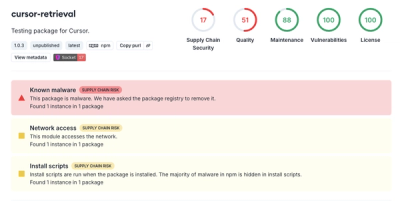
pat-tree
In Information Retrieval, text segmentation on Chinese like
documents has been a difficult task, since Chinese words are
continuous and has no white space between them. But finding basic
elements of a document is critical for all applications in information retrieval.
PAT tree is a Patricia tree, or called trie, that used particularly for
text segmentation and word retrieval. This module can be used for
PAT tree construction for Chinese documents.
Provide functionality to add documents and construct PAT tree in memory,
convert to JSON for storing to database,
extract keywords, and text segmentation.
You can collect a corpus, adding all of them to construct a PAT tree,
then extract significant lexical patterns, and do text segmentation
on other documents.
example of result:
有時 喜歡 有時候 不喜歡
為什麼 會 這樣 … ?
20 點 求 解 哈哈
Installation
npm install pat-tree --save
Usage
Instantiate
var PATtree = require("pat-tree");
var tree = new PATtree();
Add document
tree.addDocument(doc);
doc is the document you want to add to the tree. data type: string
var SLPs = tree.extractSLP(TFThreshold, SEThreshold, verbose);
If the frequency of a pattern exceeds TFThreshold, it would appear in the result array.
The higher the SEThreshold, the stricter to filter out longest substrings of a significant lexical pattern.
verbose: optional, if set to true, then will print out progress on console.
TFTreshold should be integer, SEThreshold should be float between 0 and 1.
Text segmentation
var result = tree.segmentDoc(doc, SLPs);
doc is the document to be segmented, data type: string.
SLPs is array of SLP that extracted by tree.extractSLP(), data type: array of JSON object.
result is the result of document segmentation, data type: string.
Convert to JSON
var json = tree.toJSON();
The result json has following three content:
json.header: JSON object,json.documents: array,json.tree: array
You could store them to database and use tree.reborn() to generate the tree again.
In NoSQL database, you can store the three items to seperate collections,
header collection would contain exactly one document, and documents and tree would contain lots of documents.
For Example, if using MongoDB native driver:
var json = tree.toJSON();
db.collection("header").insert(json.header, function(err, result) {
if(err) throw err;
});
db.collection("documents").insert(json.documents, function(err, result) {
if(err) throw err;
});
db.collection("tree").insert(json.tree, function(err, result) {
if(err) throw err;
});
Reborn
tree.reborn(json);
If you use tree.toJSON() to generate the JSON object and store the three objects to different collections,
you can construct them to the original JSON object and use tree.reborn(json) to reborn the tree.
For example, if using MongoDB native driver:
db.collection("header").find().toArray(function(err, headers) {
db.collection("documents").find().toArray(function(err, documents) {
db.collection("tree").find().toArray(function(err, tree) {
var json = {};
json.header = headers[0];
json.documents = documents;
json.tree = tree;
var patTree = new PATTree();
patTree.reborn(json);
})
})
})
The patTree object would now be the same as the previously stored status,
and you can do all operations like patTree.addDocuments(doc) to it.
CATUION
If you reborn the tree by above method, and do some operations like patTree.addDocument(doc),
and you want to store the tree back to database as illustrated in Convert to JSON,
you MUST drop the collections(header, documents, tree) in the database first,
avoiding any record that is previously stored.
Additional functions
Print tree content
tree.printTreeContent(printExternalNode, printDocuments);
Print the content of the tree on console.
If printExternalNode is set to true, print out one external node for each internal node.
If printDocuments is set to true, print out the whole collection of the tree.
Traversal
tree.traverse(preCallback, inCallback, postCallback);
For convenience, there are functions for each order of traversal
tree.preOrderTraverse(callback);
tree.inOrderTraverse(callback);
tree.postOrderTraverse(callback);
For example
tree.preOrderTraverse(function(node) {
console.log("node id: " + node.id);
})
Data type
Node
Every nodes has some common informaitons, an node has the following structure:
node = {
id: 3,
parent: parentNode,
left: leftChildNode,
right: rightChildNode,
}
Other attributes in nodes are different for internal nodes and external nodes,
Internal nodes has following structure:
Internal nodes
internalNode = {
type: "internal",
position: 13,
prefix: "00101",
externalNodeNum: 87,
totalFrequency: 89,
sistringRepres: node
}
External nodes
External nodes has following structure:
externalNode = {
type: "external",
sistring: "00101100110101",
indexes: ["0.1,3", "1.2.5"]
}
Collection
The whole collection consists of documents, which consists of sentenses, which consists of words.
An example could be this:
[ [ '嗨你好',
'這是測試文件' ],
[ '你好',
'這是另外一個測試文件' ] ]
An index is in following structure:
DocumentPosition.SentensePosition.wordPosition
For example, "0.1.2" is the index of the character "測".
Performance
All operations are fast, but require more memory and disk space to operate successfully.
Running on Macbook Pro Retina, connected to local MongoDB, given 8GB memory size
by specifying V8 option --max_old_space_size=8000, has following performance.
- Add 32,769 Facebook-like posts by
tree.addDocument() takes about 5 minutes. - After above operation, extract SLP by
tree.extractSLP() takes about 5 minutes. - After above operation, converting to JSON by
tree.toJSON() and store three collections to database takes about 1 minutes
and 5 GB disk space, and about 1,000,000 records of tree nodes. - After above operation, find all collections in database and reborn the tree by
tree.reborn() takes about 1 minutes. - After above operation, do text segmentation on 32,769 posts by
tree.segmentDoc(), given SLPs extracted above,
takes about 5 minutes.
Release History
- 1.0.2 Gaurantee SLP sorting order when
segmentDoc() - 1.0.1 Modify README file
- 1.0.0 Stable release
- 0.2.8 Improve algorithm of
segmentDoc() - 0.2.7 Fix bug in
reborn() - 0.2.6 Greatly improve performance of
extractSLP() - 0.2.5 Greatly improve performance of
addDocument() - 0.2.4 Fix bug in
reborn() - 0.2.3 Add functions
toJSON() and reborn() - 0.2.2 Change function name of
splitDoc() to segmentDoc() - 0.2.1 Mofify README file
- 0.2.0 Add text segmentation functionality
- 0.1.8 Alter algorithm, improve simplicity
- 0.1.7 Improve performance
- 0.1.6 Improve performance
- 0.1.5 Add functionality of SLP extraction
- 0.1.4 Add external node number and term frequency to internal nodes
- 0.1.3 Able to restore Chinese characters
- 0.1.2 Construction complete
- 0.1.1 First release