
Research
Security News
Malicious npm Package Targets Solana Developers and Hijacks Funds
A malicious npm package targets Solana developers, rerouting funds in 2% of transactions to a hardcoded address.
By Socket Research Team - Dec 02, 2024
Ruby web crawler that takes a url as input and produces a sitemap using a neo4j graph database - Nothing creepy about it.

##Installation ####Clone git clone https://github.com/udryan10/creepy-crawler.git && cd creepy-crawler ####Install Required Gems bundle install ####Install graph database rake neo4j:install ####Start graph database rake neo4j:start
####Requirements
##Usage ###Code ####Require require './creepy-crawler' ####Start a crawl Creepycrawler.crawl("http://example.com") ####Limit number of pages to crawl Creepycrawler.crawl("http://example.com", :max_page_crawl => 500) ####Extract some (potentially) useful statistics crawler = Creepycrawler.crawl("http://example.com", :max_page_crawl => 500) # list of broken links puts crawler.broken_links # list of sites that were visited puts crawler.visited_queue # count of crawled pages puts crawler.page_crawl_count
####Options DEFAULT_OPTIONS = { # whether to print crawling information :verbose => true, # whether to obey robots.txt :obey_robots => true, # maximum number of pages to crawl, value of nil will attempt to crawl all pages :max_page_crawl => nil, # should pages be written to the database. Likely only used for testing, but may be used if you only wanted to get at the broken_links data :graph_to_neo4j => true }
####Example
examples located in examples/ directory
###Command line # Crawl site ruby creepy-crawler.rb --site "http://google.com" # Get command options ruby creepy-crawler.rb --help
Note: If behind a proxy, export your proxy environment variables
export http_proxy=<proxy_host>; export https_proxy=<proxy_host>
###Docker For testing, I have included the ability to run the environment and a crawl inside of a docker container
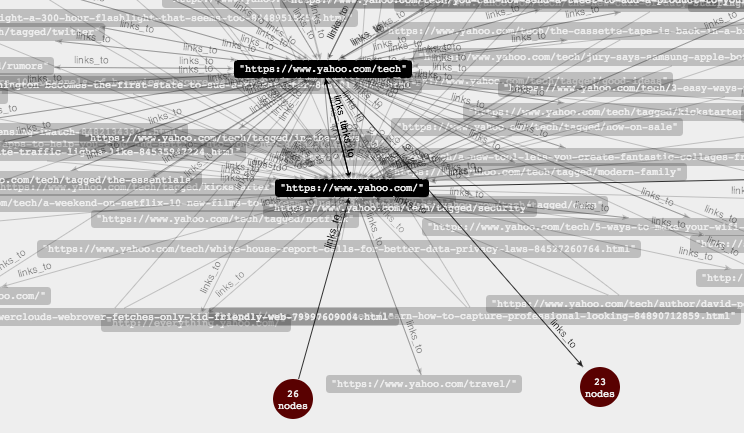
##Output creepy-crawler uses neo4j graph database to store and display the site map.
neo4j has a web interface for viewing and interacting with the graph data. When running on local host, visit: http://localhost:7474/webadmin/
Click the Data Browser tab
Enter Query to search for nodes (will search all nodes):
START root=node(*)
RETURN root
Click into a node
Click switch view mode at top right to view a graphical map
Note: to have the map display url names instead of node numbers, you must create a style
neo4j also has a full REST API for programatic access to the data
###Example Output Map
##TODO
FAQs
Unknown package
We found that creepy-crawler demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
Security News
A malicious npm package targets Solana developers, rerouting funds in 2% of transactions to a hardcoded address.

Security News
Research
Socket researchers have discovered malicious npm packages targeting crypto developers, stealing credentials and wallet data using spyware delivered through typosquats of popular cryptographic libraries.

Security News
Socket's package search now displays weekly downloads for npm packages, helping developers quickly assess popularity and make more informed decisions.