Security News
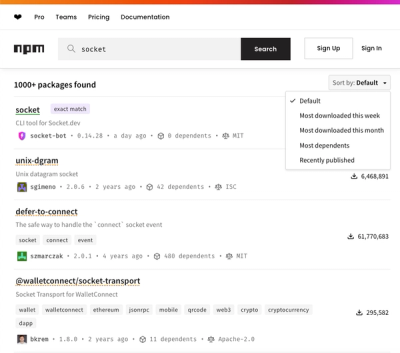
npm Updates Search Experience with New Objective Sorting Options
npm has a revamped search experience with new, more transparent sorting options—Relevance, Downloads, Dependents, and Publish Date.
By Sarah Gooding - Dec 05, 2024
koa-neo4j
Advanced tools
Rapidly create REST APIs, powered by Koa and Neo4j -- batteries included with built-in role based authentication via JWT and reusable backend components
![]()

![]()
koa-neo4j is a framework for creating RESTful web servers. It's been built on top of the widely adapted
Koa library and the NoSQL graph database technology of Neo4j. koa-neo4j
enables one to create web servers scalable both in terms of code complexity and horizontal growth in deployment.
![]()
Choosing a NoSQL graph database for persistence is wise for a number of reasons. While Neo4j provides the DB infrastructure for such choice, applications using Neo4j normally conduct queries directly from the client side, which might not be the best option:
View page sourcestrings, scattered around different
clients (web, mobile, etc.)koa-neo4j addresses all of the above issues:
In addition, it comes with goodies:
nodejs and javascript ecosystem in the processnpm install koa-neo4j --save
To get started quickly you can clone koa-neo4j-starter-kit
var KoaNeo4jApp = require('koa-neo4j');
var app = new KoaNeo4jApp({
// Neo4j config objects, mandatory
neo4j: {
boltUrl: 'bolt://localhost',
user: 'neo4j',
password: '<YOUR_NEO4J_PASSWORD>'
},
// Authentication config object, optional
// authentication: {...} // explained below
// APIs config object, optional (same effect could be achieved later by app.defineAPI)
apis: [
{
method: 'GET',
route: '/authors',
cypherQueryFile: './cypher/authors.cyp'
},
{
method: 'GET',
route: '/articles/:skip/:limit',
cypherQueryFile: './cypher/articles.cyp'
}
],
// Koa middlewares could be injected and will be loaded before api invoked,e.g:a koa static file serving middleware as following
middleware:[convert(staticFile('./public'))]
});
app.listen(3000, function() {
console.log('App listening on port 3000.');
});
An API is defined by at least three keys:
method, specifies the request type (GET|POST|PUT|DEL)
route, the path to this API (e.g. the first API defined in apis above becomes http://localhost:3000/authors)
cypherQueryFile, path to the corresponding .cyp file
Optionally you can specify roles whom can access this route with allowedRoles and
also lifecycle hooks.
As an example:
app.defineAPI({
// allowedRoles: ['admin', 'author'] // roles are case insensitive
method: 'POST',
route: '/create-article',
cypherQueryFile: './cypher/create_article.cyp'
});
And then in ./cypher/create_article.cyp:
CREATE (a:Article {
title: $title,
author: $author,
created_at: timestapm()
})
RETURN a
Cypher queries accept parameters via the $ syntax.
These parameters are matched by query parameters /articles?title=Hello&author=World or route parameters
(e.g. if route was defined as /create-article/:author/:title then /create-article/World/Hello)
In addition, any data accompanied by the request will also be passed to the Cypher query, retaining the variable names, so for example:
curl --data "title=The%20Capital%20T%20Truth&author=David%20Foster%20Wallace" localhost:3000/create-article
becomes a POST request, {"title": "The Capital T Truth", "author": "David Foster Wallace"} will be
passed to ./cypher/create_article.cyp which refers to these parameters as $title and $author
In case of encountering same variable names, priority is applied: request data > route params > query params
Authentication is facilitated through JSON web token, all it takes to
have authentication in your app is to supplement Authentication config object either with authentication key
when initiating the app instance or in configureAuthentication method:
app.configureAuthentication({
// route, mandatory.
route: '/auth',
// secret, mandatory. This is the key that JWT uses to encode objects, best practice is to use a
// long and random password-like string
secret: 'secret',
// userCypherQueryFile, mandatory. This cypher query is invoked with `$username` and is expected to return
// a single object at least containing two keys: `{id: <user_id>, password: <user_password_or_hash>}`
// the returned `id` would later be passed to get roles of this user
userCypherQueryFile: './cypher/user.cyp',
// rolesCypherQueryFile, optional. Invoked with `$id` returned from userCypherQueryFile, this query is
// expected to return a list of strings describing roles of this user, you can do all sorts of traversals
// that cypher allows to generate this list. Defaults to labels of the node matching the id:
// `MATCH (user) WHERE id(user) = $id RETURN {roles: labels(user)}`
// rolesCypherQueryFile: './cypher/roles.cyp'
});
And your desired $username to user mapping in userCypherQueryFile:
// Takes $username and returns a user object with at least 'id' and 'password'
MATCH (author:Author)-[:HAS]->(account:UserAccount)
WHERE account.user_name = $username
RETURN {id: id(author), password: account.password_hash}
When authentication is configured, you can access it by sending a POST request to the route you specified. Pass a
JSON object to e.g. /auth in the following form:
{
"username": "<user_name>",
"password": "<user_password_or_hash>",
"remember": true
}

Note that if you don't set "remember": true, the generated token expires in an hour.
Returned object contains a token which should be supplemented as Authorization header
in subsequent calls to routes that have allowedRoles protection.
In addition, a user object is returned that matches the object returned by userCypherQueryFile except
for the password key, which is deleted (so that security won't be compromised should
clients decide to save this object) and roles key, which is the object returned by rolesCypherQueryFile.
When a request to a route guarded by allowedRoles is received, the request either does not have an Authorization
header set, in which case the server responds with a 401: Unauthorized error, or the Authorization header is present.
In case of a valid header (not expired or manipulated), the request goes through and the user object would be attached
to the Koa context and made available to
lifecycle hooks as ctx.user.
A lifecycle hook is a single function or a group of functions invoked at a certain phase in request-to-response cycle. It helps with shaping the data according to one's needs. Further, the framework comes with a number of built-in hook functions, ready to be dropped in their corresponding lifecycle.
A hook function takes the form of a normal JavaScript function, with arguments consistent with the lifecycle in which it'd be deployed. If an array of functions is submitted for a lifecycle, each function in the array is executed, sequentially, and the returned object from the function would be passed as the first argument of the next function.
app.defineAPI({
// ...
preProcess: [
function(params, ctx) {
// do something with params and/or ctx
return {modified: 'params'};
}, // ‾‾‾‾‾‾‾‾‾‾|‾‾‾‾‾‾‾‾‾
// |
// ↓‾‾‾‾‾‾‾‾‾‾
function(params, ctx) {
params.again = 'modified';
// params now is: {modified: 'params', again: 'modified'}
return params;
}, // ‾‾|‾‾‾
// |
// ↓
function(params, ctx) {
params.and = 'again';
// params now is: {modified: 'params', again: 'modified', and: 'again'}
return params;
},
// ... this can continue ...
],
// ...
});
ProTip: if returned value in a hook function is a Promise or an array containing any Promises, first argument of
the next function would be the resolved value or an array with all it's elements resolved, respectively.
Hook function signature: (params[, ctx]) -> :boolean
This lifecycle is the first one that a request goes through. It is useful for scenarios where you want to check
the parameters or the user before commencing. A false return value produces an error in check lifecycle error.
// Example:
app.defineAPI({
// ...
check: function(params, ctx) {
// check user has enough money
return params.amount < getBalance(ctx.user.id);
},
// ...
});
// Default:
check: function (params) {
// Always passes
return true;
}
check built-in hook functions: import/require from
koa-neo4j/check
(DOCS)
Hook function signature: (params[, ctx]) -> params
Using this lifecycle, one can adjust parameters before sending them to Cypher. Parsing strings is a usual suspect, the framework comes with many built-in parse functions for this lifecycle.
// Example:
var parseFloats = require('koa-neo4j/preprocess').parseFloats;
app.defineAPI({
// ...
preProcess: [
// parse params.amount as float
parseFloats('amount'),
function(params) {
// give 10% discount
params.amount = params.amount * 0.9;
return params;
},
// ...
],
// ...
});
// Default:
preProcess: function (params) {
// Returns `params` unchanged
return params;
}
preProcess built-in hook functions: import/require from
koa-neo4j/preprocess
(DOCS)
Execution happens between preProcess and postProcess, takes params as input and generates result. Currently
there are 4 types of execution, if all were present in an API or Procedure definition,
priority is applied:
params.result > params.cypher > cypherQueryFileProTip: key would be consumed as a result of any params.<key> execution, meaning that the key reference in
params would be deleted in subsequent references to params.
Happens if a cypherQueryFile is supplied. Executes the Cypher query contained in the file, passing params along which
Cypher can access with the $ syntax.
If you need string manipulation to create your Cypher query, you can do so in
preProcess lifecycle by assigning params.cypher to your query. After all preProcess hook
functions are executed, framework will see whether params.cypher is defined, and executes it if present. Except for
primitive string, params.cypher may also be string array type which contains multiple cypher queries to execute.
params.result could be set to a value, a Promise or an array containing Promises. result would then be the
value, the resolved value of the Promise or an array with all it's elements resolved, respectively. This is useful
when one wants the result to come from procedures, since calling a procedure returns a promise:
// Example:
var someProcedure = app.createProcedure({
// ...
});
app.defineAPI({
// ...
preProcess: [
// ...
function(params) {
params.result = [];
for (var i = 0; i < params.someArray.length; i++)
params.result.push(someProcedure({someParameter: params.someArray[i]}));
return params;
}
],
postProcess: [
function(result) {
// `result` is now an array containing resolved values of calls to someProcedure
return result;
}
]
});
Hook function signature: (result[, params, ctx]) -> result
This lifecycle takes the result from execution lifecycle and amends further changes to the result before sending it to
the client. If params.cypher is array type assigned in execution lifecycle, result will also be an array contains execution
results for each cypher query.
// Example:
var fetchOne = require('koa-neo4j/postprocess').fetchOne;
app.defineAPI({
// ...
postProcess: [
fetchOne,
function(result, params, ctx) {
return {
user: ctx.user,
balance_after: params.balance - result
};
},
// ...
],
// ...
});
// Default:
postProcess: function (result) {
// serves result of execution lifecycle, unchanged
return result;
}
postProcess built-in hook functions: import/require from
koa-neo4j/postprocess
(DOCS)
Hook function signature: (result[, params, ctx]) -> result
Semantics of postServe is identical to postProcess, except that postServe is invoked after the response of the
request is sent (served). This lifecycle suits time consuming tasks that are internal to logic and can be carried out
after the request is served.
// Default:
postServe: function (result) {
// Doesn't do anything
return result;
}
When globalTransaction flag is set, neo4j cypher will be committed after finish postProcessing and rollback if exception thrown
app.defineAPI({
preProcess:func1,
postProcess:func2,
globalTransaction:true
});
Procedures share semantics with APIs, they are defined in the same way that an API is defined, except they don't accept
method, route and allowedRoles. You can create idiomatic and reusable blocks of backend code using procedures and
built-in lifecycle hook functions:
var parseIds = require('koa-neo4j/preprocess').parseIds;
var parseDates = require('koa-neo4j/preprocess').parseDates;
var logValues = require('koa-neo4j/debug').logValues;
var errorOnEmptyResult = require('koa-neo4j/postprocess').errorOnEmptyResult;
var fetchOne = require('koa-neo4j/postprocess').fetchOne;
var convertToPreProcess = require('koa-neo4j/postprocess').convertToPreProcess;
var articlesAfterDate = app.createProcedure({
// Providing a name facilitates debugging
name: 'articlesAfterDate',
preProcess: [
parseIds('author_id'),
parseDates({'timestamp': 'date'}),
logValues
],
cypherQueryFile: './cypher/articles_after_date.cyp',
postProcess: [
logValues,
errorOnEmptyResult('author not found'), // returns this message with a 404 http code
fetchOne,
convertToPreProcess('articles') // assigns params.articles to result of procedure
]
});
var blogsAfterDate = app.createProcedure({
// ...
});
app.defineAPI({
allowedRoles: ['admin'],
route: '/author-activity/:author_id/:timestamp',
preProcess: [
articlesAfterDate,
blogsAfterDate,
function(params) {
params.result = {
// params.date is created by parseDates hook function in articlesAfterDate
interval: `past ${new Date().getDate() - params.date.getDate()} days`,
articles: params.articles,
blogs: params.blogs
};
return params;
}
]
})
ProTip: procedures created by app.createProcedure are callable and return a promise that resolves to result:
var someProcedure = app.createProcedure({
// ...
});
someProcedure(params, ctx).then(function(result) {
console.log(result);
});
Or if you can use async/await:
app.defineAPI({
preProcess: [
async params => {
// ...
params.someValue = await someProcedure({some: 'parameter'});
return params;
},
// ...
],
// ...
})
ProTip: a defineAPI block can reuse a procedure's body via the procedure key:
app.defineAPI({
method: 'POST',
route: '/some-api',
procedure: someProcedure
});
FAQs
Rapidly create REST APIs, powered by Koa and Neo4j -- batteries included with built-in role based authentication via JWT and reusable backend components
We found that koa-neo4j demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 3 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
npm has a revamped search experience with new, more transparent sorting options—Relevance, Downloads, Dependents, and Publish Date.

Security News
A supply chain attack has been detected in versions 1.95.6 and 1.95.7 of the popular @solana/web3.js library.

Research
Security News
A malicious npm package targets Solana developers, rerouting funds in 2% of transactions to a hardcoded address.