Product
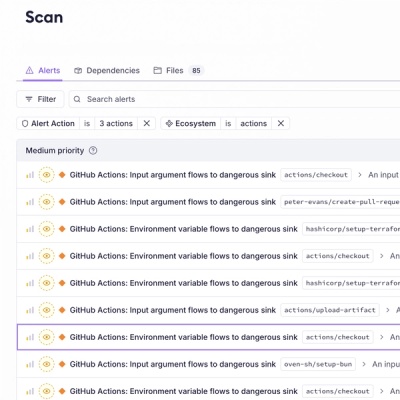
Introducing GitHub Actions Scanning Support
Detect malware, unsafe data flows, and license issues in GitHub Actions with Socket’s new workflow scanning support.
By Rakesh Chatrath, Greg Tystahl - Oct 23, 2025
@aws-c2a/engine
Advanced tools
The CDK Change Analyzer is a tool that enables detecting dangerous changes within CDK projects.
@aws-c2a/engine is a package that the toolkit consumes to extracts the difference between two
CloudFormation templates and produce a report of changes, customizable with a rules language.
The C2A architecture revolves around 4 main axis.

The platform-mapping directory holds parsers that transform an artifact into an
InfraModel.
The CloudFormation parser takes any CloudFormation template and generates an InfraModel
The type of CloudFormation entity (e.g. Resource, Parameter, Output)
gets mapped to the type of Component. In the case of CloudFormation resources, in particular,
their type gets mapped to the Component's subtype (i.e. an AWS Lambda Function resource
generates a Component with type Resource and subtype AWS::Lambda::Function).
The CloudFormation parser builds instances of CFEntity's subclasses, which have the responsibility of properly building the respective Components, Property Values, and outgoing Dependency Relationships.

The CFRef class extracts references to entities in an entity's declaration, from the used intrinsic functions and resources' DependsOn field.
The following image is an example of the created relationships:

Parsing CDK-generated CloudFormation templates begins by using the CloudFormation parser and adding a Component for each CDK Construct (extracted from the CloudFormation resources metadata). Afterwards, the stack Component and its Structural Relationships are removed and the CDK Construct Components are connected to the corresponding CloudFormation resource Components, as seen here:

The process of diffing InfraModels is contained in the model-diffing directory.
In the context of AWS CDK/CloudFormation, this is where we extract the operations (changes) that occurred between the old CloudFormation template and the new one.
The basic diff is created in model-diffing/diff-creator.ts. It groups components
of the same type and subtype and matches them based on their name and similarity.
This similarity is calculated by comparing the properties of each component,
in model-diffing/property-diff.ts.
Since detecting property operations and determining their similarity require the same
underlying logic, they are both done simultaneously in model-diffing/property-diff.ts.
A few notes on how this property diffing currently works:
When calculating similarity, there is currently no distinction between arrays and sets, so property array order is not considered. In other words, moving elements in an array as no effect on similarity. However, Move operations are still created if an element at index 0 is matched with an element at index 1, for example.
A weight is associated with a given similarity value, which is the number of primitive values of the structure it applies to. Consider the following:
// BEFORE
{
"a": { "b": "string", "c": "string" },
"d": "string"
}
// AFTER
{
"a": { "b": "string", "c": "string" },
"d": "str"
}
In this example, we see that the only difference between the two states is the value
of key d. For simplicity, let's define the similarity between the new and old value
for key d to be 0.5. The value of key a has not changed, thus has a similarity of
1.
We can calculate the similarity of the full properties by doing a weighted average.
a will have a weight of 4 (two keys and two values with similarity 1)d will have a weight of 1 (because it has only 1 primitive value).The similarity for this example is 1 * (4/5) + 0.5 * (1/5) = 0.9.
change-propagator.ts is responsible for taking the observed changes and propagating them:
Modified properties with componentUpdateType of REPLACEMENT or POSSIBLE_REPLACEMENT
generate an operation (change) of type Replace for their component.
Renamed Components have an new Replace operation.
Replace operations in Components with incoming Dependency Relationships generate an Update Operation to the source property of such relationships, indicating that a referenced value may have changed.
Aggregations are structures that group Operations (changes) in a tree-like structure. based on their characteristics, according to a given structure. These are used to collapse changes when presenting them in an interface. Take the following example:

These are resulting aggregations that narrow down operations by:
The characteristics that should be grouped at each level, and how, are described in
aggregations/component-operation/module-tree.ts. Aggregation modules define how to split
a group of operations and a module tree is a configuration of these modules that is used
to generate the aggregations.
Rules Processing is a core part of the engine, as it is what enables C2A to make decisions on aggregations and behaviors that arise in the diff. The rules processing can be broken down into three main stages.
Defining scope. Scope definition is the most complex part of rules processing, and it
acts to define the candidates for all identifiers defined in the let bindings. These candidates
are determined through traversing the diff tree and obtaining matches to the query provided as the
value to an identifier. To learn more about let bindings, see @aws-c2a/rules.
Verification. Verification happens after scope definition and mainly deals with conditions
specified in the where binding. All conditions have operators that will have a corresponding
handler in rules/operator-handlers directory. Verification is crucial for specificity and
drilling down to any type of behavior.
Extracting effect. Finally, in order to produce a meaningful change report, we attach any of our verified candidates for a targeted component to a specific effect (high risk, auto approve, etc.).
FAQs
The CDK Change Analyzer is a tool that enables detecting dangerous changes within CDK projects.
We found that @aws-c2a/engine demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Detect malware, unsafe data flows, and license issues in GitHub Actions with Socket’s new workflow scanning support.
Product
Add real-time Socket webhook events to your workflows to automatically receive pull request scan results and security alerts in real time.

Research
The Socket Threat Research Team uncovered malicious NuGet packages typosquatting the popular Nethereum project to steal wallet keys.