Product
Introducing License Enforcement in Socket
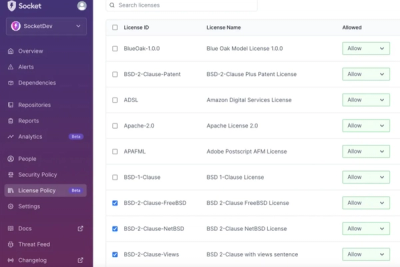
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
This package contains scraping tools and sentiment analyzers for a sentiment analysis project focused on news headlines about US presidential candidates in the 2020 election. See more at sentimentr.nmbroad.com or the analysis at nmbroad.com/sentimentr/
Usage
Background
Models
Scraping Tools
This package makes use of multiple environment variables to connect to the database. Here are the fields that need to be filled in:
DB_DIALECT=
DB_USERNAME=
DB_PASSWORD=
DB_ENDPOINT=
DB_PORT=
DB_NAME=
DB_URL=${DB_DIALECT}://${DB_USERNAME}:${DB_PASSWORD}@${DB_ENDPOINT}:${DB_PORT}/${DB_NAME}
DB_TABLE_NAME=
NEWS_API_KEY=
LSTM_PKL_MODEL_DIR=
LSTM_PKL_FILENAME=
The only supported LSTM model type is a fastai.Learner that has been exported using the export function into a .pkl file.
Set up a database, local is fine. Put the database information in a .env file and put in the working directory. Get a NewsAPI key here or skip to this section.
Add key to .env file.
First make sure that the environment variables are loaded.
from dotenv import load_dotenv
load_dotenv()
Next load in the tool
from sentinews.api_tool import NEWSAPI
Decide what time period to look at. Keep in mind that the free version of NewsAPI only allows for searching as far back as 30 days from today. Be sure to use timezone aware datetime objects.
from datetime import datetime, timedelta, timezone
# Date closer to present
end_date = datetime.now(tz=timezone.utc)
# Date further back in time
start_date = end_date - timedelta(days=10)
Initialize NEWSAPI object and start it up!
news_api = NEWSAPI(start_date=start_date, end_date=end_date)
news_api.start()
First make sure that the environment variables are loaded.
from dotenv import load_dotenv
load_dotenv()
Next load in the tool/tools
from sentinews.api_tool import CNN, FOX, NYT
Decide what time period to look at. Be sure to use timezone aware datetime objects.
from datetime import datetime, timedelta, timezone
# Date closer to present
end_date = datetime.now(tz=timezone.utc)
# Date further back in time
start_date = end_date - timedelta(days=10)
Initialize and start
cnn = CNN(start_date=start_date, end_date=end_date)
cnn.start()
I thought it would be interesting to see if trends in sentiment toward candidates could be seen in news headlines. Even though journalism is meant to be objective, small amounts of subjectivity can show up now and again. Most people know that CNN and Fox News are on opposite sides of the political viewpoint spectrum. CNN is the more liberal one and Fox the more conservative.
sentinews.models contains 3 models currently (TextBlob, VADER, LSTM), with a 4th (BERT) on the way. TextBlob and Vader are pre-existing tools with sentiment analysis functionality, and the LSTM and BERT models are trained by me.
TextBlob's model is trained with an nltk NaiveBayesClassifier on IMDB data (nltk.corpus.movie_reviews). This model uses the frequency of certain words to determine the probaility of the text being positive or negative. A Naive Bayes Model works by finding the empirical probability of a piece of label having certain features, the probability of the features, and the probability of the label. These all get combined using Bayes rule to find the probability of a label given features. While news headlines and movie reviews should be quite different, a movie review does contain the reviewers feelings about what they thought of the movie. That is, there is some overlap between the language used to express positive and negative emotions in both.
VADER's model is a lexicon approach using social media posts from Twitter. It trained to understanding emoticons (e.g. :-) ), punctuation (!!!), slang (nah) and popular acronyms (LOL). In the context of this project, the headlines will, most likely, not contain emoticons, slang or popular acronyms; however, this model sure to gauge some level of emotion in the texts.
The LSTM model is built by me and follows the Universal Language Model Fine-tuning (ULMFiT) technique used by Jeremy Howard. It is essentially the equivalent of transfer learning in computer vision. It starts with a well-trained language model, such as the AWD-LSTM, and then it trains it's language model on news-related text. The model then get's trained for sentiment analysis on news headlines. I personally hand-labeled hundreds of articles. The hope is that there is fundamental language understanding in the base models and the last layers help it understand the specific task of gauging sentiment in news headlines. Moreover, this method requires very little supervised training on my part, making it ideal.
Though not implemented here yet, BERT is the first prominent archtecture using a transformer architecture. Transformers enable text understanding of an entire sentence at once, rather than the sequential nature of RNNs and LSTMs. In that sense, they are considered bi-directional (the B in BERT), and the transformer is trained by guessing the missing word in a sentence, that is, looking one direction from the word and also a second, opposite direction.
The scraping toolkit starts with wrappers for the APIs of CNN, The New York Times, and Fox News. There is additional support for NewsAPI to get even more headlines from other sources, but to constrain the problem initially, just those main three are used. NewsAPI does make it convenient to get recent headlines, but the free account can only search 30 days in the past. Searching beyond that requires the other APIs.
Using those APIs a large number of urls can be generated. Scrapy is then used to go through each url to pull the body text. Analyzing the body of the article is an extension to this project and a task for the future. For now it just focuses on headlines.
FAQs
News title sentiment analysis
We found that senti-news demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
Product
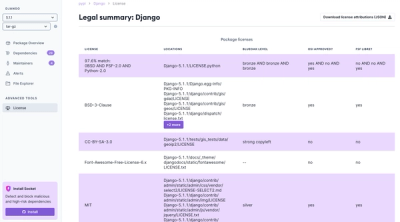
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
Product
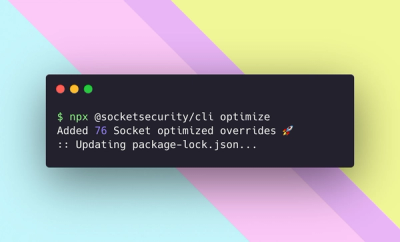
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.