node-resque
Delayed Tasks in nodejs. A very opinionated but compatible API with resque and resque scheduler. Resque is a background job system based on redis. It includes priority queus, plugins, locking, delayed jobs, and more!



Usage
I learn best by examples:
var NR = require("node-resque");
var connectionDetails = {
package: 'ioredis',
host: '127.0.0.1',
password: null,
port: 6379,
database: 0,
};
var jobs = {
"add": {
plugins: [ 'jobLock' ],
pluginOptions: {
jobLock: {},
},
perform: function(a,b,callback){
var answer = a + b;
callback(null, answer);
},
},
"subtract": {
perform: function(a,b,callback){
var answer = a - b;
callback(null, answer);
},
},
};
var worker = new NR.worker({connection: connectionDetails, queues: ['math', 'otherQueue']}, jobs);
worker.connect(function(){
worker.workerCleanup();
worker.start();
});
var scheduler = new NR.scheduler({connection: connectionDetails});
scheduler.connect(function(){
scheduler.start();
});
worker.on('start', function(){ console.log("worker started"); });
worker.on('end', function(){ console.log("worker ended"); });
worker.on('cleaning_worker', function(worker, pid){ console.log("cleaning old worker " + worker); });
worker.on('poll', function(queue){ console.log("worker polling " + queue); });
worker.on('job', function(queue, job){ console.log("working job " + queue + " " + JSON.stringify(job)); });
worker.on('reEnqueue', function(queue, job, plugin){ console.log("reEnqueue job (" + plugin + ") " + queue + " " + JSON.stringify(job)); });
worker.on('success', function(queue, job, result){ console.log("job success " + queue + " " + JSON.stringify(job) + " >> " + result); });
worker.on('failure', function(queue, job, failure){ console.log("job failure " + queue + " " + JSON.stringify(job) + " >> " + failure); });
worker.on('error', function(queue, job, error){ console.log("error " + queue + " " + JSON.stringify(job) + " >> " + error); });
worker.on('pause', function(){ console.log("worker paused"); });
scheduler.on('start', function(){ console.log("scheduler started"); });
scheduler.on('end', function(){ console.log("scheduler ended"); });
scheduler.on('poll', function(){ console.log("scheduler polling"); });
scheduler.on('master', function(state){ console.log("scheduler became master"); });
scheduler.on('error', function(error){ console.log("scheduler error >> " + error); });
scheduler.on('working_timestamp', function(timestamp){ console.log("scheduler working timestamp " + timestamp); });
scheduler.on('transferred_job', function(timestamp, job){ console.log("scheduler enquing job " + timestamp + " >> " + JSON.stringify(job)); });
var queue = new NR.queue({connection: connectionDetails}, jobs);
queue.on('error', function(error){ console.log(error); });
queue.connect(function(){
queue.enqueue('math', "add", [1,2]);
queue.enqueue('math', "add", [1,2]);
queue.enqueue('math', "add", [2,3]);
queue.enqueueIn(3000, 'math', "subtract", [2,1]);
});
Configuration Options:
new queue requires only the "queue" variable to be set. You can also pass the jobs hash to it.
new worker has some additonal options:
options = {
looping: true,
timeout: 5000,
queues: "*",
name: os.hostname() + ":" + process.pid
}
The configuration hash passed to new worker, new scheduler or new queue can also take a connection option.
var connectionDetails = {
package: "ioredis",
host: "127.0.0.1",
password: "",
port: 6379,
database: 0,
namespace: "resque",
}
var worker = new NR.worker({connection: connectionDetails, queues: 'math'}, jobs);
worker.on('error', function(){
});
worker.connect(function(){
worker.start();
});
You can also pass redis client directly.
var redisClient = new Redis();
var connectionDetails = { redis: redisClient }
var worker = new NR.worker({connection: connectionDetails, queues: 'math'}, jobs,
worker.on('error', function(){
});
worker.connect(function(){
worker.start();
});
Notes
- Be sure to call
worker.end(), queue.end() and scheduler.end() before shutting down your application if you want to properly clear your worker status from resque - When ending your application, be sure to allow your workers time to finish what they are working on
- This project implements the "scheduler" part of rescue-scheduler (the daemon which can promote enqueued delayed jobs into the work queues when it is time), but not the CRON scheduler proxy. To learn more about how to use a CRON-like scheduler, read the Job Schedules section of this document.
- If you are using any plugins which effect
beforeEnqueue or afterEnqueue, be sure to pass the jobs argument to the new Queue constructor - If a job fails, it will be added to a special
failed queue. You can then inspect these jobs, write a plugin to manage them, move them back to the normal queues, etc. Failure behavior by default is just to enter the failed queue, but there are many options. Check out these examples from the ruby ecosystem for inspiration:
- If you plan to run more than one worker per nodejs process, be sure to name them something distinct. Names must follow the pattern
hostname:pid+unique_id. For example:
var name = os.hostname() + ":" + process.pid + "+" + counter;
var worker = new NR.worker({connection: connectionDetails, queues: 'math', 'name' : name}, jobs);
Queue Management
Additional methods provided on the queue object:
- queue.prototype.queues = function(callback)
- callback(error, array_of_queues)
- queue.prototype.delQueue = function(q, callback)
- queue.prototype.queued = function(q, start, stop, callback)
- callback(error, jobs_in_queue)
- queue.prototype.length = function(q, callback)
- callback(error, number_of_elements_in_queue)
- queue.prototype.del = function(q, func, args, count, callback)
- callback(error, number_of_items_deleted)
- queue.prototype.delDelayed = function(q, func, args, callback)
- callback(error, timestamps_the_job_was_removed_from)
- queue.prototype.scheduledAt = function(q, func, args, callback)
- callback(error, timestamps_the_job_is_scheduled_for)
Delayed Status
- queue.timestamps = function(callback)
- callback(error, timestamps)
- queue.delayedAt = function(timestamp, callback)
- callback(error, jobs_enqueued_at_this_timestamp)
- queue.allDelayed = function(timestamp)
- callback(error, jobsHash)
- jobsHash is an object with its keys being timestamps, and the vales are arrays of jobs at each time.
- note that this operation can be very slow and very ram-heavy
Worker Status
You can use the queue object to check on your workers:
- queue.workers = function(callback)`
- returns:
{ 'host:pid': 'queue1, queue2', 'host:pid': 'queue1, queue2' }
- queue.workingOn = function(workerName, queues, callback)`
- returns:
{"run_at":"Fri Dec 12 2014 14:01:16 GMT-0800 (PST)","queue":"test_queue","payload":{"class":"slowJob","queue":"test_queue","args":[null]},"worker":"workerA"}
- queue.allWorkingOn = function(callback)`
- returns a hash of the results of
queue.workingOn with the worker names as keys.
Failed Job Management
From time to time, your jobs/workers may fail. Resque workers will move failed jobs to a special failed queue which will store the original arguments of your job, the failing stack trace, and additional metadata.
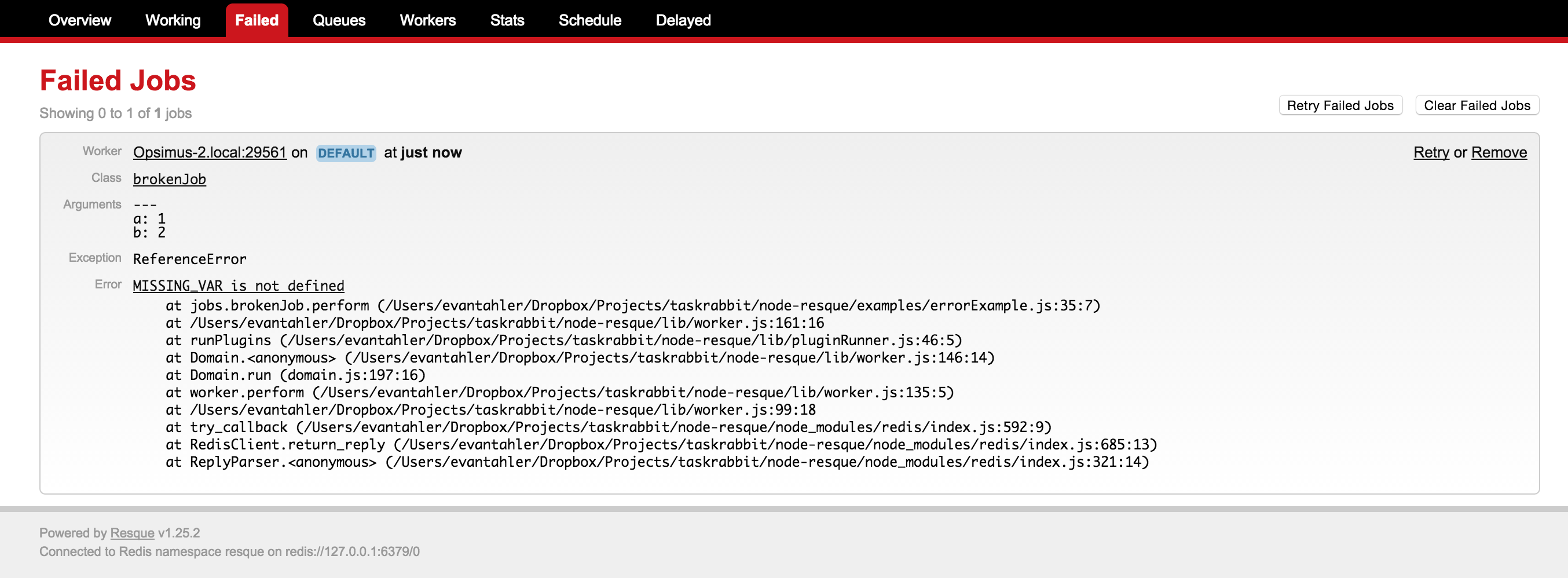
You can work with these failed jobs with the following methods:
-
queue.failedCount = function(callback)
- callback(error, failedCount)
failedCount is the number of jobs in the failed queue
-
queue.failed = function(start, stop, callback)
- callback(error, failedJobs)
failedJobs is an array listing the data of the failed jobs. Each element looks like:
{ worker: 'busted-worker-3',
queue: 'busted-queue',
payload: { class: 'busted_job', queue: 'busted-queue', args: [ 1, 2, 3 ] },
exception: 'ERROR_NAME',
error: 'I broke',
failed_at: 'Sun Apr 26 2015 14:00:44 GMT+0100 (BST)' }
-
queue.removeFailed = function(failedJob, callback)
- callback(error)
- the input
failedJob is an expanded node object representing the failed job, retrieved via queue.failed
-
queue.retryAndRemoveFailed = function(failedJob, callback)
- callback(error)
- the input
failedJob is an expanded node object representing the failed job, retrieved via queue.failed - this method will instantly re-enqueue a failed job back to its original queue, and delete the failed entry for that job
Failed Worker Management
Sometimes a worker crashes is a severe way, and it doesn't get the time/chance to notify redis that it is leaving the pool (this happens all the time on PAAS providers like Heroku). When this happens, you will not only need to extract the job from the now-zombie worker's "working on" status, but also remove the stuck worker. To aid you in these edge cases, ``queue.cleanOldWorkers(age, callback)` is available.
Because there are no 'heartbeats' in resque, it is imposable for the application to know if a worker has been working on a long job or it is dead. You are required to provide an "age" for how long a worker has been "working", and all those older than that age will be removed, and the job they are working on moved to the error queue (where you can then use queue.retryAndRemoveFailed) to re-enqueue the job.
If you know the name of a worker that should be removed, you can also call queue.forceCleanWorker(workerName, callback) directly, and that will also remove the worker and move any job it was working on into the error queue.
Job Schedules
You may want to use node-resque to schedule jobs every minute/hour/day, like a distributed CRON system. There are a number of excellent node packages to help you with this, like node-schedule and node-cron. Node-resque makes it possible for you to use the package of your choice to schedule jobs with.
Assuming you are running node-resque across multiple machines, you will need to ensure that only one of your processes is actually scheduling the jobs. To help you with this, you can inspect which of the scheduler processes is currently acting as master, and flag only the master scheduler process to run the schedule. A full example can be found at /examples/scheduledJobs.js, but the relevant section is:
var schedule = require('node-schedule');
var scheduler = new NR.scheduler({connection: connectionDetails}, function(){
scheduler.start();
});
var queue = new NR.queue({connection: connectionDetails}, jobs, function(){
schedule.scheduleJob('10,20,30,40,50 * * * * *', function(){
if(scheduler.master){
console.log(">>> enquing a job");
queue.enqueue('time', "ticktock", new Date().toString() );
}
});
});
Plugins
Just like ruby's resque, you can write worker plugins. They look look like this. The 4 hooks you have are before_enqueue, after_enqueue, before_perform, and after_perform
var myPlugin = function(worker, func, queue, job, args, options){
var self = this;
self.name = 'myPlugin';
self.worker = worker;
self.queue = queue;
self.func = func;
self.job = job;
self.args = args;
self.options = options;
if(self.worker.queueObject){
self.queueObject = self.worker.queueObject;
}else{
self.queueObject = self.worker;
}
}
myPlugin.prototype.before_enqueue = function(callback){
callback(null, true);
}
myPlugin.prototype.after_enqueue = function(callback){
callback(null, true);
}
myPlugin.prototype.before_perform = function(callback){
callback(null, true);
}
myPlugin.prototype.after_perform = function(callback){
callback(null, true);
}
And then your plugin can be invoked within a job like this:
var jobs = {
"add": {
plugins: [ 'myPlugin' ],
pluginOptions: {
myPlugin: { thing: 'stuff' },
},
perform: function(a,b,callback){
var answer = a + b;
callback(null, answer);
},
},
}
notes
- All plugins which return
(error, toRun). if toRun = false on beforeEnqueue, the job begin enqueued will be thrown away, and if toRun = false on beforePerfporm, the job will be reEnqued and not run at this time. However, it doesn't really matter what toRun returns on the after hooks. - If you are writing a plugin to deal with errors which may occur during your resque job, you can inspect and modify
worker.error in your plugin. If worker.error is null, no error will be logged in the resque error queue. - There are a few included plugins, all in the lib/plugins/* directory. You can rewrite you own and include it like this:
var jobs = {
"add": {
plugins: [ require('myplugin') ],
pluginOptions: {
myPlugin: { thing: 'stuff' },
},
perform: function(a,b,callback){
var answer = a + b;
callback(null, answer);
},
},
}
Multi Worker
node-resque provides a wrapper around the worker object which will auto-scale the number of resque workers. This will process more than one job at a time as long as there is idle CPU within the event loop. For example, if you have a slow job that sends email via SMTP (with low rendering overhead), we can process many jobs at a time, but if you have a math-heavy operation, we'll stick to 1. The multiWorker handles this by spawning more and more node-resque workers and managing the pool.
var NR = require(__dirname + "/../index.js");
var connectionDetails = {
package: "ioredis",
host: "127.0.0.1",
password: ""
}
var multiWorker = new NR.multiWorker({
connection: connectionDetails,
queues: ['slowQueue'],
minTaskProcessors: 1,
maxTaskProcessors: 100,
checkTimeout: 1000,
maxEventLoopDelay: 10,
toDisconnectProcessors: true,
}, jobs);
multiWorker.on('start', function(workerId){ console.log("worker["+workerId+"] started"); })
multiWorker.on('end', function(workerId){ console.log("worker["+workerId+"] ended"); })
multiWorker.on('cleaning_worker', function(workerId, worker, pid){ console.log("cleaning old worker " + worker); })
multiWorker.on('poll', function(workerId, queue){ console.log("worker["+workerId+"] polling " + queue); })
multiWorker.on('job', function(workerId, queue, job){ console.log("worker["+workerId+"] working job " + queue + " " + JSON.stringify(job)); })
multiWorker.on('reEnqueue', function(workerId, queue, job, plugin){ console.log("worker["+workerId+"] reEnqueue job (" + plugin + ") " + queue + " " + JSON.stringify(job)); })
multiWorker.on('success', function(workerId, queue, job, result){ console.log("worker["+workerId+"] job success " + queue + " " + JSON.stringify(job) + " >> " + result); })
multiWorker.on('failure', function(workerId, queue, job, failure){ console.log("worker["+workerId+"] job failure " + queue + " " + JSON.stringify(job) + " >> " + failure); })
multiWorker.on('error', function(workerId, queue, job, error){ console.log("worker["+workerId+"] error " + queue + " " + JSON.stringify(job) + " >> " + error); })
multiWorker.on('pause', function(workerId){ console.log("worker["+workerId+"] paused"); })
multiWorker.on('internalError', function(error){ console.log(error); })
multiWorker.on('multiWorkerAction', function(verb, delay){ console.log("*** checked for worker status: " + verb + " (event loop delay: " + delay + "ms)"); });
multiWorker.start();
Presentation
This package was featured heavily in this presentation I gave about background jobs + node.js. It contains more examples!
Acknowledgments
Most of this code was inspired by / stolen from coffee-resque and coffee-resque-scheduler. Thanks!



