
Security News
MCP Steering Committee Launches Official MCP Registry in Preview
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
By Sarah Gooding - Sep 09, 2025
Databank is an easy-to-use Python library for making raw SQL queries in a multi-threaded environment.

![]()
Databank is an easy-to-use Python library for making raw SQL queries in a multi-threaded environment.
No ORM, no frills. Only raw SQL queries and parameter binding. Thread-safe. Built on top of SQLAlchemy.

(The photo was taken by Matthew Ratzloff and is licensed under CC BY-NC-ND 2.0.)
You can install the latest stable version from PyPI:
$ pip install databank
Adapters not included. Install e.g. psycopg2 for PostgreSQL:
$ pip install psycopg2
Connect to the database of your choice:
>>> from databank import Database
>>> db = Database("postgresql://user:password@localhost/db", pool_size=2)
The keyword arguments are passed directly to SQLAlchemy's create_engine() function. Depending on the database you connect to, you have options like the size of connection pools.
If you are using
databankin a multi-threaded environment (e.g. in a web application), make sure the pool size is at least the number of worker threads.
Let's create a simple table:
>>> db.execute("CREATE TABLE beatles (id SERIAL PRIMARY KEY, member TEXT NOT NULL);")
You can insert multiple rows at once:
>>> params = [
... {"id": 0, "member": "John"},
... {"id": 1, "member": "Paul"},
... {"id": 2, "member": "George"},
... {"id": 3, "member": "Ringo"}
... ]
>>> db.execute_many("INSERT INTO beatles (id, member) VALUES (:id, :member);", params)
Fetch a single row:
>>> db.fetch_one("SELECT * FROM beatles;")
{'id': 0, 'member': 'John'}
But you can also fetch n rows:
>>> db.fetch_many("SELECT * FROM beatles;", n=2)
[{'id': 0, 'member': 'John'}, {'id': 1, 'member': 'Paul'}]
Or all rows:
>>> db.fetch_all("SELECT * FROM beatles;")
[{'id': 0, 'member': 'John'},
{'id': 1, 'member': 'Paul'},
{'id': 2, 'member': 'George'},
{'id': 3, 'member': 'Ringo'}]
If you are using PostgreSQL with jsonb columns, you can use a helper function to serialize the parameter values:
>>> from databank.utils import serialize_params
>>> serialize_params({"member": "Ringo", "song": ["Don't Pass Me By", "Octopus's Garden"]})
{'member': 'Ringo', 'song': '["Don\'t Pass Me By", "Octopus\'s Garden"]'}
For both execute() and execute_many() you can pass an in_background keyword argument (which is by default False). If set to True, the query will be executed in the background in another thread and the method will return immediately the Thread object (i.e. non-blocking). You can call join() on that object to wait for the query to finish or just do nothing and go on:
>>> db.execute("INSERT INTO beatles (id, member) VALUES (:id, :member);", {"id": 4, "member": "Klaus"}, in_background=True)
<Thread(Thread-1 (_execute), started 140067398776512)>
Beware that if you are using in_background=True, you have to make sure that the connection pool size is large enough to handle the number of concurrent queries and that your program is running long enough if you are not explicitly waiting for the thread to finish. Also note that this might lead to a range of other issues like locking, reduced performance or even deadlocks. You also might want to set an explicit timeout for queries by passing e.g. {"options": "-c statement_timeout=60000"} for PostgreSQL when initializing the Database object to kill all queries taking longer than 60 seconds.
You can also organize SQL queries in an SQL file and load them into a QueryCollection:
/* @name insert_data */
INSERT INTO beatles (id, member) VALUES (:id, :member);
/* @name select_all_data */
SELECT * FROM beatles;
This idea is borrowed from PgTyped
A query must have a header comment with the name of the query. If a query name is not unique, the last query with the same name will be used. You can parse that file and load the queries into a QueryCollection:
>>> from databank import QueryCollection
>>> queries = QueryCollection.from_file("queries.sql")
and access the queries like in a dictionary:
>>> queries["insert_data"]
'INSERT INTO beatles (id, member) VALUES (:id, :member);'
>>> queries["select_all_data"]
'SELECT * FROM beatles;'
FAQs
Databank is an easy-to-use Python library for making raw SQL queries in a multi-threaded environment.
We found that databank demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
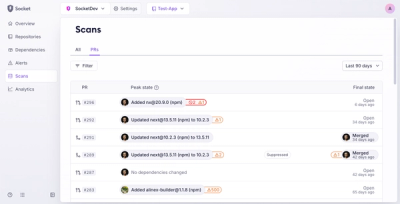
Product
Socket’s new Pull Request Stories give security teams clear visibility into dependency risks and outcomes across scanned pull requests.
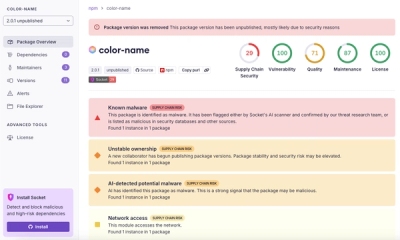
Research
/Security News
npm author Qix’s account was compromised, with malicious versions of popular packages like chalk-template, color-convert, and strip-ansi published.