

Nevergrad - A gradient-free optimization platform

nevergrad is a Python 3.8+ library. It can be installed with:
pip install nevergrad
More installation options, including windows installation, and complete instructions are available in the "Getting started" section of the documentation.
You can join Nevergrad users Facebook group here.
Minimizing a function using an optimizer (here NGOpt) is straightforward:
import nevergrad as ng
def square(x):
return sum((x - .5)**2)
optimizer = ng.optimizers.NGOpt(parametrization=2, budget=100)
recommendation = optimizer.minimize(square)
print(recommendation.value)
>>> [0.49971112 0.5002944]
nevergrad can also support bounded continuous variables as well as discrete variables, and mixture of those.
To do this, one can specify the input space:
import nevergrad as ng
def fake_training(learning_rate: float, batch_size: int, architecture: str) -> float:
return (learning_rate - 0.2)**2 + (batch_size - 4)**2 + (0 if architecture == "conv" else 10)
parametrization = ng.p.Instrumentation(
learning_rate=ng.p.Log(lower=0.001, upper=1.0),
batch_size=ng.p.Scalar(lower=1, upper=12).set_integer_casting(),
architecture=ng.p.Choice(["conv", "fc"])
)
optimizer = ng.optimizers.NGOpt(parametrization=parametrization, budget=100)
recommendation = optimizer.minimize(fake_training)
print(recommendation.kwargs)
>>> {'learning_rate': 0.1998, 'batch_size': 4, 'architecture': 'conv'}
Learn more on parametrization in the documentation!
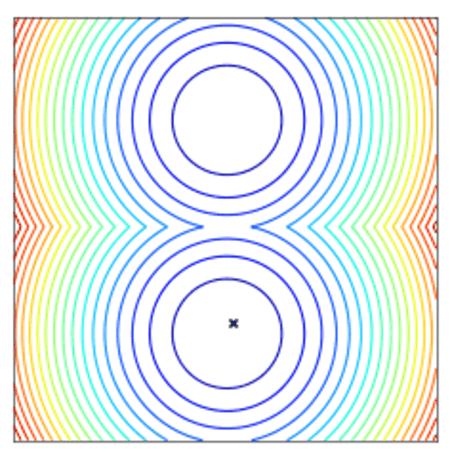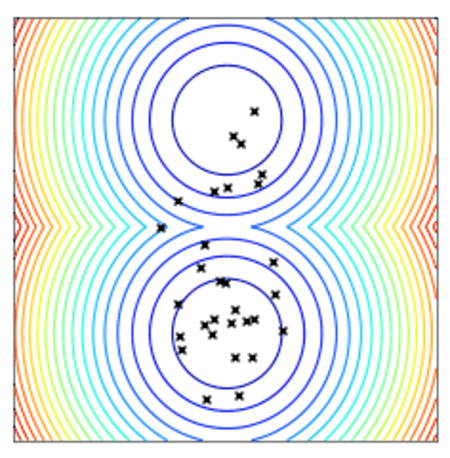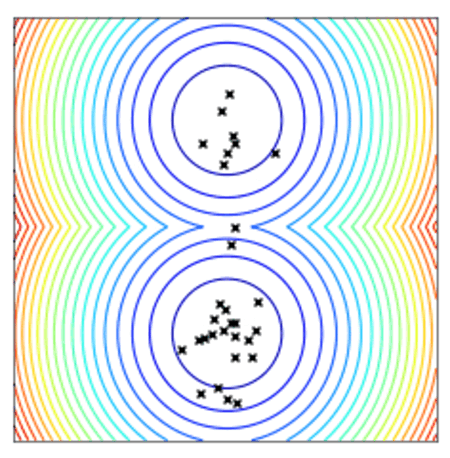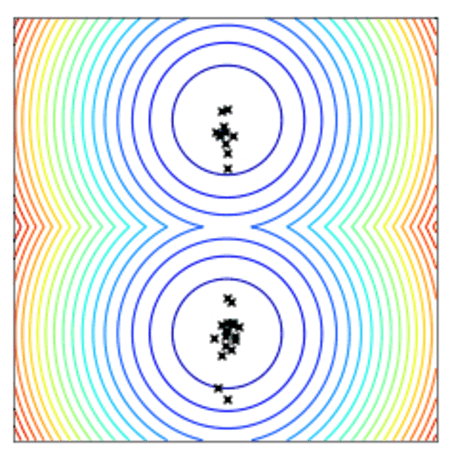
Convergence of a population of points to the minima with two-points DE.
Documentation
Check out our documentation! It's still a work in progress, so don't hesitate to submit issues and/or pull requests (PRs) to update it and make it clearer!
The last version of our data and the last version of our PDF report.
Citing
@misc{nevergrad,
author = {J. Rapin and O. Teytaud},
title = {{Nevergrad - A gradient-free optimization platform}},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://GitHub.com/FacebookResearch/Nevergrad}},
}
License
nevergrad is released under the MIT license. See LICENSE for additional details about it.
See also our Terms of Use and Privacy Policy.



