2">a </span><b><span class="annotation annotation-2">frontend developer</span></b><span class="annotation annotation-2"> in EMBL-EBI</span>. I like <span class="annotation annotation-1">food and sports</span>. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| }) | ||
| test('use <mark> for highlight', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const highlightIndex = annotator.search('I') | ||
| const newContent = annotator.highlight(highlightIndex, { | ||
| highlightTagName: 'mark', | ||
| }) | ||
| const openTag = TextAnnotator.createOpenTag( | ||
| 'mark', | ||
| 'highlight-', | ||
| highlightIndex, | ||
| 'highlight' | ||
| ) | ||
| const closeTag = '</mark>' | ||
| expect(newContent).toBe( | ||
| `"${openTag}I${closeTag} am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan Huang` | ||
| ) | ||
| }) | ||
| test('annotate text with multiple tags inside/surrounding', () => { | ||
| const textAnnotator = new TextAnnotator( | ||
| '<p><span>I am <b>Zhan Huang</b></span></p>. <p><i>I like apples.<i></p>' | ||
| ) | ||
| const annotatedHtml = textAnnotator.annotate( | ||
| textAnnotator.search('I am Zhan Huang. I like') | ||
| ) | ||
| expect(annotatedHtml).toBe( | ||
| '<p><span><span class="annotation annotation-0">I am </span><b><span class="annotation annotation-0">Zhan Huang</span></b></span></p><span class="annotation annotation-0">. </span><p><i><span class="annotation annotation-0">I like</span> apples.<i></p>' | ||
| ) | ||
| }) | ||
| describe('test edge cases', () => { | ||
| test('ec1', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const highlightIndex = annotator.search('I am Zhan Huang') | ||
| const newContent = annotator.highlight(highlightIndex) | ||
| const openTag = TextAnnotator.createOpenTag( | ||
| 'span', | ||
| 'highlight-', | ||
| highlightIndex, | ||
| 'highlight' | ||
| ) | ||
| expect(newContent).toBe( | ||
| `"${openTag}I am <b><i>Zhan Huang</i></b>${closeTag}, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan Huang` | ||
| ) | ||
| }) | ||
| test('annotate text with prefix/postfix', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const annotatedHtml = textAnnotator.annotate( | ||
| textAnnotator.search('Zhan Huang', { prefix: '- ', postfix: '' }) | ||
| ) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - <span class="annotation annotation-0">Zhan HUANG</span>' | ||
| ) | ||
| }) | ||
| test('ec2', () => { | ||
| const annotator = new TextAnnotator({ content }) | ||
| const highlightIndex = annotator.search('frontend developer in EMBL-EBI') | ||
| const newContent = annotator.highlight(highlightIndex) | ||
| const openTag = TextAnnotator.createOpenTag( | ||
| 'span', | ||
| 'highlight-', | ||
| highlightIndex, | ||
| 'highlight' | ||
| ) | ||
| expect(newContent).toBe( | ||
| `"I am <b><i>Zhan Huang</i></b>, a ${openTag}<b>frontend developer</b> in EMBL-EBI${closeTag}. I like food and sports. My favourite food is udon noodles." - Zhan Huang` | ||
| ) | ||
| }) | ||
| test('annotate text with trimming', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const annotatedHtml = textAnnotator.annotate( | ||
| textAnnotator.search('Zhan Huang', { prefix: ' - ', postfix: '' }) | ||
| ) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - <span class="annotation annotation-0">Zhan HUANG</span>' | ||
| ) | ||
| }) | ||
| test('annotate text with case sensitive', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const annotatedHtml = textAnnotator.annotate( | ||
| textAnnotator.search('Zhan HUANG', { caseSensitive: true }) | ||
| ) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i>Zhan Huang</i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - <span class="annotation annotation-0">Zhan HUANG</span>' | ||
| ) | ||
| }) | ||
| test('unannotate the text', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| const searchText = 'Zhan Huang, a frontend developer in EMBL-EBI' | ||
| const annotationIndex = textAnnotator.search(searchText) | ||
| const annotatedHtml = textAnnotator.annotate(annotationIndex) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i><span class="annotation annotation-0">Zhan Huang</span></i></b><span class="annotation annotation-0">, a </span><b><span class="annotation annotation-0">frontend developer</span></b><span class="annotation annotation-0"> in EMBL-EBI</span>. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| const unannotatedHtml = textAnnotator.unannotate(annotationIndex) | ||
| expect(unannotatedHtml).toBe(html) | ||
| }) | ||
| test('unnotatate the text with tags inside', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| textAnnotator.annotate( | ||
| textAnnotator.search('Zhan Huang, a frontend developer in EMBL-EBI') | ||
| ) | ||
| textAnnotator.annotate(textAnnotator.search('Zhan Huang')) | ||
| const annotatedHtml = textAnnotator.unannotate(0) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i><span class="annotation annotation-1">Zhan Huang</span></i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| }) | ||
| test('annotate the text again after unannotating it', () => { | ||
| const textAnnotator = new TextAnnotator(html) | ||
| textAnnotator.annotate(textAnnotator.search('Zhan Huang')) | ||
| textAnnotator.annotate(textAnnotator.search('food and sports')) | ||
| textAnnotator.unannotateAll([0, 1]) | ||
| console.log(textAnnotator.html) | ||
| const annotatedHtml = textAnnotator.annotate(0) | ||
| expect(annotatedHtml).toBe( | ||
| '"I am <b><i><span class="annotation annotation-0">Zhan Huang</span></i></b>, a <b>frontend developer</b> in EMBL-EBI. I like food and sports. My favourite food is udon noodles." - Zhan HUANG' | ||
| ) | ||
| }) | ||
| test('annotate document without html tags', () => { | ||
| const textAnnotator = new TextAnnotator('I am Zhan Huang') | ||
| const annotatedHtml = textAnnotator.annotate( | ||
| textAnnotator.search('Zhan Huang') | ||
| ) | ||
| expect(annotatedHtml).toBe( | ||
| 'I am <span class="annotation annotation-0">Zhan Huang</span>' | ||
| ) | ||
| }) |
Sorry, the diff of this file is not supported yet
Sorry, the diff of this file is too big to display
New alerts
Major refactor
Supply chain riskPackage has recently undergone a major refactor. It may be unstable or indicate significant internal changes. Use caution when updating to versions that include significant changes.
Found 1 instance in 1 package
Fixed alerts
Environment variable access
Supply chain riskPackage accesses environment variables, which may be a sign of credential stuffing or data theft.
Found 3 instances in 1 package
Filesystem access
Supply chain riskAccesses the file system, and could potentially read sensitive data.
Found 1 instance in 1 package
No v1
QualityPackage is not semver >=1. This means it is not stable and does not support ^ ranges.
Found 1 instance in 1 package
Improved metrics
- Dependency count
- decreased by-100%
0
- Number of low quality alerts
- decreased by-100%
0
- Number of low supply chain risk alerts
- decreased by-100%
0
Worsened metrics
- Total package byte prevSize
- decreased by-80.3%
36686
- Number of package files
- decreased by-21.43%
11
- Lines of code
- decreased by-71.24%
644
- Number of lines in readme file
- decreased by-28.7%
82
- Number of medium supply chain risk alerts
- increased byInfinity%
1
Dependency changes
- Removedhtml-entities@^2.1.0
- Removedhtml-entities@2.5.2(transitive)