
Argilla
Work on data together, make your model outputs better!







Argilla is a collaboration platform for AI engineers and domain experts that require high-quality outputs, full data ownership, and overall efficiency.
If you just want to get started, we recommend our UI demo or our 2-click deployment quick start. Curious, and want to know more? Read our documentation.
Why use Argilla?
Whether you are working on monitoring and improving complex generative tasks involving LLM pipelines with RAG, or you are working on a predictive task for things like AB-testing of span- and text-classification models. Our versatile platform helps you ensure your data work pays off.
Improve your AI output quality through data quality
Compute is expensive and output quality is important. We help you focus on data, which tackles the root cause of both of these problems at once. Argilla helps you to achieve and keep high-quality standards for your data. This means you can improve the quality of your AI output.
Take control of your data and models
Most AI platforms are black boxes. Argilla is different. We believe that you should be the owner of both your data and your models. That's why we provide you with all the tools your team needs to manage your data and models in a way that suits you best.
Improve efficiency by quickly iterating on the right data and models
Gathering data is a time-consuming process. Argilla helps by providing a platform that allows you to interact with your data in a more engaging way. This means you can quickly and easily label your data with filters, AI feedback suggestions and semantic search. So you can focus on training your models and monitoring their performance.
We are an open-source community-driven project and we love to hear from you. Here are some ways to get involved:
-
Community Meetup: listen in or present during one of our bi-weekly events.
-
Slack: get direct support from the community.
-
Roadmap: plans change but we love to discuss those with our community so feel encouraged to participate.
What do people build with Argilla?
Open-source datasets and models
Argilla is a tool that can be used to achieve and keep high-quality data standards with a focus on NLP and LLMs. Our community uses Argilla to create amazing open-source datasets and models, and we love contributions to open-source ourselves too.
Internal Use cases
AI teams from companies like the Red Cross, Loris.ai and Prolific use Argilla to improve the quality and efficiency of AI projects. They shared their experiences in our AI community meetup.
- AI for good: the Red Cross presentation showcases how their experts and AI team collaborate by classifying and redirecting requests from refugees of the Ukrainian crisis to streamline the support processes of the Red Cross.
- Customer support: during the Loris meetup they showed how their AI team uses unsupervised and few-shot contrastive learning to help them quickly validate and gain labelled samples for a huge amount of multi-label classifiers.
- Research studies: the showcase from Prolific announced their integration with our platform. They use it to actively distribute data collection projects among their annotating workforce. This allows them to quickly and efficiently collect high-quality data for their research studies.
👨💻 Getting started
pip install argilla
First things first! You can install Argilla from pypi.
pip install argilla
Deploy Locally
docker run -d --name argilla -p 6900:6900 argilla/argilla-quickstart:latest
Deploy on Hugging Face Hub
HuggingFace Spaces now have persistent storage and this is supported from Argilla 1.11.0 onwards, but you will need to manually activate it via the HuggingFace Spaces settings. Otherwise, unless you're on a paid space upgrade, after 48 hours of inactivity the space will be shut off and you will lose all the data. To avoid losing data, we highly recommend using the persistent storage layer offered by HuggingFace.
After this, we can connect to our server.
Connect to the Server
Once you have deployed Argilla, we will connect to the server.
import argilla as rg
rg.init(
api_url="argilla-api-url",
api_key="argilla-api-key"
workspace="argilla-workspace"
)
After this, you can start using Argilla, so you can create a dataset and add records to it. We use the FeedbackDataset as an example, but you can use any of the other datasets available in Argilla. You can find more information about the different datasets here.
Create workspace
Once you have connected to the server, we will create a workspace for datasets.
workspace = rg.Workspace.create("new-workspace")
After this, you can assign users to the workspace, this will allow the datasets to appear in the UI for that user.
users = [u for u in rg.User.list() if u.role == "annotator"]
for user in users:
workspace.add_user(user)
Configure datasets
import argilla as rg
dataset = rg.FeedbackDataset(
guidelines="Please, read the question carefully and try to answer it as accurately as possible.",
fields=[
rg.TextField(name="question"),
rg.TextField(name="answer"),
],
questions=[
rg.RatingQuestion(
name="answer_quality",
description="How would you rate the quality of the answer?",
values=[1, 2, 3, 4, 5],
),
rg.TextQuestion(
name="answer_correction",
description="If you think the answer is not accurate, please, correct it.",
required=False,
),
]
)
remote_dataset = dataset.push_to_argilla(name="my-dataset", workspace="my-workspace")
Add records
import argilla as rg
record = rg.FeedbackRecord(
fields={
"question": "Why can camels survive long without water?",
"answer": "Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time."
},
metadata={"source": "encyclopedia"},
external_id='rec_1'
)
remote_dataset.add_records(record)
And that's it, you now have your first dataset ready. You can begin annotating it or embark on other related tasks.
Query datasets
import argilla as rg
filtered_dataset = dataset.filter_by(response_status="submitted")
Semantic search
import argilla as rg
similar_records = ds.find_similar_records(
vector_name="my_vector",
value=embedder_model.embeddings("My text is here")
)
similar_records = ds.find_similar_records(
vector_name="my_vector",
record=ds.records[0],
max_results=5
)
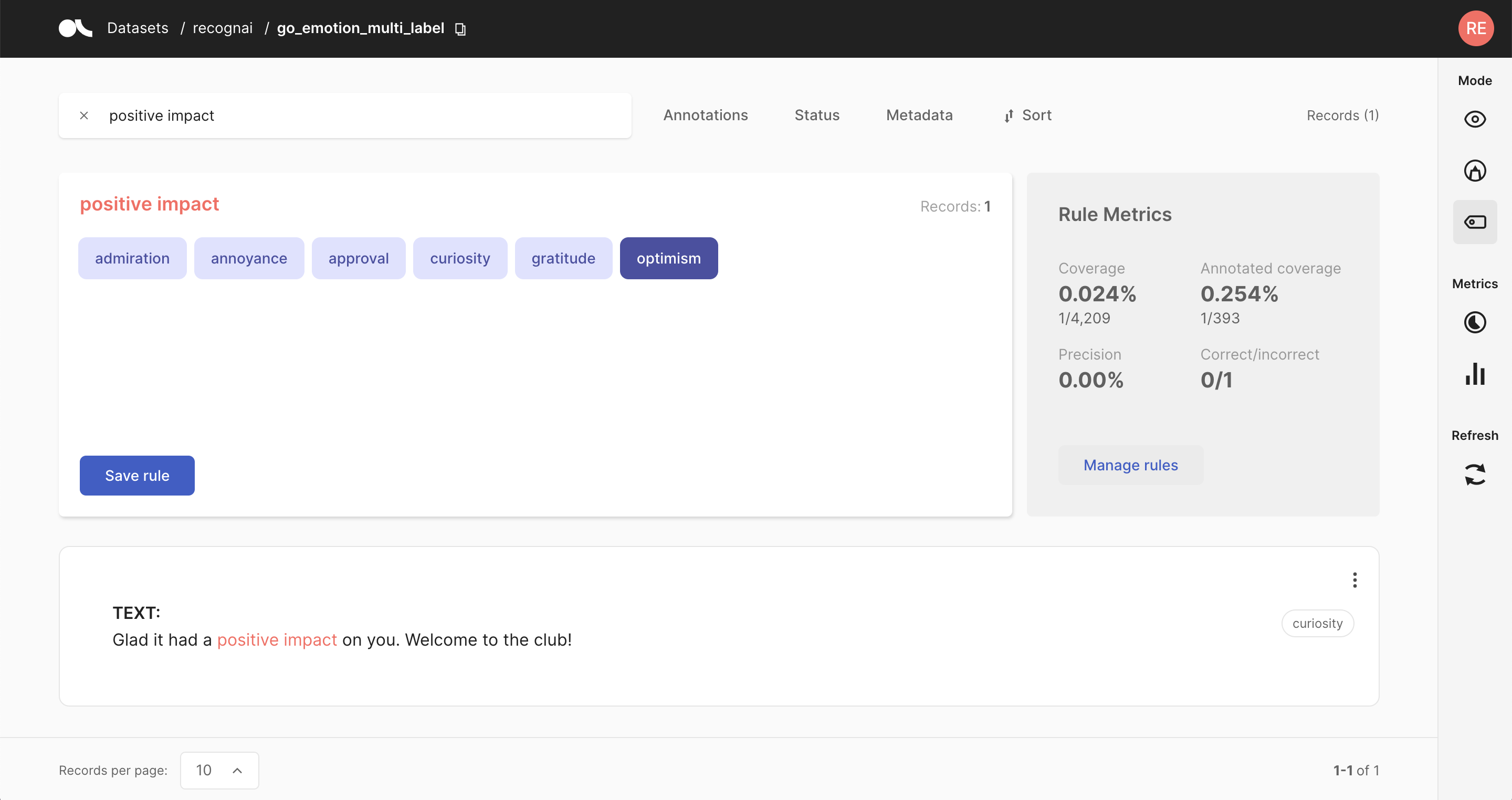
Weak supervision
from argilla.labeling.text_classification import add_rules, Rule
rule = Rule(query="positive impact", label="optimism")
add_rules(dataset="go_emotion", rules=[rule])
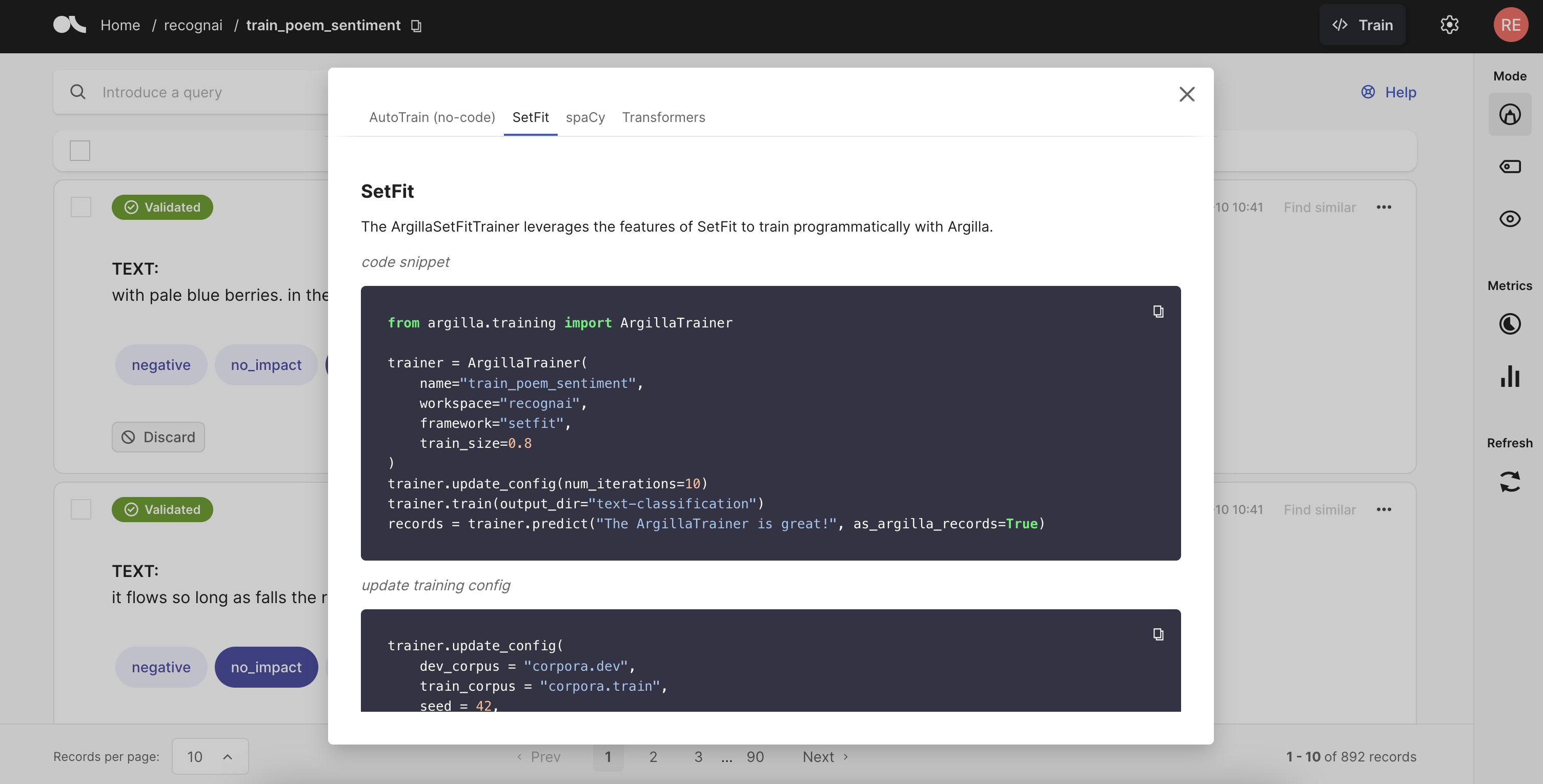
Train models
from argilla.training import ArgillaTrainer
trainer = ArgillaTrainer(
name="my_dataset",
workspace="my_workspace",
framework="my_framework",
model="my_framework_model",
train_size=0.8,
seed=42,
limit=10,
query="my-query"
)
trainer.update_config()
trainer.train()
records = trainer.predict(["my-text"], as_argilla_records=True)
🥇 Contributors
We love contributors and have launched a collaboration with JustDiggit to hand out our very own bunds and help the re-greening of sub-Saharan Africa. To help our community with the creation of contributions, we have created our developer and contributor docs. Additionally, you can always schedule a meeting with our Developer Advocacy team so they can get you up to speed.




