Security News
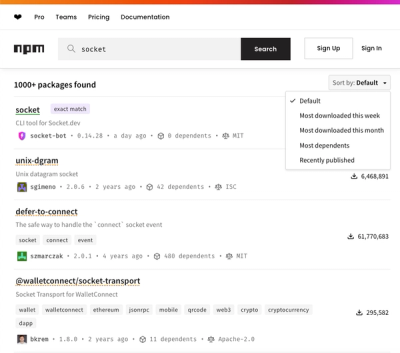
npm Updates Search Experience with New Objective Sorting Options
npm has a revamped search experience with new, more transparent sorting options—Relevance, Downloads, Dependents, and Publish Date.
By Sarah Gooding - Dec 05, 2024
Regex template tag with extended syntax, context-aware interpolation, and always-on best practices
![]()

regex is a template tag that extends JavaScript regular expressions with features from other leading regex libraries that make regexes more powerful and dramatically more readable. It returns native RegExp instances that run with native performance, and can exceed the performance of regex literals you'd write yourself. It's also lightweight, has no dependencies, supports all ES2025 regex features, has built-in TypeScript declarations, and can be used as a Babel plugin to avoid any runtime dependencies or user runtime cost.
Highlights include support for free spacing and comments, atomic groups via (?>…) and possessive quantifiers (e.g. ++) that can help you avoid ReDoS, subroutines via \g<name> and subroutine definition groups via (?(DEFINE)…) that enable powerful subpattern composition, and context-aware interpolation of regexes, escaped strings, and partial patterns.
With the regex library, JavaScript steps up as one of the best regex flavors alongside PCRE and Perl, possibly surpassing C++, Java, .NET, Python, and Ruby.
\\\\ since it's a raw string template tag.import {regex, pattern} from 'regex';
// Subroutines and subroutine definition group
const record = regex`
^ Admitted:\ (?<admitted> \g<date>) \n
Released:\ (?<released> \g<date>) $
(?(DEFINE)
(?<date> \g<year>-\g<month>-\g<day>)
(?<year> \d{4})
(?<month> \d{2})
(?<day> \d{2})
)
`;
// Atomic group: Avoids ReDoS from the nested, overlapping quantifier
const words = regex`^(?>\w+\s?)+$`;
// Context-aware and safe interpolation
const re = regex('m')`
# Only the inner regex is case insensitive (flag i)
# Also, the outer regex's flag m is not applied to it
${/^a.b$/i}
|
# Strings are contextually escaped and repeated as complete units
^ ${'a.b'}+ $
|
# This string is contextually sandboxed but not escaped
${pattern('^ a.b $')}
`;
// Numbered backreferences in interpolated regexes are adjusted
const double = /(.)\1/;
regex`^ (?<first>.) ${double} ${double} $`;
// → /^(?<first>.)(.)\2(.)\3$/v
npm install regex
import {regex, pattern} from 'regex';
In browsers:
<script type="module">
import {regex, pattern} from 'https://cdn.jsdelivr.net/npm/regex@4.1.2/+esm';
// …
</script>
<script src="https://cdn.jsdelivr.net/npm/regex@4.1.2/dist/regex.min.js"></script>
<script>
const {regex, pattern} = Regex;
</script>
Due to years of legacy and backward compatibility, regular expression syntax in JavaScript is a bit of a mess. There are four different sets of incompatible syntax and behavior rules that might apply to your regexes depending on the flags and features you use. The differences are just plain hard to fully grok and can easily create subtle bugs.
\k when a named capture appears anywhere in a regex.\W, character class ranges, and quantifiers), changes flag i to apply Unicode case-folding, and adds support for new syntax.\p and \P within negated [^…], and adds support for new features/syntax.Additionally, JavaScript regex syntax is hard to write and even harder to read and refactor. But it doesn't have to be that way! With a few key features — raw multiline strings, insignificant whitespace, comments, subroutines, subroutine definition groups, interpolation, and named capture only mode — even long and complex regexes can be beautiful, grammatical, and easy to understand.
regex adds all of these features and returns native RegExp instances. It always uses flag v (already a best practice for new regexes) so you never forget to turn it on and don't have to worry about the differences in other parsing modes (in environments without native v, flag u is automatically used instead while applying v's escaping rules so your regexes are forward and backward compatible). It also supports atomic groups and possessive quantifiers to help you avoid catastrophic backtracking. And it gives you best-in-class, context-aware interpolation of RegExp instances, escaped strings, and partial patterns.
Historically, JavaScript regexes were not as powerful or readable as other major regex flavors like Java, .NET, PCRE, Perl, Python, and Ruby. With recent advancements and the regex library, those days are over. Modern JavaScript regexes have significantly improved, adding lookbehind, named capture, Unicode properties, set subtraction and intersection, etc. The regex library, with its extended syntax and implicit flags, adds the key remaining pieces needed to stand alongside or surpass other major flavors.
Atomic groups are noncapturing groups with special behavior, and are written as (?>…). After matching the contents of an atomic group, the regex engine automatically throws away all backtracking positions remembered by any tokens within the group. Atomic groups are most commonly used to improve performance, and are a much needed feature that regex brings to native JavaScript regular expressions.
Example:
regex`^(?>\w+\s?)+$`
This matches strings that contain word characters separated by spaces, with the final space being optional. Thanks to the atomic group, it instantly fails to find a match if given a long list of words that end with something not allowed, like 'A target string that takes a long time or can even hang your browser!'.
Try running this without the atomic group (as /^(?:\w+\s?)+$/) and, due to the exponential backtracking triggered by the many ways to divide the work of the inner and outer + quantifiers, it will either take a very long time, hang your browser/server, or throw an internal error after a delay. This is called catastrophic backtracking or ReDoS, and it has taken down major services like Cloudflare and Stack Overflow. regex and atomic groups to the rescue!
Consider regex`(?>a+)ab` vs regex`(a+)ab`. The former (with an atomic group) doesn't match 'aaaab', but the latter does. The former doesn't match because:
a+ within the atomic group to match all the as in the target string.a outside the group, it fails (the next character in the target string is a b), so the regex engine backtracks.+ give up its last matched a, there are no additional options to try and the overall match attempt fails.For a more useful example, consider how this can affect lazy (non-greedy) quantifiers. Let's say you want to match <b>…</b> tags that are followed by !. You might try this:
const re = regex('gis')`<b>.*?</b>!`;
// This is OK
'<b>Hi</b>! <b>Bye</b>.'.match(re);
// → ['<b>Hi</b>!']
// But not this
'<b>Hi</b>. <b>Bye</b>!'.match(re);
// → ['<b>Hi</b>. <b>Bye</b>!'] 👎
What happened with the second string was that, when an ! wasn't found immediately following the first </b>, the regex engine backtracked and expanded the lazy .*? to match an additional character (in this case, the < of the </b> tag) and then continued onward, all the way to just before the </b>! at the end.
You can prevent this by wrapping the lazily quantified token and its following delimiter in an atomic group, as follows:
const re = regex('gis')`<b>(?>.*?</b>)!`;
'<b>Hi</b>. <b>Bye</b>!'.match(re);
// → ['<b>Bye</b>!'] 👍
Now, after the regex engine finds the first </b> and exits the atomic group, it can no longer backtrack into the group and change what the .*? already matched. As a result, the match attempt fails at the beginning of this example string. The regex engine then moves on and starts over at subsequent positions in the string, eventually finding <b>Bye</b>!. Success.
[!NOTE] Atomic groups are supported in many other regex flavors. There's a proposal to add them to JavaScript.
Possessive quantifiers are created by adding + to a quantifier, and they're similar to greedy quantifiers except they don't allow backtracking. Although greedy quantifiers start out by matching as much as possible, if the remainder of the regex doesn't find a match, the regex engine will backtrack and try all permutations of how many times the quantifier should repeat. Possessive quantifiers prevent the regex engine from doing this.
Possessive quantifiers are syntactic sugar for atomic groups when their contents are a single repeated item (which could be a token, character class, or group).
Like atomic groups, possessive quantifiers are mostly useful for performance and preventing ReDoS, but they can also be used to eliminate certain matches. For example, regex`a++.` matches one or more a followed by a character other than a. Unlike /a+./, it won't match a sequence of only a characters like 'aaa'. The possessive ++ doesn't give back any of the as it matched, so in this case there's nothing left for the . to match.
Here's how possessive quantifier syntax compares to the greedy and lazy quantifiers that JavaScript supports natively:
| Greedy | Lazy | Possessive | |
|---|---|---|---|
| Repeat | As many times as possible, giving back as needed | As few times as possible, expanding as needed | As many times as possible, without giving back |
| Zero or one | ? | ?? | ?+ |
| Zero or more | * | *? | *+ |
| One or more | + | +? | ++ |
| N or more | {2,} | {2,}? | {2,}+ |
| Between N and M | {0,5} | {0,5}? | {0,5}+ |
Fixed repetition quantifiers behave the same whether they're greedy
{2}, lazy{2}?, or possessive{2}+.
[!NOTE] Possessive quantifiers are supported in many other regex flavors. There's a proposal to add them to JavaScript.
Subroutines are written as \g<name> (where name refers to a named group), and they treat the referenced group as an independent subpattern that they try to match at the current position. This enables subpattern composition and reuse, which improves readability and maintainability.
The following example illustrates how subroutines and backreferences differ:
// A backreference with \k<name>
regex`(?<prefix>sens|respons)e\ and\ \k<prefix>ibility`
/* Matches:
- 'sense and sensibility'
- 'response and responsibility' */
// A subroutine with \g<name>
regex`(?<prefix>sens|respons)e\ and\ \g<prefix>ibility`
/* Matches:
- 'sense and sensibility'
- 'sense and responsibility'
- 'response and sensibility'
- 'response and responsibility' */
Subroutines go beyond the composition benefits of interpolation. Apart from the obvious difference that they don't require variables to be defined outside of the regex, they also don't simply insert the referenced subpattern.
To illustrate points 2 and 3, consider:
regex`
(?<double> (?<char>.)\k<char>)
\g<double>
\k<double>
`
The backreference \k<double> matches whatever was matched by capturing group (?<double>…), regardless of what was matched in between by the subroutine \g<double>. For example, this regex matches 'xx!!xx', but not 'xx!!!!'.
regex, subroutines are applied after interpolation, giving them maximal flexibility.The following regex matches an IPv4 address such as "192.168.12.123":
const ipv4 = regex`
\b \g<byte> (\. \g<byte>){3} \b
# Define the 'byte' subpattern
(?<byte> 25[0-5] | 2[0-4]\d | 1\d\d | [1-9]?\d){0}
`;
Above, the {0} quantifier at the end of the (?<byte>…) group allows defining the group without matching it at that position. The subpattern within it can then be used by reference elsewhere within the pattern.
This next regex matches a record with multiple date fields, and captures each value:
const record = regex`
^ Admitted:\ (?<admitted> \g<date>) \n
Released:\ (?<released> \g<date>) $
# Define subpatterns
( (?<date> \g<year>-\g<month>-\g<day>)
(?<year> \d{4})
(?<month> \d{2})
(?<day> \d{2})
){0}
`;
Here, the {0} quantifier at the end once again prevents matching its group at that position, while enabling all of the named groups within it to be used by reference.
When using a regex to find matches (e.g. via the string matchAll method), named groups defined this way appear on each match's groups object, with the value undefined (which is the value for any capturing group that didn't participate in a match). See the next section Subroutine definition groups for a way to prevent such groups from appearing on the groups object.
[!NOTE] Subroutines are based on the feature in PCRE and Perl. PCRE allows several syntax options including
\g<name>, whereas Perl uses(?&name). Ruby also supports subroutines (and uses the\g<name>syntax), but it has behavior differences that make its subroutines not always act as independent subpatterns.
The syntax (?(DEFINE)…) can be used at the end of a regex to define subpatterns for use by reference only. When combined with subroutines, this enables writing regexes in a grammatical way that can significantly improve readability and maintainability.
Named groups defined within subroutine definition groups don't appear on the
groupsobject of matches.
Example:
const re = regex`
^ Admitted:\ (?<admitted> \g<date>) \n
Released:\ (?<released> \g<date>) $
(?(DEFINE)
(?<date> \g<year>-\g<month>-\g<day>)
(?<year> \d{4})
(?<month> \d{2})
(?<day> \d{2})
)
`;
const record = 'Admitted: 2024-01-01\nReleased: 2024-01-03';
const match = re.exec(record); // Same as `record.match(re)`
console.log(match.groups);
/* → {
admitted: '2024-01-01',
released: '2024-01-03'
} */
[!NOTE] Subroutine definition groups are based on the feature in PCRE and Perl. However,
regexsupports a stricter version since it limits their placement, quantity, and the top-level syntax that can be used within them.
DEFINE must appear in uppercase.The regex plugin regex-recursion enables the syntax (?R) and \g<name> to match recursive patterns up to a specified max depth. This allows matching balanced constructs.
Flags are added like this:
regex('gm')`^.+`
RegExp instances interpolated into the pattern preserve their own flags locally (see Interpolating regexes).
Flag v and emulated flags x and n are always on when using regex, giving your regexes a modern baseline syntax and avoiding the need to continually opt-in to their superior modes.
For special situations such as when using
regexwithin other tools, implicit flags can be disabled. See: Options.
vJavaScript's native flag v gives you the best level of Unicode support, strict errors, and all the latest regex features like character class set operations and properties of strings (see MDN). It's always on when using regex, which helps avoid numerous Unicode-related bugs, and means there's only one way to parse a regex instead of four (so you only need to remember one set of regex syntax and behavior).
Flag v is applied to the full pattern after interpolation happens.
In environments without native support for flag v, flag u is automatically used instead while applying v's escaping rules so your regexes are forward and backward compatible.
xEmulated flag x makes whitespace insignificant and adds support for line comments (starting with #), allowing you to freely format your regexes for readability. It's always implicitly on, though it doesn't extend into interpolated RegExp instances (to avoid changing their meaning).
Example:
const re = regex`
# Match a date in YYYY-MM-DD format
(?<year> \d{4} ) - # Year part
(?<month> \d{2} ) - # Month part
(?<day> \d{2} ) # Day part
# Escape whitespace and hashes to match them literally
\ # space char
\x20 # space char
\# # hash char
\s # any whitespace char
# Since embedded strings are always matched literally, you can also match
# whitespace by embedding it as a string
${' '}+
# Patterns are directly embedded, so they use free spacing
${pattern`\d + | [a - z]`}
# Interpolated regexes use their own flags, so they preserve their whitespace
${/^Fat cat$/m}
`;
[!NOTE] Flag x is based on the JavaScript proposal for it as well as support in many other regex flavors. Note that the rules for whitespace within character classes are inconsistent across regex flavors, so
regexfollows the JavaScript proposal and the flag xx option from Perl and PCRE.
# is not a special character. It matches a literal # and doesn't start a comment. Additionally, the only insignificant whitespace characters within character classes are space and tab.\s.\0 1, which matches a null character followed by a literal 1, rather than throwing as the invalid token \01 would. Conversely, things like \x 0A and (? : are errors because the whitespace splits a valid node into incomplete parts.x + is equivalent to x+.\p{…} and \u{…}. The exception is [\q{…}].# do not extend into or beyond interpolation, so interpolation effectively acts as a terminating newline for the comment.nEmulated flag n gives you named capture only mode, which prevents the grouping metacharacters (…) from capturing. It's always implicitly on, though it doesn't extend into interpolated RegExp instances (to avoid changing their meaning).
Requiring the syntactically clumsy (?:…) where you could just use (…) hurts readability and encourages adding unneeded captures (which hurt efficiency and refactoring). Flag n fixes this, making your regexes more readable.
Example:
// Doesn't capture
regex`\b(ab|cd)\b`
// Use standard (?<name>…) to capture as `name`
[!NOTE] Flag n is based on .NET, C++, PCRE, Perl, and XRegExp, which share the n flag letter but call it explicit capture, no auto capture, or nosubs. In
regex, the implicit flag n also prevents using numbered backreferences to refer to named groups in the outer regex, which follows the behavior of C++ (Ruby also always prevents this, despite not having flag n). Referring to named groups by number is a footgun, and the way that named groups are numbered is inconsistent across regex flavors.
The meaning of flags (or their absense) on interpolated regexes is preserved. For example, with flag i (ignoreCase):
regex`hello-${/world/i}`
// Matches 'hello-WORLD' but not 'HELLO-WORLD'
regex('i')`hello-${/world/}`
// Matches 'HELLO-world' but not 'HELLO-WORLD'
This is also true for other flags that can change how an inner regex is matched: m (multiline) and s (dotAll).
As with all interpolation in
regex, embedded regexes are sandboxed and treated as complete units. For example, a following quantifier repeats the entire embedded regex rather than just its last token, and top-level alternation in the embedded regex will not break out to affect the meaning of the outer regex. Numbered backreferences within embedded regexes are adjusted to work within the overall pattern.
regex`[${/./}]` is an error) because the syntax context doesn't match. See Interpolating partial patterns for a way to safely embed regex syntax (rather than RegExp instances) in character classes and other edge-case locations with different context.RegExp to copy a regex while providing new flags. E.g. new RegExp(/./, 's').regex escapes special characters in interpolated strings (and values coerced to strings). This escaping is done in a context-aware and safe way that prevents changing the meaning or error status of characters outside the interpolated string.
As with all interpolation in
regex, escaped strings are sandboxed and treated as complete units. For example, a following quantifier repeats the entire escaped string rather than just its last character. And if interpolating into a character class, the escaped string is treated as a flag-v-mode nested union if it contains more than one character node.
As a result, regex is a safe and context-aware alternative to JavaScript proposal RegExp.escape.
// Instead of
RegExp.escape(str)
// You can say
regex`${str}`.source
// Instead of
new RegExp(`^(?:${RegExp.escape(str)})+$`)
// You can say
regex`^${str}+$`
// Instead of
new RegExp(`[a-${RegExp.escape(str)}]`, 'u') // Flag u/v required to avoid bugs
// You can say
regex`[a-${str}]`
// Given the context at the end of a range, throws if more than one char in str
// Instead of
new RegExp(`[\\w--[${RegExp.escape(str)}]]`, 'v')
// You can say
regex`[\w--${str}]`
Some examples of where context awareness comes into play:
~ is not escaped at the top level, but it must be escaped within character classes in case it's immediately followed by another ~ (in or outside of the interpolation) which would turn it into a reserved UnicodeSets double punctuator.\0, else RegExp throws (or in Unicode-unaware mode they might turn into octal escapes).A-Z and a-z must be escaped if preceded by uncompleted token \c, else they'll convert what should be an error into a valid token that probably doesn't match what you expect.\. Doing nothing could turn e.g. w into \w and introduce a bug, but then escaping the first character wouldn't prevent the \ from mangling it, and if you escaped the preceding \ elsewhere in your code you'd change its meaning.These and other issues (including the effects of current and potential future flags like x) make escaping without context unsafe to use at arbitrary positions in a regex, or at least complicated to get right. The existing popular regex escaping libraries don't even attempt to handle these kinds of issues.
regex solves all of this via context awareness. So instead of remembering anything above, you should just switch to always safely escaping regex syntax via regex.
As an alternative to interpolating RegExp instances, you might sometimes want to interpolate partial regex patterns as strings. Some example use cases:
RegExp instances since their top-level syntax context doesn't match).RegExp).For all of these cases, you can interpolate pattern(str) to avoid escaping special characters in the string or creating an intermediary RegExp instance. You can also use pattern`…` as a tag, as shorthand for pattern(String.raw`…`).
Apart from edge cases, pattern just embeds the provided string or other value directly. But because it handles the edge cases, patterns can safely be interpolated anywhere in a regex without worrying about their meaning being changed by (or making unintended changes in meaning to) the surrounding pattern.
As with all interpolation in
regex, patterns are sandboxed and treated as complete units. This is relevant e.g. if a pattern is followed by a quantifier, if it contains top-level alternation, or if it's bordered by a character class range, subtraction, or intersection operator.
If you want to understand the handling of interpolated patterns more deeply, let's look at some edge cases…
First, let's consider:
regex`[${pattern`^`}a]`
regex`[a${pattern`^`}]`
Although [^…] is a negated character class, ^ within a class doesn't need to be escaped, even with the strict escaping rules of flags u and v.
Both of these examples therefore match a literal ^. The interpolated patterns don't change the meaning of the surrounding character class. However, note that the ^ is not simply escaped. pattern`^^` embedded in character class context would still correctly lead to an "invalid set operation" error due to the use of a reserved double-punctuator.
If you wanted to dynamically choose whether to negate a character class, you could put the whole character class inside the pattern.
Moving on, the following lines all throw because otherwise the embedded patterns would break out of their interpolation sandboxes and change the meaning of surrounding syntax:
regex`(${pattern(')')})`
regex`[${pattern(']')}]`
regex`[${pattern('a\\')}]]`
But these are fine since they don't break out:
regex`(${pattern('()')})`
regex`[\w--${pattern('[_]')}]`
regex`[${pattern('\\\\')}]`
Patterns can be embedded within any token scope:
// Not using `pattern` for values that are not escaped anyway, but the behavior
// would be the same if you did
regex`.{1,${6}}`
regex`\p{${'Letter'}}`
regex`\u{${'000A'}}`
regex`(?<${'name'}>…)\k<${'name'}>`
regex`[a-${'z'}]`
regex`[\w--${'_'}]`
But again, changing the meaning or error status of characters outside the interpolation is an error:
// Not using `pattern` for values that are not escaped anyway
/* 1.*/ regex`\u${'000A'}`
/* 2.*/ regex`\u{${pattern`A}`}`
/* 3.*/ regex`(${pattern`?:`}…)`
These last examples are all errors due to the corresponding reasons below:
\u token (which is an error) followed by the tokens 0, 0, 0, A. That's because the interpolation doesn't happen within an enclosed \u{…} context.} within the interpolated pattern is not allowed to break out of its sandbox.( can't be quantified with ?.Characters outside the interpolation such as a preceding, unescaped
\or an escaped number also can't change the meaning of tokens inside the embedded pattern.
And since interpolated values are handled as complete units, consider the following:
// This works fine
regex`[\0-${pattern`\cZ`}]`
// But this is an error since you can't create a range from 'a' to the set 'de'
regex`[a-${'de'}]`
// It's the same as if you tried to use /[a-[de]]/v
// Instead, use either of
regex`[a-${'d'}${'e'}]`
regex`[a-${'d'}e]`
// These are equivalent to /[a-de]/ or /[[a-d][e]]/v
Implementation note:
patternreturns an object with a customtoStringthat simply returnsString(value).
The above descriptions of interpolation might feel complex. But there are three simple rules that guide the behavior in all cases:
Examples where rule #3 is relevant: With following quantifiers, if they contain top-level alternation or numbered backreferences, or if they're placed in a character class range or set operation.
| Context | Example | String / coerced | Pattern | RegExp |
|---|---|---|---|---|
| Default | regex`${'^.+'}` | • Sandboxed • Atomized • Escaped | • Sandboxed • Atomized | • Sandboxed • Atomized • Backrefs adjusted • Flags localized |
Character class: […], [^…], [[…]], etc. | regex`[${'a-z'}]` | • Sandboxed • Atomized • Escaped | • Sandboxed • Atomized | Error |
Interval quantifier: {…} | regex`.{1,${5}}` | • Sandboxed • Escaped | • Sandboxed | Error |
Enclosed token: \p{…}, \P{…}, \u{…}, [\q{…}] | regex`\u{${'A0'}}` | |||
Group name: (?<…>), \k<…>, \g<…> | regex`…\k<${'a'}>` |
${x}* matches any number of the value specified by x, and not just its last token. In character class context, subtraction and intersection operators apply to the entire atom.a or \u0061) can be interpolated at these positions.The implementation details vary for how
regexaccomplishes sandboxing and atomization, based on the details of the specific pattern. But the concepts should always hold up.
Typically, regex is used as follows:
regex`…` // Without flags
regex('gi')`…` // With flags
However, several options are available that can be provided via an options object in place of the flags argument. These options aren't usually needed, and are primarily intended for use within other tools.
Following are the available options and their default values:
regex({
flags: '',
subclass: false,
plugins: [],
unicodeSetsPlugin: <function>
disable: {
x: false,
n: false,
v: false,
atomic: false,
subroutines: false,
},
force: {
v: false,
},
})`…`;
flags — For providing flags when using an options object.
subclass — When true, the resulting regex is constructed using a RegExp subclass that avoids edge case issues with numbered backreferences. Without subclassing, submatches referenced by number from outside of the regex (e.g. in replacement strings) might reference the wrong values, because regex's emulation of extended syntax (including atomic groups and subroutines) can add anonymous captures to generated regex source that might affect group numbering.
Context: regex's implicit flag n (named capture only mode) means that all captures have names, so normally there's no need to reference submatches by number. In fact, flag n prevents you from doing so within the regex. And even in edge cases (such as when interpolating RegExp instances with numbered backreferences, or when flag n is explicitly disabled), any numbered backreferences within the regex are automatically adjusted to work correctly. However, issues can arise if you reference submatches by number (instead of their group names) from outside of the regex. Setting subclass: true resolves this, since the subclass knows about added "emulation groups" and automatically adjusts match results in all contexts.
This option isn't enabled by default because it would prevent
regex's Babel plugin from emitting regex literals. It also has a small performance cost, and is rarely needed. The primary use case is tools that useregexinternally with flag n disabled.
plugins — An array of functions. Plugins are called in order, after applying emulated flags and interpolation, but before the built-in plugins for extended syntax. This means that plugins can output extended syntax like atomic groups and subroutines. Plugins are expected to return an updated pattern string, and are called with two arguments:
flags property that includes the native (non-emulated) flags that will be used by the regex.The final result after running all plugins is provided to the RegExp constructor.
The tiny regex-utilities library is intended for use in plugins, and can make it easier to work with regex syntax.
unicodeSetsPlugin — A plugin function that's used when flag v isn't supported natively, or when implicit flag v is disabled. The default value is a built-in function that provides basic backward compatibility by applying flag v's escaping rules and throwing on use of v-only syntax (nested character classes, set subtraction/intersection, etc.).
regexis not primarily a backward compatibility library, so in order to remain lightweight, it doesn't transpile flag v's new features out of the box. By replacing the default function, you can add backward compatible support for these features. See also: Compatibility.
This plugin runs last, which means it's possible to wrap an existing library (e.g. regexpu-core, used by Babel to transpile v), without the library needing to understand
regex's extended syntax.
disable — A set of options that can be individually disabled by setting their values to true.
x — Disables implicit, emulated flag x.n — Disables implicit, emulated flag n. Note that, although it's safe to use anonymous captures and numbered backreferences within a regex when flag n is disabled, referencing submatches by number from outside a regex (e.g. in replacement strings) can result in incorrect values because extended syntax (atomic groups and subroutines) might add "emulation groups" to generated regex source. It's therefore recommended to enable option subclass when disabling n.v — Disables implicit flag v even when it's supported natively, resulting in flag u being added instead (in combination with the unicodeSetsPlugin).atomic — Disables atomic groups and possessive quantifiers, resulting in a syntax error if they're used.subroutines — Disables subroutines and subroutine definition groups, resulting in a syntax error if they're used.force — Options that, if set to true, override default settings (as well as options set on the disable object).
v — Forces the use of flag v even when it's not supported natively (resulting in an error).regex transpiles its input to native RegExp instances. Therefore regexes created by regex perform equally as fast as native regexes. The use of regex can also be transpiled via a Babel plugin, avoiding the tiny overhead of transpiling at runtime.
For regexes that rely on or have the potential to trigger heavy backtracking, you can dramatically improve beyond native performance via regex's atomic groups and possessive quantifiers.
regex uses flag v (unicodeSets) when it's supported natively. Flag v is supported by 2023-era browsers (compat table) and Node.js 20. When v isn't available, flag u is automatically used instead (while still enforcing v's escaping rules), which extends support to Node.js 14 and 2020-era browsers (2017-era with a build step that transpiles private class fields, string matchAll, array flatMap, and the ?? and ?. operators).
The following edge cases rely on modern JavaScript features:
regex uses nested character classes (which require flag v) when interpolating more than one token at a time inside character classes. A descriptive error is thrown when this isn't supported, which you can avoid by not interpolating multi-token patterns or strings into character classes.RegExp instance with a different value for flag i than its outer regex relies on pattern modifiers, a bleeding-edge feature available in Chrome/Edge 125 and Opera 111. A descriptive error is thrown in environments without support, which you can avoid by aligning the use of flag i on inner and outer regexes. Local-only application of other flags doesn't rely on this feature.The claim that JavaScript with the regex library is among the best regex flavors is based on a holistic view. Following are some of the aspects considered:
regex library adds atomic groups to native JavaScript regexes, which is a solution to this problem and therefore can dramatically improve performance.regex library not only adds x (and turns it on by default), but it additionally adds regex subroutines and subroutine definition groups (matched only by PCRE and Perl, although some other flavors have inferior versions) which enable powerful subpattern composition and reuse. And it includes context-aware interpolation of RegExp instances, escaped strings, and partial patterns, all of which can also help with composition and readability.regex be called as a function instead of using it with backticks?Yes, but you might not need to. If you want to use regex with dynamic input, you can interpolate a pattern call as the full expression. For example:
import {regex, pattern} from 'regex';
const str = '…';
const re = regex('g')`${pattern(str)}`;
If you prefer to call regex as a function (rather than using it as a template tag), that requires explicitly providing the raw template strings array, as follows:
import {regex} from 'regex';
const str = '…';
const re = regex('g')({raw: [str]});
regex('g')`…` rather than regex`/…/g`?The alternative syntax isn't used because it has several disadvantages:
RegExp constructor's syntax./ outside of character classes.`/…/g` format.regex was partly inspired by XRegExp's .tag and regexp-make-js.
Crafted by Steven Levithan with love for regular expressions and their enthusiasts.
MIT License.
FAQs
Regex template tag with extended syntax, context-aware interpolation, and always-on best practices
The npm package regex receives a total of 728,004 weekly downloads. As such, regex popularity was classified as popular.
We found that regex demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
npm has a revamped search experience with new, more transparent sorting options—Relevance, Downloads, Dependents, and Publish Date.

Security News
A supply chain attack has been detected in versions 1.95.6 and 1.95.7 of the popular @solana/web3.js library.

Research
Security News
A malicious npm package targets Solana developers, rerouting funds in 2% of transactions to a hardcoded address.