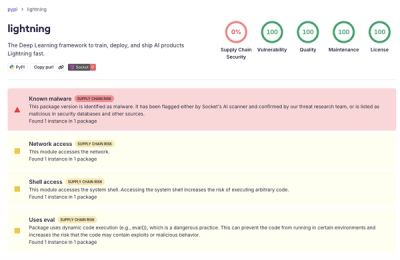
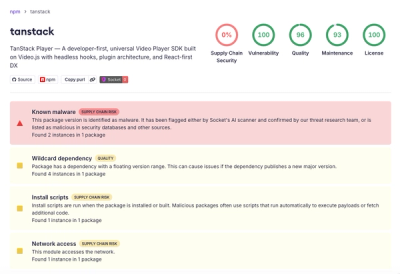
tpro
Transcript Processing! tpro takes JSON-formatted transcripts produced by
various speech-to-text services and converts them to various standardized
formats.
Installation and Usage
Non-pip Requirement: Stanford NER JAR
- download and unzip this
- put these files in in /usr/local/bin/:
- stanford-ner.jar
- classifiers/english.all.3class.distsim.crf.ser.gz
- you might have to update Java on Linux
Pip
$ pip install tpro
Usage
$ tpro --help
Usage: tpro [OPTIONS] TRANSCRIPT_DATA_PATH OUTPUT_PATH
[amazon|gentle|speechmatics|google] [universal|vo]
Options:
-p, --print-output pretty print the transcript, breaks pipeability
--language-code TEXT specify language, defaults to en-US.
--help Show this message and exit.
Example
$ cat transcript.json
{ "job": {
"lang": "en",
"user_id": 2152310,
"name": "recording.mp4",
"duration": 7,
"created_at": "Mon Nov 12 14:57:06 2018",
"id": 9871364
},
"speakers": [
{
"duration": "6.87",
"confidence": null,
"name": "M2",
"time": "5.98"
}
],
"words": [
{
"duration": "0.13",
"confidence": "0.670",
"name": "Hello",
"time": "5.98"
},
{
"duration": "0.45",
"confidence": "1.000",
"name": "there",
"time": "6.14"
}
]
}
$ tpro transcript.json converted_transcript.json speechmatics universal_transcript
[
{
"start": 5.98,
"end": 6.11,
"confidence": 0.67,
"word": "Hello",
"always_capitalized": false,
"punc_after": false,
"punc_before": false
},
{
"start": 6.14,
"end": 6.59,
"confidence": 1.0,
"word": "there",
"always_capitalized": false,
"punc_after": false,
"punc_before": false
}
]
☝☝☝ There\'s your transcript, which was saved to converted_transcript.json.
STT Services
Planned
Output Formats
Planned
- Word (
.doc, .docx)
- text files
- SRT (subtitles)
- Draft.js JSON