Security News
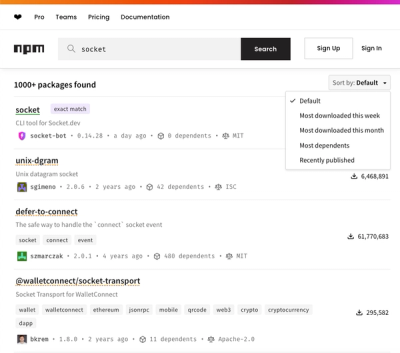
npm Updates Search Experience with New Objective Sorting Options
npm has a revamped search experience with new, more transparent sorting options—Relevance, Downloads, Dependents, and Publish Date.
By Sarah Gooding - Dec 05, 2024
A web scraping tool built with TypeScript, utilizing Cheerio and Axios to fetch and filter HTML content from web pages.
A web scraping tool built with TypeScript, utilizing Cheerio and Axios to fetch and filter HTML content from web pages.
npm install scrapyyy
First, import the scraper module and use it to scrape web pages.
import { scraper } from "scrapyyy";
// Example usage
(async () => {
const result = await scraper("https://example.com", {
onlyData: true,
includeTags: ["div", "span"],
excludeTags: ["script", "style"],
selector: ["#content", ".main"],
});
console.log(result);
})();
scraper(url, options):
string): The URL of the webpage to scrape.object): Optional configuration to modify the scraping process.
boolean): If true, returns only the text content of the page (default: false).string[]): List of tag names to include in the result.string[]): List of tag names to exclude from the result.string[]): CSS selectors to filter the content (e.g., #id, .class, tagName).const html = await scraper("https://example.com");
console.log(html); // Full HTML content of the page
const filtered = await scraper("https://example.com", {
includeTags: ["html", "body", "head", "title", "p", "div"],
excludeTags: ["script"],
});
console.log(filtered); // HTML content with only <p> and <div>, excluding <script>
Note : If you are including a certain tag but not its parent tag, it won't be present in the result.
eg. If you include p tag but not include body, no p tags will actually be included.
const selectedContent = await scraper("https://example.com", {
selector: [".header", "#main"],
});
console.log(selectedContent); // Text content from elements matching the provided selectors
const data = await scraper("https://example.com", { onlyData: true });
console.log(data); // Plain text content of the page
MIT
FAQs
A web scraping tool built with TypeScript, utilizing Cheerio and Axios to fetch and filter HTML content from web pages.
We found that scrapyyy demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 0 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
npm has a revamped search experience with new, more transparent sorting options—Relevance, Downloads, Dependents, and Publish Date.

Security News
A supply chain attack has been detected in versions 1.95.6 and 1.95.7 of the popular @solana/web3.js library.

Research
Security News
A malicious npm package targets Solana developers, rerouting funds in 2% of transactions to a hardcoded address.