
Website / Domain Categorization API for Node.js
Website / Domain Categorization API is a Node.js module that uses machine learning model to classify arbitrary blocks of input texts or URLs into content categories.
Content categories are based on two taxonomies:
- Ecommerce (21 Tier 1 categories, 192 Tier 2 categories and 1113 Tier 3 categories)
- IAB based (29 Tier 1 categories, 447 Tier 2 categories)
Installation
npm i @websitecategorization/websitecategorization
Usage example
var request = require('request');
var options = {
'method': 'POST',
'url': 'https://www.websitecategorizationapi.com/api/gpt/gpt_category1.php',
'headers': {
'Content-Type': 'application/x-www-form-urlencoded'
},
form: {
'query': 'earphone buds'
}
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});
Use cases
Web Categorization API is used by a wide variety of companies for many different use cases.
It is suitable for Ad Exchanges, Demand Side Platforms (DSPs), Supply Side Platforms (SSPs) and Ad Networks. SSP (Supply Side Platform) companies can e.g. use it to identify the advertiser’s category to check its eligibility for real-time bidding.
Other use cases include Web Content Filtering where a company can employ it to filter out non-work related websites, such as social media networks, shopping platforms and similar.
Website / Domain categorization API is based on a machine learning model that has been extensively tested and used both in small and large scale classification projects, including on a project with 30+ million texts.
It is continuously developed and regularly updated (in terms of training data set) to reflect and include new verticals arising each year.
Machine Learning Models for Website Classification
Text classification is usually automated as it is often used on use cases where the number of texts needed to be classified number in millions.
For this reason, we use machine learning models for text classifications.
In early period of machine learning, the most common models used for text classification were ranging from simpler ones, like Naive Bayes to more complex ones like Random Forests, Support Vector Machines and Logistic Regression.
Support Vector Machines are especially good in terms of accuracy and f1 scores achieved on text classification tasks, they however have a downside in that the complexity of training a SVM model rapidly increases with number of texts in training dataset.
In last decade, with the rise of neural networks, more text classification models are based on the latter.
Earlier deep neural networks for text classification were often based on LSTM neural net. In recent times there have been other neural network architectures successfuly used for general text and product classification models.
Authors in this highly cited paper: https://arxiv.org/pdf/1803.01271.pdf researched convolutional neural networks for text classification and came to conclusion that even a simple convolutional architecture outperforms canonical recurrent networks such as the previously mentioned LSTMs, across different classification tasks.
The NN model from the paper can be accessed here: https://github.com/locuslab/TCN, with keras implementation available at https://github.com/philipperemy/keras-tcn.
Feature engineering
When using texts as input to machine learning models, we need to convert them in a numerical format. This is part of the feature engineering process, which can also include other steps, e.g. lemmatization, removal of stop words, removal of punctuations, etc.
Once these pre-processing is done, we can use different approaches in converting texts to numerical representation. One of the simplest one is Bag of Words, where we simply count the number of times a word has occured in text.
A more complex, "count" method is TF-IDF or term frequence-inverse document frequency. In this case we count the number of times a token,word, term has occured in a document but "correct" this for its frequency in the whole corpus.
In this way, common words like "the" are discounted because they occur commonly in the whole corpus, whereas words that are specific to some document but are not often found elsewhere are not corrected by much of a factor.
A more advanced form of feature engineering includes using shallow neural nets for representation of texts. One approach from this group is Word2Vec where we represent each word with fixed-dimensional vector.
Vectors of words are "learned" by training the shallow neural network of Word2Vec on a large corpus of documents with the main idea being that words that are semantically similar should be located near in the hyperspace of words vectors.
A well known example is that arithmetic operation of vector("King") - vector("Queen") should be a very similar vector to the vector obtained with vector("Man") - vector("Woman").
The most well known Word2Vec model is the one trained on Google News corpus and can be accessed at https://huggingface.co/fse/word2vec-google-news-300.
There also implementation available in many NLP libraries, e.g. in spacy: https://spacy.io/usage/embeddings-transformers.
These word embedding and sentence embedding approaches can be especially useful when developing text and product classification models.
Machine learning interpretability / explainability (XAI)
Machine learning models are increasingly influencing decisions in our everyday lives. Their predictions or classifications are often though inscrutable in the sense that they act as "black boxes" where it is not exactly known how did they reach results.
This has led to the rise of so-called artificial intelligence explainability (XAI) or the desire for interpretability of machine learning model decisions, in a form, that humans can understand.
The ability of explaining decisions is increasingly seen as an important part of building trust in AI and this is increasingly being demanded by regulators as well.
“Right to Explanation” has thus become one of the key features of the GDPR regulation. Similar requirements in the Equal Credit Opportunity Act (ECOA) and the Fair Credit Reporting Act (FCRA).
The website categorization service is one of the few services of this kind which has integrated explainability to its results. Each categorization is thus provided with explanation for it.
Example:
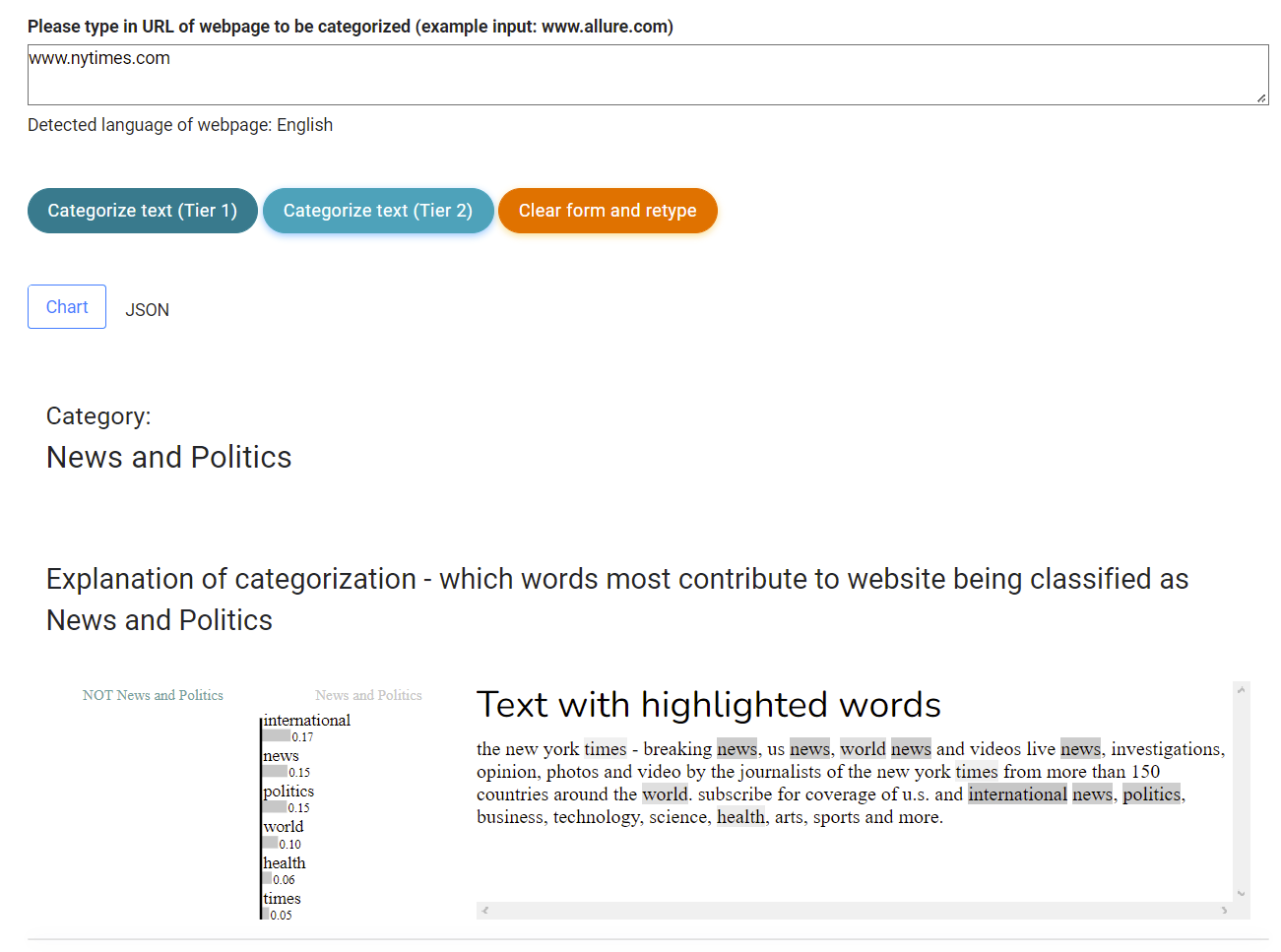
Form of json
Example output from IAB1 Website Categorization API on example domain:
{
"classification": [
{
"category": "Style & Fashion",
"value": 0.6335134346543948
},
{
"category": "Religion & Spirituality",
"value": 0.31965677636420087
},
{
"category": "Events and Attractions",
"value": 0.028203161466589827
},
{
"category": "Pop Culture",
"value": 0.008486557302356994
},
{
"category": "Books and Literature",
"value": 0.0028975322143729425
},
{
"category": "Shopping",
"value": 0.0014989265842864407
},
{
"category": "Fine Art",
"value": 0.0014698938766846063
},
{
"category": "Family and Relationships",
"value": 0.0008695569530150543
},
{
"category": "Hobbies & Interests",
"value": 0.0007021051093678122
},
{
"category": "Travel",
"value": 0.00045551400716377827
},
{
"category": "Movies",
"value": 0.0003105774008160576
},
{
"category": "Television",
"value": 0.0002812439624312471
},
{
"category": "Healthy Living",
"value": 0.00027001968240167887
},
{
"category": "Careers",
"value": 0.0002666186301324818
},
{
"category": "Food & Drink",
"value": 0.0002460227720972317
},
{
"category": "Home & Garden",
"value": 0.00021331353597162862
},
{
"category": "Medical Health",
"value": 0.00018344636503169902
},
{
"category": "Music and Audio",
"value": 0.00007348860474246987
},
{
"category": "Video Gaming",
"value": 0.00006822010822593386
},
{
"category": "Real Estate",
"value": 0.00006517844821148466
},
{
"category": "Pets",
"value": 0.00006069812911973799
},
{
"category": "Education",
"value": 0.00004860296854985923
},
{
"category": "News and Politics",
"value": 0.000035123587801619264
},
{
"category": "Sports",
"value": 0.00003402965849228489
},
{
"category": "Science",
"value": 0.000026461875107857055
},
{
"category": "Automotive",
"value": 0.000024825949895016523
},
{
"category": "Personal Finance",
"value": 0.00001581204114251354
},
{
"category": "Technology & Computing",
"value": 0.000015037047929356491
},
{
"category": "Business and Finance",
"value": 0.000007820699466562138
}
],
"language": "en"
}
Curl
Supported API calls (in curl) that can be adapted to javascript:
curl --location --request POST 'https://www.websitecategorizationapi.com/api/gpt/gpt_category1.php' \
--header 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'query=polaroid land camera' \
--data-urlencode 'api_key=b4dcde2ce5fb2d0b887b5e'
curl --location --request POST 'https://www.websitecategorizationapi.com/api/gpt/gpt_category2.php' \
--header 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'query=polaroid land camera' \
--data-urlencode 'api_key=b4dcde2ce5fb2d0b887b5e'
curl --location --request POST 'https://www.websitecategorizationapi.com/api/gpt/gpt_category3.php' \
--header 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'query=polaroid land camera' \
--data-urlencode 'api_key=b4dcde2ce5fb2d0b887b5e'
curl --location --request POST 'https://www.websitecategorizationapi.com/api/iab/gpt_category1.php' \
--header 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'query=credit card' \
--data-urlencode 'api_key=b4dcde2ce5fb2d0b887b5e'
curl --location --request POST 'https://www.websitecategorizationapi.com/api/iab/gpt_category2.php' \
--header 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'query=credit card' \
--data-urlencode 'api_key=b4dcde2ce5fb2d0b887b5e'
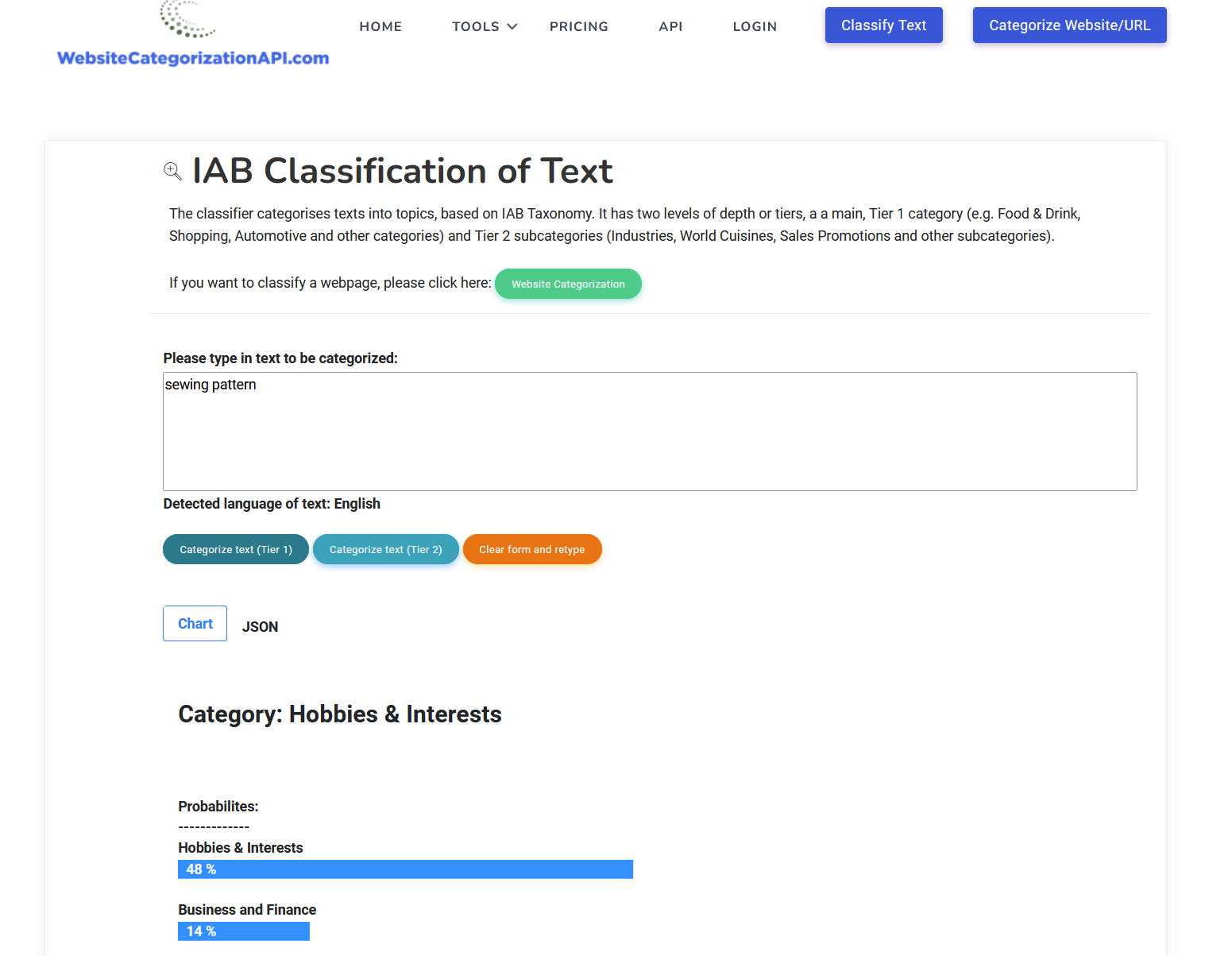
UI Dashboard
Website categorization service can be used both as API or in form of dashboard UI, as seen here:
Support for languages
Service supports website categorization of texts written in german, french, italian, spanish, portuguese and many other languages.
Useful resources
Package available on:



