🕵 Multi-agent modeling with large language models




surv_ai is a large language model framework designed for multi-agent modeling. This allows large-language models to be used as engines to power research into predictive modeling, bias analysis, and other forms of comparative analysis.
Multi-agent modeling involves generating statistical models based on the actions of multiple agents. In our case, these models are crafted by agents querying and processing text from a comprehensive data corpus. The agents then reason with the information extracted to produce a data point.
Given the stochastic nature of large language models, individual data points may vary. However, if a sufficient number of agents are employed, the generated models can effectively support comparative analysis.
They key idea here was inspired by the technique of bagging (bootstrap aggregating) in classical ensemble classifiers. The basic idea is that if you have a lot of weak learners with only limited information - in aggregate those weak learners can produce much higher quality results than a single weak learner with maximum information (or a bunch a weak learners with maximum information).
This technique appears to work better when each agent has access to a limited subset of the total information even when using language models with larger context windows.
The abstraction in this repository capable of producing a multi-agent data point is known as a Survey. A Survey takes a statement as input and returns the percentage of agents that agreed with it.
A more complex abstraction, called a Model, enables the variation of input parameters into a Survey to create a nuanced multi-agent model.
The data points produced serve as sentiment analysis against a text corpus, making them susceptible to the biases of both the large language models and the corpus itself. However, if the data source provided is quality - then the model produced can be high quality as well.
As advances in large language models and AI continue, multi-agent modeling may remain a valuable framework for classification and regression models. It also has the potential to become a useful data point for researchers investigating complex issues with numerous underlying variables.
📲 Installation
Package is available on PyPi:
pip install surv-ai
📻 Contact
For all inquiries, contact me at: daniel.balsam@survai.org
✅ Responsible use
The examples provided below are intended merely to illustrate potential applications of this framework; they are not to be considered scientifically rigorous.
Approaches like this have potential in guiding research and decision-making. However, it is crucial to rely on a diverse range of data points and to interpret each model cautiously.
I am always open to suggestions for further enhancing this approach.
📝 Basic usage
The two key abstractions in this repository are a Survey and a Model.
Executing the method Survey.conduct with a hypothesis will spin up a number of agents and seed them with some base knowledge. The agents are then asked to to assign a true or false value to the hypothesis provided.
class Survey:
def __init__(
self,
client: LargeLanguageModelClientInterface,
tool_belt: ToolBeltInterface,
n_agents=10,
max_concurrency=10,
max_knowledge_per_agent=3,
):
...
async def conduct(self, hypothesis: str) -> SurveyResponse:
...
A Model is an abstraction that allows one to conduct many surveys while changing some independent variable.
For example: one could could change the publish date of news articles that should be considered in the survey.
class Model:
def __init__(
self,
survey_class: type[SurveyInterface],
parameters: list[SurveyParameter],
max_concurrency: int = 1,
):
...
async def build(self, hypothesis: str) -> list[DataPoint]:
...
All abstractions implemented in this repository adhere to simple abstract interfaces - so you can easily build your own agents, surveys, and models.
🎓 Examples
All the below examples will be conducted with either GPT or Claude, and Google Custom Search. Links to relevant docs to get your own API keys:
OpenAI Docs /
Anthropic Docs /
Google Custom Search Docs
Comparing against a ground truth
Let's start by establishing the system's ability to figure out if information is true.
from surv_ai import (
GPTClient,
Survey,
ToolBelt,
GoogleCustomSearchTool,
Knowledge
)
client = GPTClient(os.environ["OPEN_AI_API_KEY"])
tool_belt = ToolBelt(
tools=[
GoogleCustomSearchTool(
google_api_key=os.environ["GOOGLE_API_KEY"],
google_search_engine_id=os.environ["GOOGLE_SEARCH_ENGINE_ID"],
start_date="2023-01-01",
end_date="2023-05-01",
n_pages=10,
)
]
)
base_knowledge = [
Knowledge(
text="It is currently 2023/05/01, all the articles are from 2023.",
source="Additional context",
),
]
survey = Survey(
client=client,
tool_belt=tool_belt,
base_knowledge=base_knowledge,
max_knowledge_per_agent=3,
n_agents=10,
)
await survey.conduct(
"California experienced a significant amount of rainfall this winter.",
) # This should always returns high a confidence agreement.
Executing this code should yield an output similar to: SurveyResponse(in_favor=10, against=0, undecided=0, error=0, percent_in_favor=1.0, uncertainty=0.0)
It's important to recognize that occasionally, one or two agents might incorrectly respond to a straightforward question like this. That's why we employ multiple agents in these systems - to counteract the randomness inherent in Large Language Models (LLMs).
To further test our hypothesis, we could also assert the contrary position and ensure we obtain the opposite value.
from surv_ai import (
GPTClient,
Survey,
ToolBelt,
GoogleCustomSearchTool,
Knowledge
)
client = GPTClient(os.environ["OPEN_AI_API_KEY"])
tool_belt = ToolBelt(
tools=[
GoogleCustomSearchTool(
google_api_key=os.environ["GOOGLE_API_KEY"],
google_search_engine_id=os.environ["GOOGLE_SEARCH_ENGINE_ID"],
start_date="2023-01-01",
end_date="2023-05-01",
n_pages=10,
)
]
)
base_knowledge = [
Knowledge(
text="It is currently 2023/05/01, all the articles are from 2023.",
source="Additional context",
),
]
survey = Survey(
client=client,
tool_belt=tool_belt,
base_knowledge=base_knowledge,
max_knowledge_per_agent=3,
n_agents=10,
)
await survey.conduct(
"California experienced little rainfall this winter.",
) # This should always returns a high confidence disagreement.
Executing this code should result in an output similar to: SurveyResponse(in_favor=0, against=10, undecided=0, error=0, percent_in_favor=0.0, uncertainty=0.0)
Comparing changes in sentiment over time
One thing we can use this tool for is measuring changes in sentiment overtime. GPT's training data ends in late 2021, so one way we can test our models with GPT is by looking at events that happened after GPT's training cutoff.
For instance, we can plot how sentiment regarding the United States' 2022 Midterm Elections evolved in the months leading up to it:
from surv_ai import (
GPTClient,
Model,
ToolBelt,
GoogleCustomSearchTool,
Knowledge,
Survey,
SurveyParameter
)
client = GPTClient(os.environ["OPEN_AI_API_KEY"])
def build_parameter(date_range: tuple[str, str]):
tool_belt = ToolBelt(
tools=[
GoogleCustomSearchTool(
google_api_key=os.environ["GOOGLE_API_KEY"],
google_search_engine_id=os.environ["GOOGLE_SEARCH_ENGINE_ID"],
n_pages=30,
start_date=date_range[0],
end_date=date_range[1],
max_concurrency=20,
),
],
)
base_knowledge = [
Knowledge(
text=f"It is currently {date_range[0]}. The included articles were published between {date_range[0]} and {date_range[1]}",
source="Additional context",
),
]
return SurveyParameter(
independent_variable=date_range[1],
kwargs={
"client": client,
"n_agents": 100,
"max_knowledge_per_agent":5,
"max_concurrency": 20,
"tool_belt": tool_belt,
"base_knowledge": base_knowledge,
},
)
date_ranges = [
('2022-05-01', '2022-06-01'),
('2022-06-01', '2022-07-01'),
('2022-07-01', '2022-08-01'),
('2022-08-01', '2022-09-01'),
('2022-09-01', '2022-10-01'),
('2022-10-01', '2022-11-05'),
]
model = Model(
Survey,
parameters=[build_parameter(date_range) for date_range in date_ranges],
)
democrat_results = await model.build(
"Democrats are favored to maintain control of the Senate in the 2022 November Midterm elections.",
)
We can also plot the inverted statement and observe opposite trend lines:
republican_results = await model.build(
"Republicans are favored to maintain control of the Senate in the 2022 November Midterm elections.",
)
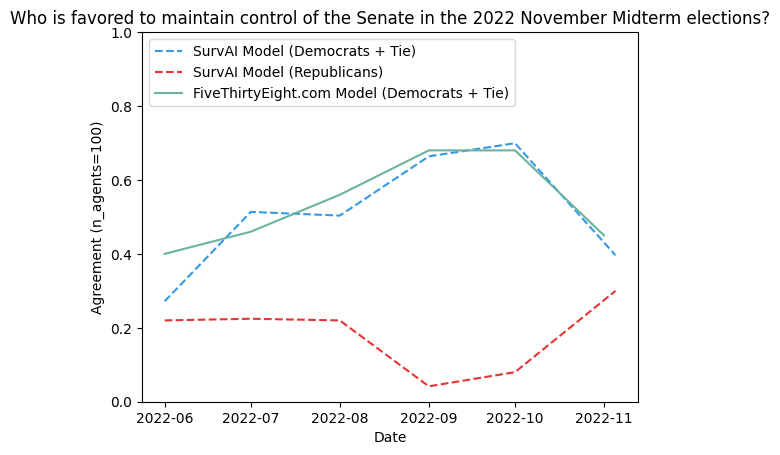
When compared with a leading model in political opinion polling, our model is presented as follows:
In this example, the agents crawled websites such as nytimes.com, wsj.com, abcnews.com, cnn.com, bloomberg.com, foxnews.com, economist.com, washingtonpost.com, and nbcnews.com. FiveThirtyEight data can be found here.
Pretty cool! Note that the outputs don't represent complementary probabilities due to nuances in how the models reason, and biases of the models and data sources, but we can observe trend lines that do mirror each other quite well.
Another example could involve plotting sentiments about the economy and using fluctuations in the S&P 500 as a benchmark for accuracy.
from surv_ai import (
GPTClient,
Model,
ToolBelt,
GoogleCustomSearchTool,
Knowledge,
Survey,
SurveyParameter
)
client = GPTClient(os.environ["OPEN_AI_API_KEY"])
def build_parameter(date_range: tuple[str, str]):
tool_belt = ToolBelt(
tools=[
GoogleCustomSearchTool(
google_api_key=os.environ["GOOGLE_API_KEY"],
google_search_engine_id=os.environ["GOOGLE_SEARCH_ENGINE_ID"],
n_pages=20,
start_date=date_range[0],
end_date=date_range[1]
),
],
)
base_knowledge = [
Knowledge(
text=f"It is currently {date_range[0]}. The included articles were published between {date_range[0]} and {date_range[1]}",
source="Additional context",
),
]
return SurveyParameter(
independent_variable=date_range[1],
kwargs={
"client": client,
"n_agents": 100,
"max_knowledge_per_agent":5,
"max_concurrency": 10,
"tool_belt": tool_belt,
"base_knowledge": base_knowledge,
},
)
date_ranges = [
('2021-09-01', '2022-01-01'),
('2022-01-01', '2022-03-01'),
('2022-03-01', '2022-06-01'),
('2022-06-01', '2022-09-01'),
('2022-09-01', '2023-01-01'),
('2023-01-01', '2023-03-01'),
('2023-03-01', '2023-06-01'),
]
model = Model(
Survey,
parameters=[build_parameter(date_range) for date_range in date_ranges],
)
results = await model.build(
"The United States economy looks like it is heading for a recession.",
)
This gives us the following graph:
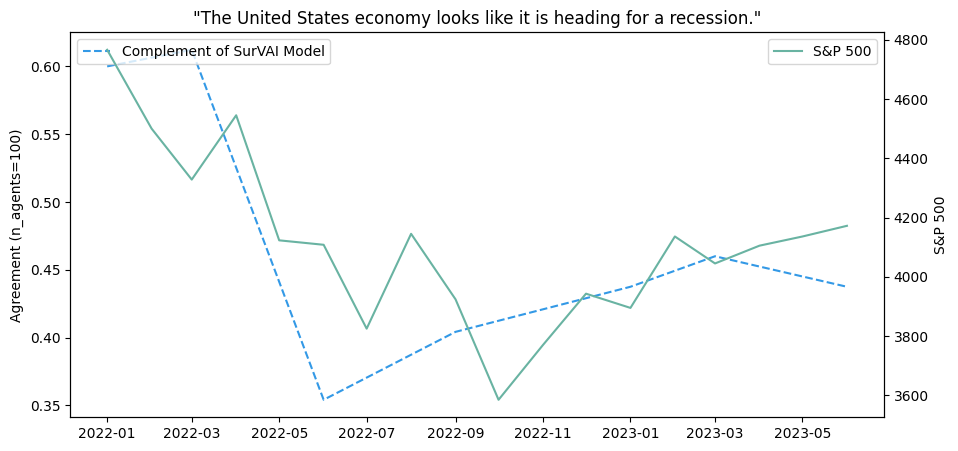
In this example, the agents crawled websites such as nytimes.com, wsj.com, abcnews.com, cnn.com, bloomberg.com, foxnews.com, economist.com, washingtonpost.com, and nbcnews.com. Please note that it is the complement of multi-agent model that is plotted. S&P data can be found here.
Measuring bias in a data corpus
A promising application of this technique is observing bias within a text corpus. For instance, we could create a model that uses different news sites as its independent variable to explore how the agents' conclusions might vary based on the data source utilized.
from surv_ai import (
GPTClient,
Model,
ToolBelt,
GoogleCustomSearchTool,
Knowledge,
Survey,
SurveyParameter
)
client = GPTClient(os.environ["OPEN_AI_API_KEY"])
def build_parameter(news_source: str):
tool_belt = ToolBelt(
tools=[
GoogleCustomSearchTool(
google_api_key=os.environ["GOOGLE_API_KEY"],
google_search_engine_id=os.environ["GOOGLE_SEARCH_ENGINE_ID"],
n_pages=20,
start_date="2023-05-01",
end_date="2023-06-01",
only_include_sources=[news_source]
),
],
)
base_knowledge = [
Knowledge(
text=f"It is currently 2023-06-01. The included articles were published between 2023-05-01 and 2023-06-01",
source="Additional context",
),
]
return SurveyParameter(
independent_variable=news_source,
kwargs={
"client": client,
"n_agents": 100,
"max_knowledge_per_agent":10,
"max_concurrency": 10,
"tool_belt": tool_belt,
"base_knowledge": base_knowledge,
},
)
news_sources = [
"nytimes.com",
"cnn.com",
"wsj.com",
"foxnews.com",
]
model = Model(
Survey,
parameters=[build_parameter(news_source) for news_source in news_sources],
)
results = await model.build(
"Republicans are responsible for the impending debt ceiling crisis."
)
This provides us with a scatter plot representing the above-mentioned news sources:
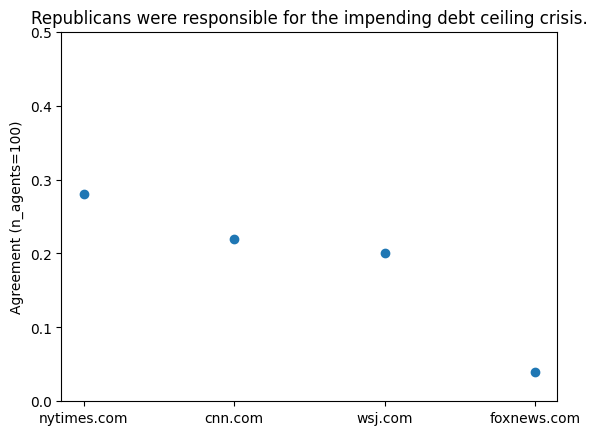
In this example, for each news site the agents looked only at articles published in May of 2023. Omitted publications did not have enough articles on the topic published to get reliable results.
Measuring biases in different large language models
Another promising method for measuring bias involves comparing biases across various large language models, provided they all receive identical input parameters.
from surv_ai import (
GPTClient,
AnthropicClient,
Model,
ToolBelt,
GoogleCustomSearchTool,
Knowledge,
Survey,
SurveyParameter,
LargeLanguageModelClientInterface
)
clients = [AnthropicClient(os.environ["ANTHROPIC_API_KEY"]), GPTClient(os.environ["OPEN_AI_API_KEY"])]
def build_parameter(client: LargeLanguageModelClientInterface):
tool_belt = ToolBelt(
tools=[
GoogleCustomSearchTool(
google_api_key=os.environ["GOOGLE_API_KEY"],
google_search_engine_id=os.environ["GOOGLE_SEARCH_ENGINE_ID"],
n_pages=20,
start_date="2023-01-01",
end_date="2024-05-01",
max_concurrency=3,
)
],
)
base_knowledge = [
Knowledge(
text=f"It is currently 2023-06-01. The included articles were published between 2023-01-01 and 2023-06-01",
source="Additional context",
),
]
return SurveyParameter(
independent_variable=client.__class__.__name__,
kwargs={
"client": client,
"n_agents": 100,
"max_knowledge_per_agent":3,
"max_concurrency": 3,
"tool_belt": tool_belt,
"base_knowledge": base_knowledge,
},
)
model = Model(
Survey,
parameters=[build_parameter(client) for client in clients],
)
results = await model.build(
"OpenAI has been irresponsible in their handling of AI technology."
)
When we compare the results between Anthropic and OpenAI's models, the scatter plot appears as follows:
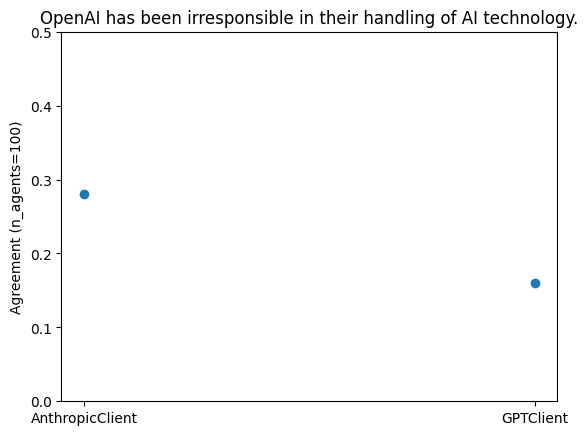
In this example, the agents crawled websites such as nytimes.com, wsj.com, abcnews.com, cnn.com, bloomberg.com, foxnews.com, economist.com, washingtonpost.com, and nbcnews.com for articles published in the first half of 2023.
In addition to querying news sources we can also query social media websites for sentiment. There are many uses for this, but one simple and fun one would be to try and see if we can predict who will win the Academy Award for best picture.
from surv_ai import (
GPTClient,
ToolBelt,
TwitterTool,
Knowledge,
Survey,
)
client = GPTClient(os.environ["OPEN_AI_API_KEY"])
films = [
"Everything Everywhere All At Once",
"All Quiet On the Western Front",
"The Banshees of Inisherin",
"The Fablemans",
"Tár",
"Top Gun: Maverick",
"Triangle of Sadness",
"Women Talking",
]
survey = Survey(
client,
n_agents=200,
tool_belt=ToolBelt(
tools=[
TwitterTool(
start_date="2023-01-01",
end_date="2023-03-11",
n_tweets=1000,
)
]
),
max_knowledge_per_agent=10,
base_knowledge=[
Knowledge(text="It is currently March 11th, 2023 and the Oscar's are tomorrow.", source="Additional context")
]
)
results = {}
for film in films:
results[film] = await survey.conduct(f"{film} is likely to win the Academy Award for Best Picture.")
Placing our results on a scatter plot, we get the correct result!
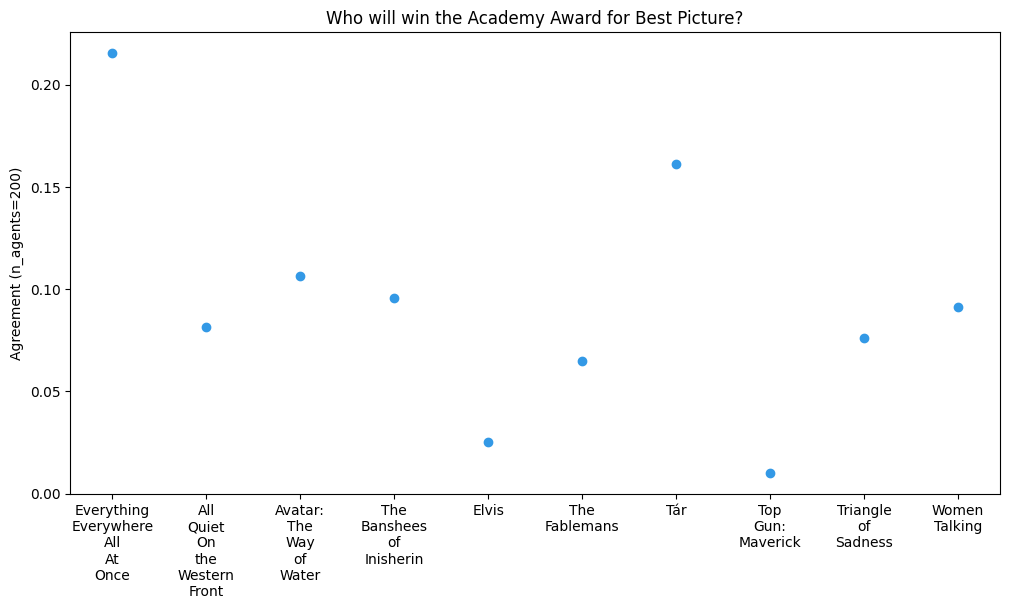 In this example, the agents were allowed to read Tweets up between January 1st 2023, and March 11th 2023 (the day before the Oscar's).
In this example, the agents were allowed to read Tweets up between January 1st 2023, and March 11th 2023 (the day before the Oscar's).
Sentiment on Twitter will not always be perfectly predictive of who will win an Academy Award, but it is an interesting way to try and predict outcomes.
🧠 Tips
Ultimately, a Survey is powered by a Large Language Model (LLM), which means that the survey hypothesis might require tuning, much like the general need to tune prompts. Here are some insights on crafting hypotheses.
In these systems, any ambiguity in the original hypothesis can lead to unexpected results. This often happens because the agents interpret the statement too literally, thus rejecting the precise phrasing of the statement.
Another useful tactic involves seeding base knowledge to the agents, which provides extra context to the problem. To revisit a previous example:
from surv_ai import (
GPTClient,
Survey,
ToolBelt,
GoogleCustomSearchTool,
Knowledge
)
client = GPTClient(os.environ["OPEN_AI_API_KEY"])
tool_belt = ToolBelt(
tools=[
GoogleCustomSearchTool(
google_api_key=os.environ["GOOGLE_API_KEY"],
google_search_engine_id=os.environ["GOOGLE_SEARCH_ENGINE_ID"],
start_date="2023-01-01",
end_date="2023-05-01",
n_pages=10,
)
]
)
base_knowledge = [
Knowledge(
text="It is currently 2023/05/01, all the articles are from 2023.",
source="Additional context",
),
]
survey = Survey(
client=client,
tool_belt=tool_belt,
base_knowledge=base_knowledge,
max_knowledge_per_agent=3,
n_agents=10,
)
await survey.conduct(
"California experienced a significant amount of rainfall this winter.",
) # This should always returns high a confidence agreement.
The base knowledge assists in keeping the agents on track. As GPT's training data concludes in 2021, without an additional prompt, GPT might assume it's still 2021, which would prevent it from evaluating the statement's validity accurately.
A bit of trial and error is often necessary, but you can debug more efficiently by reading the output of the agents. This is made possible by setting the log level:
from lib.log import logger, AgentLogLevel
logger.set_log_level(AgentLogLevel.OUTPUT) # Output from the agents will be logged
logger.set_log_level(AgentLogLevel.INTERNAL) # Agent internal "thoughts" will be logged
You may also prompt agents directly:
from surv_ai import (
GPTClient,
ReasoningAgent,
Knowledge
)
client = GPTClient(os.environ["OPEN_AI_API_KEY"])
agent = ReasoningAgent(client)
agent.teach_text("You can provide text information to an agent using `teach_text`.", "Context")
agent.teach_knowledge(
Knowledge(
text="You can similarly pass a knowledge object directly using `teach_knowledge`",
source="Context"
)
)
agent.prompt("There are multiple ways to teach an agent knowledge.")
If you are noticing a large number of errors, you may be hitting rate limits in your LLM API - you can get around this by adjusting the max_concurrency parameter in both your tools and Survey.
🤩 Inspiration
This project was inspired by numerous innovative projects and recent papers. Some of the inspirations for this project include:
- Generative Agents: Interactive Simulacra of Human Behavior.
- Large Language Models are Zero-Shot Reasoners
- AutoGPT
Additionally, thanks go to the multitude of researchers and engineers out there who are contributing to unlocking the power of these models!
📈 Next steps
A few directions I plan to explore with this project include:
- Use the AmbiFC fact-checking data set to benchmark the approach of this framework and compare all future changes against this benchmark: https://paperswithcode.com/paper/evidence-based-verification-for-real-world
- More documentation and use guides!
- Kicking off a development blog.
- More integrations with various helpful tools.
- More examples and use cases.
- Experimentation to further optimize performance.
🤝 Contribute
If you'd like to contribute then please reach out!



