
Security News
MCP Steering Committee Launches Official MCP Registry in Preview
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
By Sarah Gooding - Sep 09, 2025

fsgdb is a graph like database based on the file system. Based on a root folder (or node), you can create subfolders/subnodes and attach data to each node by creating paresable files in each directory.
By allowing to merge data from parent nodes (think of: having a "blog" folder/node which contains metadata about your blog, which is then merged with each blog-entry-folder/sub-node), you can store data efficiently and deduplicated while maintaining a clear folder structure that is easily editable with standard editors.
At the moment, the following parsers are supported:
*.md) files and attaches the parsed HTML content to each node.markdown.<filename> = "<parsedMarkdown>"*.yml) files and attaches the parsed properties to each node.<filename> = { <parsedProperties> },
with the exception that the properties of the file metadata.yml are added directly to the node without the in-between <filename> object.*.jpg) files, reads out exif information and creates (if configured with createThumbnails: true) thumbnails.
Adds helper functions that return image/thumbnail data. Note that for generating thumbnails, GraphicsMagick/ImageMagick needs to be installed on the system.Hint: although the examples here are written in coffeescript, the module works with javascript as well.
The database is initialized by specifying a root directory and the list of parsers to use. Then, the directory can be scanned and data loaded.
FileSystemGraphDatabase = require('fsgdb').FileSystemGraphDatabase
graph = new FileSystemGraphDatabase({ path: './sampleApp/sampleData'})
graph.registerParser('MarkdownParser')
graph.registerParser('YamlParser')
loadingPromise = graph.load()
Based on the graph, the root node can be accessed and the tree can be traversed.
loadingPromise.then (rootNode) ->
# Check for a property
boolean = rootNode.hasProperty('propertyName')
# Get a property
value = rootNode.getProperty('propertyName')
# Merge properties with values from parents (useful for deduplication of common data)
mergedProperties = rootNode.flattenProperties()
# use on nodes with children
allLeaves = rootNode.getAllLeaves()
Instead of walking manually through nodes, queries can be used to filter efficiently. Queries are chainable.
Query = require('fsgdb').Query
q = new Query(rootNode)
# The most basic method is the .filter method, which expects a callback.
# This callback should return true or false if the given node passes the filter or not
q = q.filter (properties, node) -> return true
# Helper functions to simplify querying
# Query all nodes that have a property which contains a certain element:
q = q.whichContains('tags', 'technology')
# Or check for the existence of a property
q = q.withProperty('markdown')
#...that also must have a certain value
q = q.withProperty('date', '2015-12-31')
# Results can be given either as the direct results nodes (where the individual nodes
# might have children with different properties that do not match
# the query when properties are flattened)
nodes = q.resultNodes()
# Or get the leaves (nodes without children) with flattened properties to directly continue working with the
# combined data
nodes = q.resultLeaves()
FAQs
A file system graph database
We found that fsgdb demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
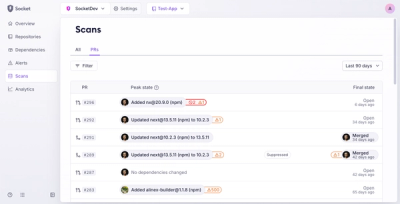
Product
Socket’s new Pull Request Stories give security teams clear visibility into dependency risks and outcomes across scanned pull requests.
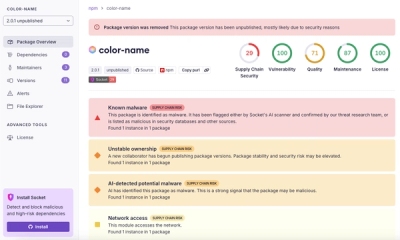
Research
/Security News
npm author Qix’s account was compromised, with malicious versions of popular packages like chalk-template, color-convert, and strip-ansi published.