Product
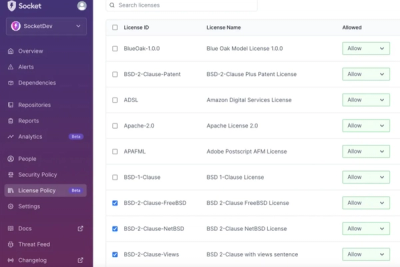
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
This Python 3 package allows to compress fastText word embedding models
(from the gensim package) by orders of magnitude,
without significantly affecting their quality.
Here are some links to the models that have already been compressed.
This blogpost in Russian and this one in English give more details about the motivation and methods for compressing fastText models.
Note: gensim==4.0.0 has introduced some backward-incompatible changes:
compatible_hash=False).The package can be installed with pip:
pip install compress-fasttext[full]
If you are not going to perform matrix decomposition or quantization, you can install a variety with less dependencies:
pip install compress-fasttext
You can use this package to compress your own fastText model (or one downloaded e.g. from RusVectores):
Compress a model in Gensim format:
import gensim
import compress_fasttext
big_model = gensim.models.fasttext.FastTextKeyedVectors.load('path-to-original-model')
small_model = compress_fasttext.prune_ft_freq(big_model, pq=True)
small_model.save('path-to-new-model')
Import a model in Facebook original format and compress it:
from gensim.models.fasttext import load_facebook_model
import compress_fasttext
big_model = load_facebook_model('path-to-original-model').wv
small_model = compress_fasttext.prune_ft_freq(big_model, pq=True)
small_model.save('path-to-new-model')
To perform this compression, you will need to pip install gensim==3.8.3 sklearn beforehand.
Different compression methods include:
svd_ft)quantize_ft)prune_ft)prune_ft_freq)The recommended approach is combination of feature selection and quantization (prune_ft_freq with pq=True).
If you just need a tiny fastText model for Russian, you can download this 21-megabyte model. It's a compressed version of geowac_tokens_none_fasttextskipgram_300_5_2020 model from RusVectores.
If compress-fasttext is already installed, you can download and use this tiny model
import compress_fasttext
small_model = compress_fasttext.models.CompressedFastTextKeyedVectors.load(
'https://github.com/avidale/compress-fasttext/releases/download/gensim-4-draft/geowac_tokens_sg_300_5_2020-100K-20K-100.bin'
)
print(small_model['спасибо'])
# [ 0.26762889 0.35489027 ... -0.06149674] # a 300-dimensional vector
print(small_model.most_similar('котенок'))
# [('кот', 0.7391024827957153), ('пес', 0.7388300895690918), ('малыш', 0.7280327081680298), ... ]
The class CompressedFastTextKeyedVectors inherits from gensim.models.fasttext.FastTextKeyedVectors,
but makes a few additional optimizations.
For English, you can use this tiny model, obtained by compressing the model by Facebook.
import compress_fasttext
small_model = compress_fasttext.models.CompressedFastTextKeyedVectors.load(
'https://github.com/avidale/compress-fasttext/releases/download/v0.0.4/cc.en.300.compressed.bin'
)
print(small_model['hello'])
# [ 1.84736611e-01 6.32683930e-03 4.43901886e-03 ... -2.88431027e-02] # a 300-dimensional vector
print(small_model.most_similar('Python'))
# [('PHP', 0.5252903699874878), ('.NET', 0.5027452707290649), ('Java', 0.4897131323814392), ... ]
More compressed models for 101 various languages can be found at https://zenodo.org/record/4905385.
In practical applications, you usually feed fastText embeddings to some other model.
The class FastTextTransformer uses the scikit-learn interface
and represents a text as the average of the embedding of its words.
With it you can, for example, train a classifier on top of fastText
to tell edible things from inedible ones:
import compress_fasttext
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from compress_fasttext.feature_extraction import FastTextTransformer
small_model = compress_fasttext.models.CompressedFastTextKeyedVectors.load(
'https://github.com/avidale/compress-fasttext/releases/download/v0.0.4/cc.en.300.compressed.bin'
)
classifier = make_pipeline(
FastTextTransformer(model=small_model),
LogisticRegression()
).fit(
['banana', 'soup', 'burger', 'car', 'tree', 'city'],
[1, 1, 1, 0, 0, 0]
)
classifier.predict(['jet', 'train', 'cake', 'apple'])
# array([0, 0, 1, 1])
This code is heavily based on the navec package by Alexander Kukushkin and the blogpost by Andrey Vasnetsov about shrinking fastText embeddings.
FAQs
A set of tools to compress gensim fasttext models
We found that compress-fasttext demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
Product
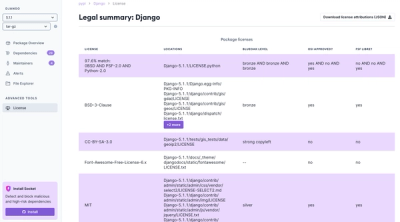
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
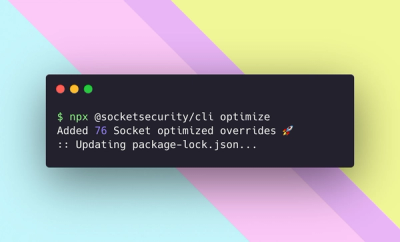
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.