 DeepSparse
DeepSparse
Sparsity-aware deep learning inference runtime for CPUs
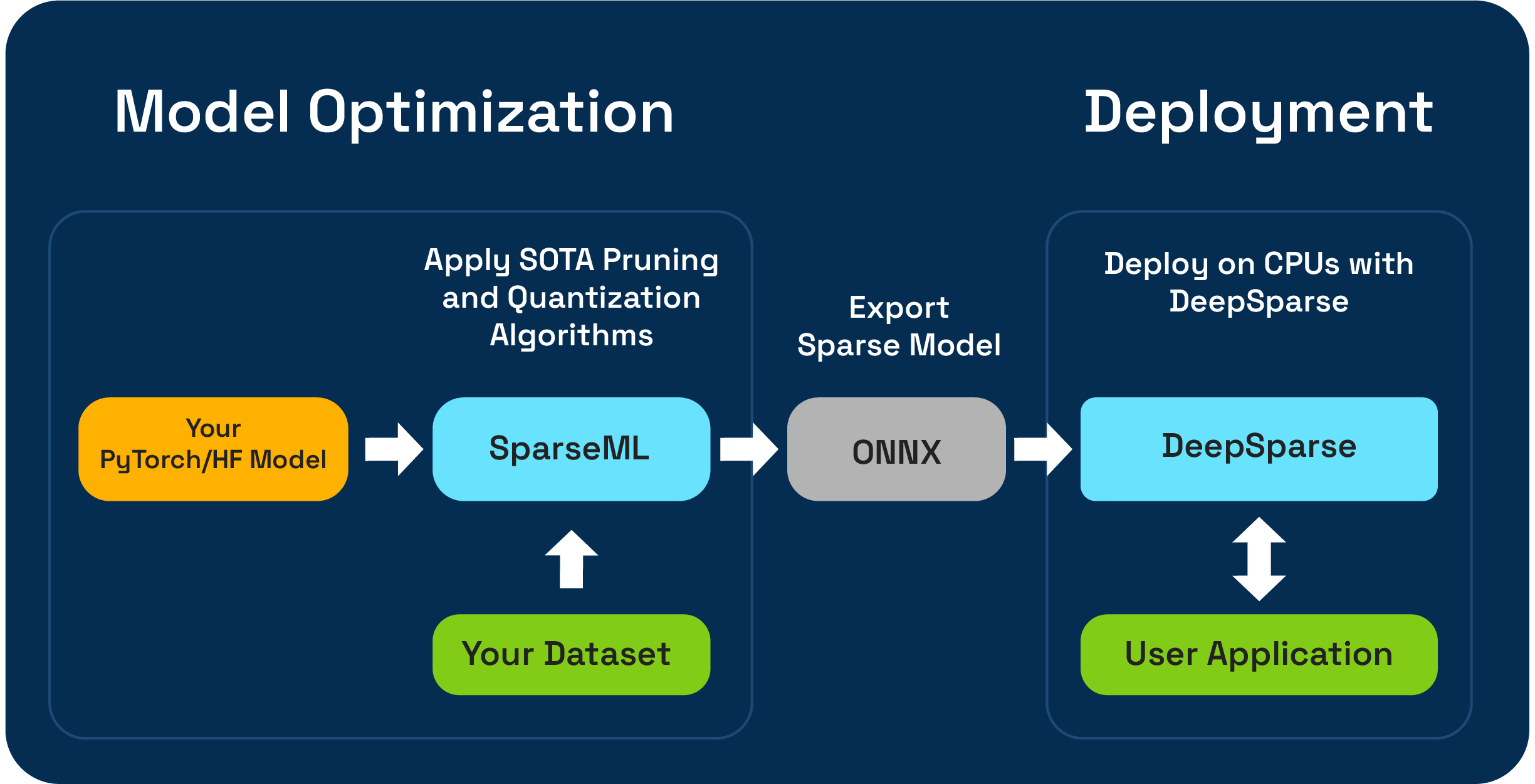
DeepSparse is a CPU inference runtime that takes advantage of sparsity to accelerate neural network inference. Coupled with SparseML, our optimization library for pruning and quantizing your models, DeepSparse delivers exceptional inference performance on CPU hardware.
✨NEW✨ DeepSparse LLMs
Neural Magic is excited to announce initial support for performant LLM inference in DeepSparse with:
- sparse kernels for speedups and memory savings from unstructured sparse weights.
- 8-bit weight and activation quantization support.
- efficient usage of cached attention keys and values for minimal memory movement.

Try It Now
Install (requires Linux):
pip install -U deepsparse-nightly[llm]
Run inference:
from deepsparse import TextGeneration
pipeline = TextGeneration(model="zoo:mpt-7b-dolly_mpt_pretrain-pruned50_quantized")
prompt="""
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: what is sparsity? ### Response:
"""
print(pipeline(prompt, max_new_tokens=75).generations[0].text)
Check out the TextGeneration documentation for usage details and get the latest sparsified LLMs on our HF Collection.
Sparsity :handshake: Performance
Developed in collaboration with IST Austria, our recent paper details a new technique called Sparse Fine-Tuning, which allows us to prune MPT-7B to 60% sparsity during fine-tuning without drop in accuracy. With our new support for LLMs, DeepSparse accelerates the sparse-quantized model 7x over the dense baseline:
Learn more about our Sparse Fine-Tuning research.
Check out the model running live on Hugging Face.
LLM Roadmap
Following this initial launch, we are rapidly expanding our support for LLMs, including:
- Productizing Sparse Fine-Tuning: Enable external users to apply sparse fine-tuning to their datasets via SparseML.
- Expanding model support: Apply our sparse fine-tuning results to Llama 2 and Mistral models.
- Pushing for higher sparsity: Improving our pruning algorithms to reach even higher sparsity.
Computer Vision and NLP Models
In addition to LLMs, DeepSparse supports many variants of CNNs and Transformer models, such as BERT, ViT, ResNet, EfficientNet, YOLOv5/8, and many more! Take a look at the Computer Vision and Natural Language Processing domains of SparseZoo, our home for optimized models.
Installation
Install via PyPI (optional dependencies detailed here):
pip install deepsparse
To experiment with the latest features, there is a nightly build available using pip install deepsparse-nightly or you can clone and install from source using pip install -e path/to/deepsparse.
System Requirements
For those using Mac or Windows, we recommend using Linux containers with Docker.
Deployment APIs
DeepSparse includes three deployment APIs:
- Engine is the lowest-level API. With Engine, you compile an ONNX model, pass tensors as input, and receive the raw outputs.
- Pipeline wraps the Engine with pre- and post-processing. With Pipeline, you pass raw data and receive the prediction.
- Server wraps Pipelines with a REST API using FastAPI. With Server, you send raw data over HTTP and receive the prediction.
Engine
The example below downloads a 90% pruned-quantized BERT model for sentiment analysis in ONNX format from SparseZoo, compiles the model, and runs inference on randomly generated input. Users can provide their own ONNX models, whether dense or sparse.
from deepsparse import Engine
zoo_stub = "zoo:nlp/sentiment_analysis/obert-base/pytorch/huggingface/sst2/pruned90_quant-none"
compiled_model = Engine(model=zoo_stub, batch_size=1)
inputs = compiled_model.generate_random_inputs()
output = compiled_model(inputs)
print(output)
Pipeline
Pipelines wrap Engine with pre- and post-processing, enabling you to pass raw data and receive the post-processed prediction. The example below downloads a 90% pruned-quantized BERT model for sentiment analysis in ONNX format from SparseZoo, sets up a pipeline, and runs inference on sample data.
from deepsparse import Pipeline
zoo_stub = "zoo:nlp/sentiment_analysis/obert-base/pytorch/huggingface/sst2/pruned90_quant-none"
sentiment_analysis_pipeline = Pipeline.create(
task="sentiment-analysis",
model_path=zoo_stub,
)
prediction = sentiment_analysis_pipeline("I love using DeepSparse Pipelines")
print(prediction)
Server
Server wraps Pipelines with REST APIs, enabling you to set up a model-serving endpoint running DeepSparse. This enables you to send raw data to DeepSparse over HTTP and receive the post-processed predictions. DeepSparse Server is launched from the command line and configured via arguments or a server configuration file. The following downloads a 90% pruned-quantized BERT model for sentiment analysis in ONNX format from SparseZoo and launches a sentiment analysis endpoint:
deepsparse.server \
--task sentiment-analysis \
--model_path zoo:nlp/sentiment_analysis/obert-base/pytorch/huggingface/sst2/pruned90_quant-none
Sending a request:
import requests
url = "http://localhost:5543/v2/models/sentiment_analysis/infer"
obj = {"sequences": "Snorlax loves my Tesla!"}
response = requests.post(url, json=obj)
print(response.text)
Additional Resources
Product Usage Analytics
DeepSparse gathers basic usage telemetry, including, but not limited to, Invocations, Package, Version, and IP Address, for Product Usage Analytics purposes. Review Neural Magic's Products Privacy Policy for further details on how we process this data.
To disable Product Usage Analytics, run:
export NM_DISABLE_ANALYTICS=True
Confirm that telemetry is shut off through info logs streamed with engine invocation by looking for the phrase "Skipping Neural Magic's latest package version check."
Get In Touch
For more general questions about Neural Magic, complete this form.
License
Cite
Find this project useful in your research or other communications? Please consider citing:
@misc{kurtic2023sparse,
title={Sparse Fine-Tuning for Inference Acceleration of Large Language Models},
author={Eldar Kurtic and Denis Kuznedelev and Elias Frantar and Michael Goin and Dan Alistarh},
year={2023},
url={https://arxiv.org/abs/2310.06927},
eprint={2310.06927},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kurtic2022optimal,
title={The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models},
author={Eldar Kurtic and Daniel Campos and Tuan Nguyen and Elias Frantar and Mark Kurtz and Benjamin Fineran and Michael Goin and Dan Alistarh},
year={2022},
url={https://arxiv.org/abs/2203.07259},
eprint={2203.07259},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@InProceedings{
pmlr-v119-kurtz20a,
title = {Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks},
author = {Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan},
booktitle = {Proceedings of the 37th International Conference on Machine Learning},
pages = {5533--5543},
year = {2020},
editor = {Hal Daumé III and Aarti Singh},
volume = {119},
series = {Proceedings of Machine Learning Research},
address = {Virtual},
month = {13--18 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf},
url = {http://proceedings.mlr.press/v119/kurtz20a.html}
}
@article{DBLP:journals/corr/abs-2111-13445,
author = {Eugenia Iofinova and Alexandra Peste and Mark Kurtz and Dan Alistarh},
title = {How Well Do Sparse Imagenet Models Transfer?},
journal = {CoRR},
volume = {abs/2111.13445},
year = {2021},
url = {https://arxiv.org/abs/2111.13445},
eprinttype = {arXiv},
eprint = {2111.13445},
timestamp = {Wed, 01 Dec 2021 15:16:43 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-13445.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
All Thanks To Our Contributors





