Security News
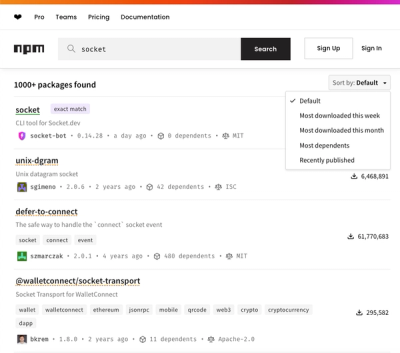
npm Updates Search Experience with New Objective Sorting Options
npm has a revamped search experience with new, more transparent sorting options—Relevance, Downloads, Dependents, and Publish Date.
By Sarah Gooding - Dec 05, 2024
@skiff-org/trawler
Advanced tools
The search library of Skiff. Originally forked from FlexSearch, this library trims down unwanted features and modernizes code for a smooth and easy-to-use search library.
Trawler removes many details and features from FlexSearch, to produce a trimmed-down, optimized, and modernized search library for our needs.
Trawler should be considered alpha-grade, software, so use with care
TODO make this trawler instead
npm install @skiff-org/trawler
There are two types of indices:
Index is a flat high performance index which stores id-content-pairs.Document is multi-field index which can store complex JSON documentsindex.add(id, text);
index.search(text);
index.search(text, limit);
index.search(text, options);
index.search(text, limit, options);
index.search(options);
document.add(doc);
document.add(id, doc);
document.search(text);
document.search(text, limit);
document.search(text, options);
document.search(text, limit, options);
document.search(options);
Index methods:
index.add(id, string): this*index.update(id, string): this *index.remove(id): this *index.search(string, limit?, options?): any[] *index.serialize(): Record<string, any>Index.deserialize(Record<string, any>): IndexDocument methods:
document.add(id?, document): this *document.update(id?, document): this *document.remove(id): this *document.search(string, limit?, options?): any *document.serialize(): Record<string, any>* For each of those methods there exist an asynchronous equivalent:
Async Version:
Async methods will return a Promise
| Option | Values | Description | Default |
| preset |
"memory" "performance" "match" "score" "default" |
The configuration profile as a shortcut or as a base for your custom settings. | "default" |
| tokenize |
"strict" "forward" "reverse" "full" |
The indexing mode (tokenizer). Choose one of the built-ins or pass a custom tokenizer function. | "strict" |
| cache |
Boolean Number | Enable/Disable and/or set capacity of cached entries. When passing a number as a limit the cache automatically balance stored entries related to their popularity. Note: When just using "true" the cache has no limits and growth unbounded. | false |
| resolution | Number | Sets the scoring resolution (default: 9). | 9 |
| context |
Boolean Context Options | Enable/Disable contextual indexing. When passing "true" as value it will take the default values for the context. | false |
| optimize | Boolean | When enabled it uses a memory-optimized stack flow for the index. | true |
| boost | function(arr, str, int) => float | A custom boost function used when indexing contents to the index. The function has this signature: Function(words[], term, index) => Float. It has 3 parameters where you get an array of all words, the current term and the current index where the term is placed in the word array. You can apply your own calculation e.g. the occurrences of a term and return this factor (<1 means relevance is lowered, >1 means relevance is increased).Note: this feature is currently limited by using the tokenizer "strict" only. | null |
| Language-specific Options and Encoding: | |||
| charset |
Charset Payload String (key) | Provide a custom charset payload or pass one of the keys of built-in charsets. | "latin" |
| language |
Language Payload String (key) | Provide a custom language payload or pass in language shorthand flag (ISO-3166) of built-in languages. | null |
| encode |
false "default" "simple" "balance" "advanced" "extra" function(str) => [words] | The encoding type. Choose one of the built-ins or pass a custom encoding function. | "default" |
| stemmer |
false String Function | false | |
| filter |
false String Function | false | |
| matcher |
false String Function | false | |
| Additional Options for Document Indexes: | |||
| worker | Boolean | Enable/Disable and set count of running worker threads. | false |
| document | Document Descriptor | Includes definitions for the document index and storage. |
| Option | Values | Description | Default |
| resolution | Number | Sets the scoring resolution for the context (default: 1). | 1 |
| depth |
false Number | Enable/Disable contextual indexing and also sets contextual distance of relevance. Depth is the maximum number of words/tokens away a term to be considered as relevant. | 1 |
| bidirectional | Boolean | Sets the scoring resolution (default: 9). | true |
| Option | Values | Description | Default |
| id | String | "id"" | |
| tag | false String | "tag" | |
| index | String Array<String> Array<Object> | ||
| store | Boolean String Array<String> | false |
| Option | Values | Description | Default |
| split |
false RegExp String |
The rule to split words when using non-custom tokenizer (built-ins e.g. "forward"). Use a string/char or use a regular expression (default: /\W+/). | /[\W_]+/ |
| rtl | Boolean | Enables Right-To-Left encoding. | false |
| encode | function(str) => [words] | The custom encoding function. | /lang/latin/default.js |
| Option | Values | Description |
| stemmer |
false String Function | Disable or pass in language shorthand flag (ISO-3166) or a custom object. |
| filter |
false String Function | Disable or pass in language shorthand flag (ISO-3166) or a custom array. |
| matcher |
false String Function | Disable or pass in language shorthand flag (ISO-3166) or a custom array. |
| Option | Values | Description | Default |
| limit | number | Sets the limit of results. | 100 |
| offset | number | Apply offset (skip items). | 0 |
| suggest | Boolean | Enables suggestions in results. | false |
| Option | Values | Description | Default |
| index | String Array<String> Array<Object> | Sets the document fields which should be searched. When no field is set, all fields will be searched. Custom options per field are also supported. | |
| tag | String Array<String> | Sets the document fields which should be searched. When no field is set, all fields will be searched. Custom options per field are also supported. | false |
| enrich | Boolean | Enrich IDs from the results with the corresponding documents. | false |
| bool | "and" "or" | Sets the used logical operator when searching through multiple fields or tags. | "or" |
Tokenizer affects the required memory also as query time and flexibility of partial matches. Try to choose the most upper of these tokenizer which fits your needs:
| Option | Description | Example | Memory Factor (n = length of word) |
| "strict" | index whole words | foobar | * 1 |
| "forward" | incrementally index words in forward direction | foobarfoobar | * n |
| "reverse" | incrementally index words in both directions | foobarfo obar | * 2n - 1 |
| "full" | index every possible combination | foobarf oobar | * n * (n - 1) |
Encoding affects the required memory also as query time and phonetic matches. Try to choose the most upper of these encoders which fits your needs, or pass in a custom encoder:
| Option | Description | False-Positives | Compression |
| false | Turn off encoding | no | 0% |
| "default" | Case in-sensitive encoding | no | 0% |
| "simple" | Case in-sensitive encoding Charset normalizations | no | ~ 3% |
| "balance" | Case in-sensitive encoding Charset normalizations Literal transformations | no | ~ 30% |
| "advanced" | Case in-sensitive encoding Charset normalizations Literal transformations Phonetic normalizations | no | ~ 40% |
| "extra" | Case in-sensitive encoding Charset normalizations Literal transformations Phonetic normalizations Soundex transformations | yes | ~ 65% |
| function() | Pass custom encoding via function(string):[words] |
var index = new Index();
Create a new index and choosing one of the presets:
var index = new Index("performance");
Create a new index with custom options:
var index = new Index({
charset: "latin:extra",
tokenize: "reverse",
resolution: 9
});
Create a new index and extend a preset with custom options:
var index = new FlexSearch({
preset: "memory",
tokenize: "forward",
resolution: 5
});
See all available custom options.
Every content which should be added to the index needs an ID. When your content has no ID, then you need to create one by passing an index or count or something else as an ID (a value from type number is highly recommended). Those IDs are unique references to a given content. This is important when you update or adding over content through existing IDs. When referencing is not a concern, you can simply use something simple like count++.
Index.add(id, string)
index.add(0, "John Doe");
Index.search(string | options, <limit>, <options>)
index.search("John");
Limit the result:
index.search("John", 10);
You can check if an ID was already indexed by:
if(index.contain(1)){
console.log("ID is already in index");
}
You can call each method in its async version, e.g. index.addAsync or index.searchAsync.
You can assign callbacks to each async function:
index.addAsync(id, content, function(){
console.log("Task Done");
});
index.searchAsync(query, function(result){
console.log("Results: ", result);
});
Or do not pass a callback function and getting back a Promise instead:
index.addAsync(id, content).then(function(){
console.log("Task Done");
});
index.searchAsync(query).then(function(result){
console.log("Results: ", result);
});
Or use async and await:
async function add(){
await index.addAsync(id, content);
console.log("Task Done");
}
async function search(){
const results = await index.searchAsync(query);
console.log("Results: ", result);
}
You can append contents to an existing index like:
index.append(id, content);
This will not overwrite the old indexed contents as it will do when perform index.update(id, content). Keep in mind that index.add(id, content) will also perform "update" under the hood when the id was already being indexed.
Appended contents will have their own context and also their own full resolution. Therefore, the relevance isn't being stacked but gets its own context.
Let us take this example:
index.add(0, "some index");
index.append(0, "some appended content");
index.add(1, "some text");
index.append(1, "index appended content");
When you query index.search("index") then you will get index id 1 as the first entry in the result, because the context starts from zero for the appended data (isn't stacked to the old context) and here "index" is the first term.
If you didn't want this behavior than just use the standard index.add(id, content) and provide the full length of content.
Index.update(id, string)
index.update(0, "Max Miller");
Index.remove(id)
index.remove(0);
A tokenizer split words/terms into components or partials.
Define a private custom tokenizer during creation/initialization:
var index = new FlexSearch({
tokenize: function(str){
return str.split(/\s-\//g);
}
});
The tokenizer function gets a string as a parameter and has to return an array of strings representing a word or term. In some languages every char is a term and also not separated via whitespaces.
Stemmer: several linguistic mutations of the same word (e.g. "run" and "running")
Filter: a blacklist of words to be filtered out from indexing at all (e.g. "and", "to" or "be")
Assign a private custom stemmer or filter during creation/initialization:
var index = new FlexSearch({
stemmer: {
// object {key: replacement}
"ational": "ate",
"tional": "tion",
"enci": "ence",
"ing": ""
},
filter: [
// array blacklist
"in",
"into",
"is",
"isn't",
"it",
"it's"
]
});
Using a custom filter, e.g.:
var index = new FlexSearch({
filter: function(value){
// just add values with length > 1 to the index
return value.length > 1;
}
});
Or assign stemmer/filters globally to a language:
Stemmer are passed as a object (key-value-pair), filter as an array.
FlexSearch.registerLanguage("us", {
stemmer: { /* ... */ },
filter: [ /* ... */ ]
});
Set the tokenizer at least to "reverse" or "full" when using RTL.
Just set the field "rtl" to true and use a compatible tokenizer:
var index = new Index({
encode: str => str.toLowerCase().split(/[^a-z]+/),
tokenize: "reverse",
rtl: true
});
Set a custom tokenizer which fits your needs, e.g.:
var index = FlexSearch.create({
encode: str => str.replace(/[\x00-\x7F]/g, "").split("")
});
You can also pass a custom encoder function to apply some linguistic transformations.
index.add(0, "一个单词");
var results = index.search("单词");
Assuming our document has a data structure like this:
{
"id": 0,
"content": "some text"
}
We can initialize an index like so:
const index = new Document({
document: {
id: "id",
index: ["content"]
}
});
index.add({
id: 0,
content: "some text"
});
The field id describes where the ID or unique key lives inside your documents. The default key gets the value id by default when not passed, so you can shorten the example from above to:
const index = new Document({
document: {
index: ["content"]
}
});
The member index has a list of fields which you want to be indexed from your documents. When just selecting one field, then you can pass a string. When also using default key id then this shortens to just:
const index = new Document({ document: "content" });
index.add({ id: 0, content: "some text" });
Assuming you have several fields, you can add multiple fields to the index:
var docs = [{
id: 0,
title: "Title A",
content: "Body A"
},{
id: 1,
title: "Title B",
content: "Body B"
}];
const index = new Document({
id: "id",
index: ["title", "content"]
});
You can pass custom options for each field:
const index = new Document({
id: "id",
index: [{
field: "title",
tokenize: "forward",
optimize: true,
resolution: 9
},{
field: "content",
tokenize: "strict",
optimize: true,
resolution: 5,
minlength: 3,
context: {
depth: 1,
resolution: 3
}
}]
});
Field options gets inherited when also global options was passed, e.g.:
const index = new Document({
tokenize: "strict",
optimize: true,
resolution: 9,
document: {
id: "id",
index:[{
field: "title",
tokenize: "forward"
},{
field: "content",
minlength: 3,
context: {
depth: 1,
resolution: 3
}
}]
}
});
Note: The context options from the field "content" also gets inherited by the corresponding field options, whereas this field options was inherited by the global option.
Assume the document array looks more complex (has nested branches etc.), e.g.:
{
"record": {
"id": 0,
"title": "some title",
"content": {
"header": "some text",
"footer": "some text"
}
}
}
Then use the colon separated notation "root:child:child" to define hierarchy within the document descriptor:
const index = new Document({
document: {
id: "record:id",
index: [
"record:title",
"record:content:header",
"record:content:footer"
]
}
});
Just add fields you want to query against. Do not add fields to the index, you just need in the result (but did not query against). For this purpose you can store documents independently of its index (read below).
When you want to query through a field you have to pass the exact key of the field you have defined in the doc as a field name (with colon syntax):
index.search(query, {
index: [
"record:title",
"record:content:header",
"record:content:footer"
]
});
Same as:
index.search(query, [
"record:title",
"record:content:header",
"record:content:footer"
]);
Using field-specific options:
index.search([{
field: "record:title",
query: "some query",
limit: 100,
suggest: true
},{
field: "record:title",
query: "some other query",
limit: 100,
suggest: true
}]);
You can perform a search through the same field with different queries.
When passing field-specific options you need to provide the full configuration for each field. They get not inherited like the document descriptor.
You need to follow 2 rules for your documents:
[ // <-- not allowed as document start!
{
"id": 0,
"title": "title"
}
]
{
"records": [ // <-- not allowed when ID or tag lives inside!
{
"id": 0,
"title": "title"
}
]
}
Here an example for a supported complex document:
{
"meta": {
"tag": "cat",
"id": 0
},
"contents": [
{
"body": {
"title": "some title",
"footer": "some text"
},
"keywords": ["some", "key", "words"]
},
{
"body": {
"title": "some title",
"footer": "some text"
},
"keywords": ["some", "key", "words"]
}
]
}
The corresponding document descriptor (when all fields should be indexed) looks like:
const index = new Document({
document: {
id: "meta:id",
tag: "meta:tag",
index: [
"contents[]:body:title",
"contents[]:body:footer",
"contents[]:keywords"
]
}
});
Again, when searching you have to use the same colon-separated-string from your field definition.
index.search(query, {
index: "contents[]:body:title"
});
This example breaks both rules from above:
[ // <-- not allowed as document start!
{
"tag": "cat",
"records": [ // <-- not allowed when ID or tag lives inside!
{
"id": 0,
"body": {
"title": "some title",
"footer": "some text"
},
"keywords": ["some", "key", "words"]
},
{
"id": 1,
"body": {
"title": "some title",
"footer": "some text"
},
"keywords": ["some", "key", "words"]
}
]
}
]
You need to apply some kind of structure normalization.
A workaround to such a data structure looks like this:
const index = new Document({
document: {
id: "record:id",
tag: "tag",
index: [
"record:body:title",
"record:body:footer",
"record:body:keywords"
]
}
});
function add(sequential_data){
for(let x = 0, data; x < sequential_data.length; x++){
data = sequential_data[x];
for(let y = 0, record; y < data.records.length; y++){
record = data.records[y];
index.add({
id: record.id,
tag: data.tag,
record: record
});
}
}
}
// now just use add() helper method as usual:
add([{
// sequential structured data
// take the data example above
}]);
You can skip the first loop when your document data has just one index as the outer array.
Just pass the document array (or a single object) to the index:
index.add(docs);
Update index with a single object or an array of objects:
index.update({
data:{
id: 0,
title: "Foo",
body: {
content: "Bar"
}
}
});
Remove a single object or an array of objects from the index:
index.remove(docs);
When the id is known, you can also simply remove by (faster):
index.remove(id);
On the complex example above, the field keywords is an array but here the markup did not have brackets like keywords[]. That will also detect the array but instead of appending each entry to a new context, the array will be joined into on large string and added to the index.
The difference of both kinds of adding array contents is the relevance when searching. When adding each item of an array via append() to its own context by using the syntax field[], then the relevance of the last entry concurrent with the first entry. When you left the brackets in the notation, it will join the array to one whitespace-separated string. Here the first entry has the highest relevance, whereas the last entry has the lowest relevance.
So assuming the keyword from the example above are pre-sorted by relevance to its popularity, then you want to keep this order (information of relevance). For this purpose do not add brackets to the notation. Otherwise, it would take the entries in a new scoring context (the old order is getting lost).
Also you can left bracket notation for better performance and smaller memory footprint. Use it when you did not need the granularity of relevance by the entries.
Search through all fields:
index.search(query);
Search through a specific field:
index.search(query, { index: "title" });
Search through a given set of fields:
index.search(query, { index: ["title", "content"] });
Same as:
index.search(query, ["title", "content"]);
Pass custom modifiers and queries to each field:
index.search([{
field: "content",
query: "some query",
limit: 100,
suggest: true
},{
field: "content",
query: "some other query",
limit: 100,
suggest: true
}]);
You can perform a search through the same field with different queries.
See all available field-search options.
Schema of the result-set:
fields[] => { field, result[] => { document }}
The first index is an array of fields the query was applied to. Each of this field has a record (object) with 2 properties "field" and "result". The "result" is also an array and includes the result for this specific field. The result could be an array of IDs or as enriched with stored document data.
A non-enriched result set now looks like:
[{
field: "title",
result: [0, 1, 2]
},{
field: "content",
result: [3, 4, 5]
}]
An enriched result set now looks like:
[{
field: "title",
result: [
{ id: 0, doc: { /* document */ }},
{ id: 1, doc: { /* document */ }},
{ id: 2, doc: { /* document */ }}
]
},{
field: "content",
result: [
{ id: 3, doc: { /* document */ }},
{ id: 4, doc: { /* document */ }},
{ id: 5, doc: { /* document */ }}
]
}]
When using pluck instead of "field" you can explicitly select just one field and get back a flat representation:
index.search(query, { pluck: "title", enrich: true });
[
{ id: 0, doc: { /* document */ }},
{ id: 1, doc: { /* document */ }},
{ id: 2, doc: { /* document */ }}
]
This result set is a replacement of "boolean search". Instead of applying your bool logic to a nested object, you can apply your logic by yourself on top of the result-set dynamically. This opens hugely capabilities on how you process the results. Therefore, the results from the fields aren't squashed into one result anymore. That keeps some important information, like the name of the field as well as the relevance of each field results which didn't get mixed anymore.
A field search will apply a query with the boolean "or" logic by default. Each field has its own result to the given query.
There is one situation where the bool property is being still supported. When you like to switch the default "or" logic from the field search into "and", e.g.:
index.search(query, {
index: ["title", "content"],
bool: "and"
});
You will just get results which contains the query in both fields. That's it.
Like the key for the ID just define the path to the tag:
const index = new Document({
document: {
id: "id",
tag: "tag",
index: "content"
}
});
index.add({
id: 0,
tag: "cat",
content: "Some content ..."
});
Your data also can have multiple tags as an array:
index.add({
id: 1,
tag: ["animal", "dog"],
content: "Some content ..."
});
You can perform a tag-specific search by:
index.search(query, {
index: "content",
tag: "animal"
});
This just gives you result which was tagged with the given tag.
Use multiple tags when searching:
index.search(query, {
index: "content",
tag: ["cat", "dog"]
});
This gives you result which are tagged with one of the given tag.
Multiple tags will apply as the boolean "or" by default. It just needs one of the tags to be existing.
This is another situation where the bool property is still supported. When you like to switch the default "or" logic from the tag search into "and", e.g.:
index.search(query, {
index: "content",
tag: ["dog", "animal"],
bool: "and"
});
You will just get results which contains both tags (in this example there is just one records which has the tag "dog" and "animal").
You can also fetch results from one or more tags when no query was passed:
index.search({ tag: ["cat", "dog"] });
In this case the result-set looks like:
[{
tag: "cat",
result: [ /* all cats */ ]
},{
tag: "dog",
result: [ /* all dogs */ ]
}]
By default, every query is limited to 100 entries. Unbounded queries leads into issues. You need to set the limit as an option to adjust the size.
You can set the limit and the offset for each query:
index.search(query, { limit: 20, offset: 100 });
You cannot pre-count the size of the result-set. That's a limit by the design of FlexSearch. When you really need a count of all results you are able to page through, then just assign a high enough limit and get back all results and apply your paging offset manually (this works also on server-side). FlexSearch is fast enough that this isn't an issue.
Only a document index can have a store. You can use a document index instead of a flat index to get this functionality also when only storing ID-content-pairs.
You can define independently which fields should be indexed and which fields should be stored. This way you can index fields which should not be included in the search result.
Do not use a store when: 1. an array of IDs as the result is good enough, or 2. you already have the contents/documents stored elsewhere (outside the index).
When the
storeattribute was set, you have to include all fields which should be stored explicitly (acts like a whitelist).
When the
storeattribute was not set, the original document is stored as a fallback.
This will add the whole original content to the store:
const index = new Document({
document: {
index: "content",
store: true
}
});
index.add({ id: 0, content: "some text" });
You can get indexed documents from the store:
var data = index.get(1);
You can update/change store contents directly without changing the index by:
index.set(1, data);
To update the store and also update the index then just use index.update, index.add or index.append.
When you perform a query, weather it is a document index or a flat index, then you will always get back an array of IDs.
Optionally you can enrich the query results automatically with stored contents by:
index.search(query, { enrich: true });
Your results look now like:
[{
id: 0,
doc: { /* content from store */ }
},{
id: 1,
doc: { /* content from store */ }
}]
This will add just specific fields from a document to the store (the ID isn't necessary to keep in store):
const index = new Document({
document: {
index: "content",
store: ["author", "email"]
}
});
index.add(id, content);
You can configure independently what should being indexed and what should being stored. It is highly recommended to make use of this whenever you can.
Here a useful example of configuring doc and store:
const index = new Document({
document: {
index: "content",
store: ["author", "email"]
}
});
index.add({
id: 0,
author: "Jon Doe",
email: "john@mail.com",
content: "Some content for the index ..."
});
You can query through the contents and will get back the stored values instead:
index.search("some content", { enrich: true });
Your results are now looking like:
[{
field: "content",
result: [{
id: 0,
doc: {
author: "Jon Doe",
email: "john@mail.com",
}
}]
}]
Both field "author" and "email" are not indexed.
Simply chain methods like:
var index = FlexSearch.create()
.addMatcher({'â': 'a'})
.add(0, 'foo')
.add(1, 'bar');
index.remove(0).update(1, 'foo').add(2, 'foobar');
Create an index and use the default context:
var index = new FlexSearch({
tokenize: "strict",
context: true
});
Create an index and apply custom options for the context:
var index = new FlexSearch({
tokenize: "strict",
context: {
resolution: 5,
depth: 3,
bidirectional: true
}
});
Only the tokenizer "strict" is actually supported by the contextual index.
The contextual index requires additional amount of memory depending on depth.
You need to initialize the cache and its limit during the creation of the index:
const index = new Index({ cache: 100 });
const results = index.searchCache(query);
A common scenario for using a cache is an autocomplete or instant search when typing.
When passing a number as a limit the cache automatically balance stored entries related to their popularity.
When just using "true" the cache is unbounded and perform actually 2-3 times faster (because the balancer do not have to run).
In order to serialize a document or index, call index.serialize(), which returns an object storing all the relevant properties of an index:
index.serialize() // -> { map: {...}, reg: {...}, ...}
If you want to write an index to a string, stringify this object:
const str = JSON.stringify(index.serialize());
Exporting data to the localStorage isn't really a good practice, but if size is not a concern than use it if you like. The export primarily exists for the usage in Node.js or to store indexes you want to delegate from a server to the client.
The size of the export corresponds to the memory consumption of the library. To reduce export size you have to use a configuration which has less memory footprint (use the table at the bottom to get information about configs and its memory allocation).
If you want to deserialize an object, call the Document.deserialize() or Index.deserialize() methods.
The Index.deserialize() is simply passed the output of the index.serialize() method:
const serialized = JSON.stringify(idx.serialize());
const deserialized = Index.deserialize(JSON.parse(serialized));
On the other hand, the Document.deserialize() method requires the document options required to re-create the document configuration
const serialized = JSON.stringify(idx.serialize());
const deserialized = Document.deserialize(JSON.parse(serialized), {
document: {
id: 'id',
field: ['text']
}
});
It is recommended to use numeric id values as reference when adding content to the index. The byte length of passed ids influences the memory consumption significantly. If this is not possible you should consider to use a index table and map the ids with indexes, this becomes important especially when using contextual indexes on a large amount of content.
Whenever you can, try to divide content by categories and add them to its own index, e.g.:
var action = new FlexSearch();
var adventure = new FlexSearch();
var comedy = new FlexSearch();
This way you can also provide different settings for each category. This is actually the fastest way to perform a fuzzy search.
To make this workaround more extendable you can use a short helper:
var index = {};
function add(id, cat, content){
(index[cat] || (
index[cat] = new FlexSearch
)).add(id, content);
}
function search(cat, query){
return index[cat] ?
index[cat].search(query) : [];
}
Add content to the index:
add(1, "action", "Movie Title");
add(2, "adventure", "Movie Title");
add(3, "comedy", "Movie Title");
Perform queries:
var results = search("action", "movie title"); // --> [1]
Split indexes by categories improves performance significantly.
Copyright 2018-2021 Nextapps GmbH, 2021– Skiff World, Inc.
Released under the Apache 2.0 License
FAQs
A modern search library for Skiff
The npm package @skiff-org/trawler receives a total of 1 weekly downloads. As such, @skiff-org/trawler popularity was classified as not popular.
We found that @skiff-org/trawler demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 8 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
npm has a revamped search experience with new, more transparent sorting options—Relevance, Downloads, Dependents, and Publish Date.

Security News
A supply chain attack has been detected in versions 1.95.6 and 1.95.7 of the popular @solana/web3.js library.

Research
Security News
A malicious npm package targets Solana developers, rerouting funds in 2% of transactions to a hardcoded address.