GraphQL-Connections :diamond_shape_with_a_dot_inside:
Install
Install by referencing the github location and the release number:
npm install --save graphql-connections#v2.2.0
About
GraphQL-Connections helps handle the traversal of edges between nodes.
In a graph, nodes connect to other nodes via edges. In the relay graphql spec, multiple edges can be represented as a single Connection type, which has the signature:
type Connection {
pageInfo: {
hasNextPage: string
hasPreviousPage: string
startCursor: string
endCursor: string
},
edges: Array<{cursor: string; node: Node}>
}
A connection object is returned to a user when a query request asks for multiple child nodes connected to a parent node.
For example, a music artist has multiple songs. In order to get all the songs for an artist you would write the graphql query request:
query {
artist(id: 1) {
songs {
songName
songLength
}
}
}
However, sometimes you may only want a portion of the songs returned to you. To allow for this scenario, a connection is used to represent the response type of a song.
query {
artist(id: 1) {
songs {
pageInfo {
hasNextPage
hasPreviousPage
startCursor
endCursor
}
edges {
cursor
node {
songName
songLength
}
}
}
}
}
You can use the cursors (startCursor, endCursor, or cursor) to get the next set of edges.
query {
artist(id: 1) {
songs(next: 10, after: <endCursor>) {
pageInfo {
hasNextPage
hasPreviousPage
startCursor
endCursor
}
edges {
cursor
node {
songName
songLength
}
}
}
}
}
The above logic is controlled by the connectionManager. It can be added to a resolver to:
- Create a cursor for paging through a node's edges
- Handle movement through a node's edges using an existing cursor.
- Support multiple input types that can sort, group, limit, and filter the edges in a connection
Run locally
- Run the migrations
NODE_ENV=development npm run migrate:sqlite:latestNODE_ENV=development npm run migrate:mysql:latest
- Seed the database
NODE_ENV=development npm run seed:sqlite:runNODE_ENV=development npm run seed:mysql:run
- Run the dev server
npm run dev:sqlite (search is not supported)npm run dev:mysql (search IS supported :))
- Visit the GraphQL playground http://localhost:4000/graphql
- Run some queries!
query {
users(
first: 100
orderBy: "haircolor"
filter: {
and: [
{field: "id", operator: ">", value: "19990"}
{field: "age", operator: "<", value: "90"}
]
}
search: "random search term"
) {
pageInfo {
hasNextPage
hasPreviousPage
startCursor
endCursor
}
edges {
cursor
node {
username
lastname
id
haircolor
bio
}
}
}
}
query {
users(first: 10, after: "eyJmaXJzdFJlc3VsdElkIjoxOTk5MiwibGFzdFJlc3VsdE") {
pageInfo {
hasNextPage
hasPreviousPage
}
edges {
cursor
node {
username
lastname
id
haircolor
bio
}
}
}
}
How to use - Schema
1. Add input scalars to schema
Add the input scalars (First, Last, OrderBy, OrderDir, Before, After, Filter, Search) to your GQL schema.
At the very least you should add Before, After and First, Last because they allow you to move along the connection with a cursor.
type Query {
users(
first: First
last: Last
orderBy: OrderBy
orderDir: OrderDir
before: Before
after: After
filter: Filter
search: Search
): QueryUsersConnection
}
2. Add typeDefs to your schema
Manually
scalar: First
scalar: Last
scalar: OrderBy
scalar: OrderDir
scalar: Before
scalar: After
scalar: Filter
scalar: Search
type Query {
users(
first: First
last: Last
orderBy: OrderBy
orderDir: OrderDir
before: Before
after: After
filter: Filter
search: Search
): QueryUsersConnection
}
String interpolation
import {typeDefs} from 'graphql-connections'
const schema = `
${...typeDefs}
type Query {
users(
first: First
last: Last
orderBy: OrderBy
orderDir: OrderDir
before: Before
after: After
filter: Filter
search: Search
): QueryUsersConnection
}
`
During configuration
import {typeDefs as connectionTypeDefs} from 'graphql-connections'
const schema = makeExecutableSchema({
...
typeDefs: `${typeDefs} ${connectionTypeDefs}`
});
3. Add resolvers
In the resolver object
import {resolvers as connectionResolvers} from 'graphql-connections'
const resolvers = {
...connectionResolvers,
Query: {
users: {
....
}
}
}
During configuration
import {resolvers as connectionResolvers} from 'graphql-connections'
const schema = makeExecutableSchema({
...
resolvers: {...resolvers, ...connectionResolvers}
});
How to use - Resolvers
Short Tutorial
In short, this is what a resolver using the connectionManager will look like:
import {ConnectionManager, INode} from 'graphql-connections';
const resolver = async (obj, inputArgs) => {
const nodeConnection = new ConnectionManager<INode>(inputArgs, attributeMap);
const appliedQuery = nodeConnection.createQuery(queryBuilder.clone());
const result = await appliedQuery.select();
nodeConnection.addResult(result);
return {
pageInfo: nodeConnection.pageInfo,
edges: nodeConnection.edges
};
};
types:
interface INode {
[nodeField: string]: any
}
interface IInputArgs {
before?: string;
after?: string;
first?: number;
last?: number;
orderBy?: string;
orderDir?: keyof typeof ORDER_DIRECTION;
filter?: IInputFilter;
}
interface IInAttributeMap {
[nodeField: string]: string;
}
interface INodeConnection {
createQuery: (KnexQueryBuilder) => KnexQueryBuilder
addResult: (KnexQueryResult) => void
pageInfo?: IPageInfo
edges?: IEdge[]
interface IPageInfo: {
hasNextPage: string
hasPreviousPage: string
startCursor: string
endCursor: string
}
interface IEdge {
cursor: string;
node: INode
}
All types can be found in src/types.ts
Detailed Tutorial
A nodeConnection is used to handle connections.
To use a nodeConnection you will have to:
- initialize the nodeConnection
- build the connection query
- build the connection from the executed query
1. Initialize the nodeConnection
To correctly initialize, you will need to supply a Node type, the inputArgs args, and an attributeMap map:
A. set the Node type
The nodes that are part of a connection need a type. The returned edges will contain nodes of this type.
For example, in this case we create an IUserNode
interface IUserNode extends INode {
id: number;
createdAt: string;
}
B. add inputArgs
InputArgs supports before, after, first, last, orderBy, orderDir, and filter:
interface IInputArgs {
before?: string;
after?: string;
first?: number;
last?: number;
orderBy?: string;
orderDir: 'asc' | 'desc';
filter?: IOperationFilter;
}
interface IFilter {
value: string;
operator: string;
field: string;
}
interface IOperationFilter {
and?: Array<IOperationFilter & IFilter>;
or?: Array<IOperationFilter & IFilter>;
not?: Array<IOperationFilter & IFilter>;
}
Note: The default filter operators are the normal SQL comparison operators: >, <, =, >=, <=, and <>
An example query with a filter could look like:
query {
users(
filter: {
or: [
{field: "age", operator: "=", value: "40"}
{field: "age", operator: "<", value: "30"}
{
and: [
{field: "haircolor", operator: "=", value: "blue"}
{field: "age", operator: "=", value: "70"}
{
or: [
{field: "username", operator: "=", value: "Ellie86"}
{field: "username", operator: "=", value: "Euna_Oberbrunner"}
]
}
]
}
]
}
) {
pageInfo {
hasNextPage
hasPreviousPage
}
edges {
cursor
node {
id
age
haircolor
lastname
username
}
}
}
}
This would yield a sql query equivalent to:
SELECT *
FROM `mock`
WHERE `age` = '40' OR `age` < '30' OR (`haircolor` = 'blue' AND `age` = '70' AND (`username` = 'Ellie86' OR `username` = 'Euna_Oberbrunner'))
ORDER BY `id`
ASC
LIMIT 1001
C. specify an attributeMap
attributeMap is a map of GraphQL field names to SQL column names
Only fields defined in the attribute map can be orderBy or filtered on. An error will be thrown if you try to filter on fields that don't exist in the map.
ex:
const attributeMap = {
id: 'id',
createdAt: 'created_at'
};
2. build the query
import {ConnectionManager, INode} from 'graphql-connections';
const resolver = async (obj, inputArgs) => {
const nodeConnection = new ConnectionManager<
IUserNode,
>(inputArgs, attributeMap);
const appliedQuery = nodeConnection.createQuery(queryBuilder.clone());
....
}
3. execute the query and build the connection
A connection type has the signature:
type Connection {
pageInfo: {
hasNextPage: string
hasPreviousPage: string
startCursor: string
endCursor: string
},
edges: Array<{cursor: string; node: Node}>
}
This type is constructed by taking the result of executing the query and adding it to the connectionManager instance via the addResult method.
import {ConnectionManager, INode} from 'graphql-connections';
const resolver = async (obj, inputArgs) => {
...
const result = await appliedQuery
nodeConnection.addResult(result);
return {
pageInfo: nodeConnection.pageInfo,
edges: nodeConnection.edges
};
Options
You can supply options to the ConnectionManager via the third parameter. Options are used to customize the QueryContext, the QueryBuilder, and the QueryResult classes.
const options = {
contextOptions: { ... }
resultOptions: { ... }
builderOptions: { ... }
}
const nodeConnection = new ConnectionManager(inputArgs, attributeMap, options);
Currently, the options are:
contextOptions
defaultLimit
number;
The default limit (page size) if none is specified in the page input params
cursorEncoder
interface ICursorEncoder<CursorObj> {
encodeToCursor: (cursorObj: CursorObj) => string;
decodeFromCursor: (cursor: string) => CursorObj;
}
builderOptions - common
filterTransformer
type filterTransformer = (filter: IFilter) => IFilter;
The filter transformer will will be called on every filter { field: string, operator: string, value: string}
It can be used to transform a filter before being applied to the query. This is useful if you want to transform say UnixTimestamps to DateTime format, etc...
See the filter transformation section for more details.
filterMap
interface IFilterMap {
[operator: string]: string;
}
The filter operators that can be specified in the filter input params.
If no map is specified, the default one is used:
const defaultFilterMap = {
'>': '>',
'>=': '>=',
'=': '=',
'<': '<',
'<=': '<=',
'<>': '<>'
};
builderOptions - MySQL specific
searchColumns
Used with full text Search input. It is an array of column names that will be used in the full text search sql expression MATCH (col1,col2,...) AGAINST (expr [search_modifier])
searchColumns: string[]
searchModifier
Used with full text Search input. It is an array of column names that will be used in the full text search sql expression MATCH (col1,col2,...) AGAINST (expr [search_modifier])
searchColumns: string;
The values will likely be one of:
'IN NATURAL LANGUAGE MODE',
| 'IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION',
| 'IN BOOLEAN MODE',
| 'WITH QUERY EXPANSION'
resultOptions
nodeTransformer
type NodeTransformer<Node> = (node: any) => Node;
A function that is will be called during the creation of each node. This can be used to map the query result to a Node type that matches the graphql Node for the resolver.
cursorEncoder
interface ICursorEncoder<CursorObj> {
encodeToCursor: (cursorObj: CursorObj) => string;
decodeFromCursor: (cursor: string) => CursorObj;
}
Extensions
To extend the connection to a new datastore or to use an adapter besides Knex, you will need to create a new QueryBuilder. See src/KnexQueryBuilder for an example of what a query builder looks like. It should have the type signature:
interface IQueryBuilder<Builder> {
createQuery: (queryBuilder: Builder) => Builder;
}
Architecture
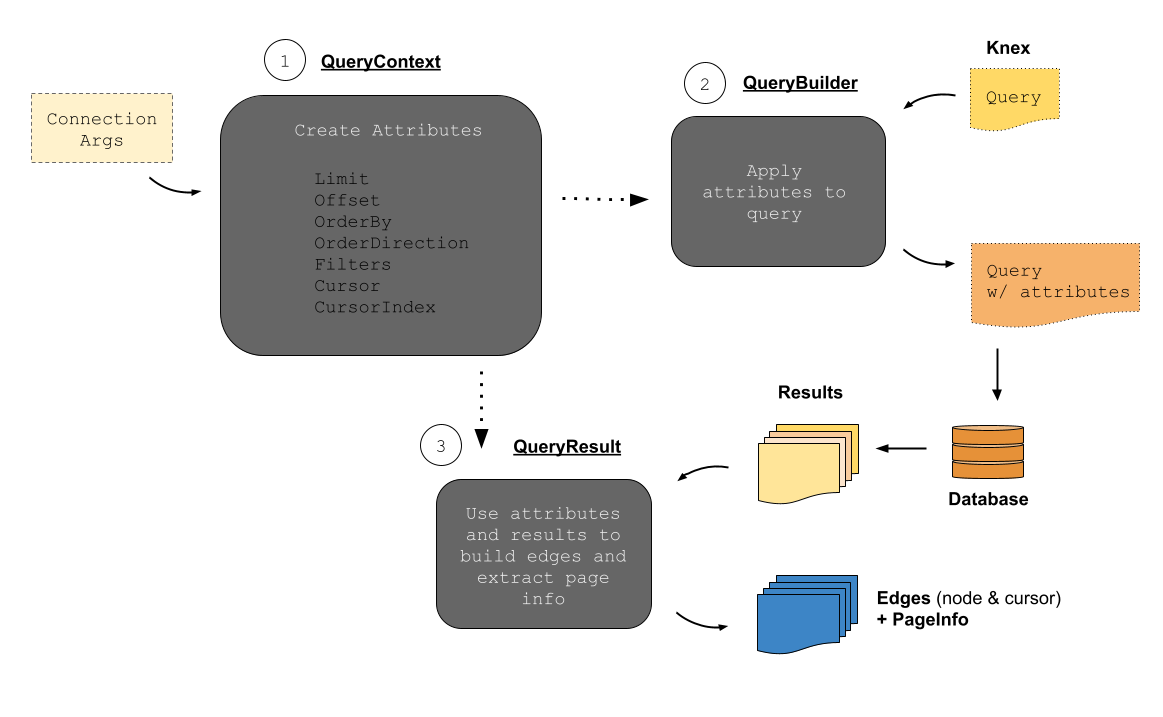
Internally, the ConnectionManager manages the orchestration of the QueryContext, QueryBuilder, and QueryResult.
The orchestration follows the steps:
- The
QueryContext extracts the connection attributes from the input connection arguments. - The
QueryBuilder (or KnexQueryBuilder in the default case) consumes the connection attributes and builds a query. The query is submitted to the database by the user and the result is sent to the QueryResult. - The
QueryResult uses the result to build the edges (which contain a cursor and node) and extract the page info.
This can be visualized as such:
Search
Search inputs are provided for executing full text search query strings against a datastore. At the moment only MySQL support exists.
Using filters may slow down the query.
An example resolver might look like:
const attributeMap = {
id: 'id',
username: 'username',
firstname: 'firstname',
age: 'age',
haircolor: 'haircolor',
lastname: 'lastname',
bio: 'bio'
};
const builderOptions = {
searchColumns: ['username', 'firstname', 'lastname', 'bio', 'haircolor'],
searchModifier: 'IN NATURAL LANGUAGE MODE'
};
const nodeConnection = new ConnectionManager<IUserNode>(inputArgs, attributeMap, {
builderOptions
});
const query = nodeConnection.createQuery(queryBuilder.clone()).select();
const result = (await query) as KnexQueryResult;
nodeConnection.addResult(result);
return {
pageInfo: nodeConnection.pageInfo,
edges: nodeConnection.edges
};
Filtering on computed columns
Sometimes you may compute a field that depends on some other table than the one being paged over. In this case, you can use a derived table as your from and alias it to the primary table. In the following example we create a derived alias of "segment", the table we are paging over, to allow filtering and sorting on "popularity", a field computed on the aggregation of values from another table.
import {Resolver} from 'types/resolver';
import {ISegmentNode} from 'types/graphql';
import {segment as segmentTransformer} from 'transformers/sql_to_graphql';
import {IQueryResult, IInputArgs, ConnectionManager} from 'graphql-connections';
const attributeMap = {
createdAt: 'created_at',
updatedAt: 'updated_at',
name: 'name',
explorer: 'explorer_id',
popularity: 'popularity'
};
const segments: Resolver<Promise<IQueryResult<ISegmentNode>>, undefined, IInputArgs> = async (
_,
input: IInputArgs,
ctx
) => {
const {connection} = ctx.clients.sqlClient;
const queryBuilder = connection.queryBuilder().from(
connection.raw(
`(
select
segment.*,
coalesce(sum(user_segment.usage_count), 0) as popularity
from segment
left join user_segment on user_segment.segment_id = segment.id
group by
segment.id
) as segment`
)
);
const nodeConnection = new ConnectionManager<ISegmentNode>(input, attributeMap, {
builderOptions: {
filterTransformer(filter) {
if (filter.field === 'popularity') {
return {
field: 'popularity',
operator: filter.operator,
value: Number(filter.value) as any
};
}
return filter;
}
},
resultOptions: {
nodeTransformer: segmentTransformer
}
});
const query = nodeConnection.createQuery(queryBuilder).select('*');
nodeConnection.addResult(await query);
return {
pageInfo: nodeConnection.pageInfo,
edges: nodeConnection.edges
};
};
export default segments;
Filter Transformation
Sometimes you may have a completely different data type in a filter from what is actually in your database. At Social Native, for example, our graph exposes all timestamps as Unix Seconds, but in our databases, the timestamp type is used. In order to easily manage filter value transformation from seconds to sql timestamps, we use the filterTransformer option. In the following example, we use the library-provided FilterTransformers.castUnixSecondsFiltersToMysqlTimestamps which takes a list of field names that should be transformed from unix seconds to mysql timestamps, if they are present and not falsy.
import {FilterTransformers} from 'graphql-connections';
type SomeGraphQLNode = {
createdAt: string | number;
updatedAt: string | number;
};
const timestampFilterTransformer = FilterTransformers.castUnixSecondsFiltersToMysqlTimestamps<
SomeGraphQLNode
>(['createdAt', 'updatedAt']);
const nodeConnection = new ConnectionManager<GqlActualDistribution | null>(input, inAttributeMap, {
builderOptions: {
filterTransformer: timestampFilterTransformer
},
resultOptions: {nodeTransformer: sqlToGraphql.actualDistribution}
});
A compose function is also exposed to combine multiple transformers together. The following example composes a transformer on 'createdAt', 'updatedAt' with one on 'startedAt', 'completedAt', creating one that will cast if any of the four were given.
import {FilterTransformers} from 'graphql-connections';
const timestampFilterTransformer = FilterTransformers.castUnixSecondsFiltersToMysqlTimestamps([
'createdAt',
'updatedAt'
]);
const nodeConnection = new ConnectionManager<GqlActualDistribution | null>(input, inAttributeMap, {
builderOptions: {
filterTransformer: FilterTransformers.compose(
timestampFilterTransformer,
FilterTransformers.castUnixSecondsFiltersToMysqlTimestamps(['startedAt', 'completedAt'])
)
},
resultOptions: {nodeTransformer: sqlToGraphql.actualDistribution}
});
Filter Transformers provided by this library
FilterTransformers.castUnixSecondsFiltersToMysqlTimestamps
castUnixSecondsFiltersToMysqlTimestamps takes four arguments
function castUnixSecondsFiltersToMysqlTimestamps<T extends Record<string, unknown>>(
filterFieldsToCast: Array<keyof T>,
timezone: DateTimeOptions['zone'] = 'UTC',
includeOffset = false,
includeZone = false
): FilterTransformer;
filterFieldsToCast refers to the keys in a graphql node being filtered upon that will be transformed from unix seconds to MySQL timestamps.
timezone is the expected timezone of the input seconds. Default: UTC
includeOffset dictates whether the timestamp offset will be included in the generated timestamp Default: false
includeZone dictates whether the timestamp's timezone will be included in the generated timestamp Default: false



