
Platform CLI

Zapier is a platform for creating integrations and workflows. This CLI is your gateway to creating custom applications on the Zapier platform.
You may find some documents on the Zapier site duplicate or outdated. The most up-to-date contents are always available on GitHub:
Our code is updated frequently. To see a full list of changes, look no further than the CHANGELOG.
This doc describes the latest CLI version (15.16.0), as of this writing. If you're using an older version of the CLI, you may want to check out these historical releases:
Table of Contents
Getting Started
If you're new to Zapier Platform CLI, we strongly recommend you to walk through the Tutorial for a more thorough introduction.
What is an App?
Note: this document uses "app" while modern Zapier nomenclature refers instead to "integrations". In both cases, the phrase refers to your code that connects your API with Zapier.
A CLI App is an implementation of your app's API. You build a Node.js application
that exports a single object (JSON Schema) and upload it to Zapier.
Zapier introspects that definition to find out what your app is capable of and
what options to present end users in the Zap Editor.
For those not familiar with Zapier terminology, here is how concepts in the CLI map to the end user experience:
- Authentication, (usually) which lets us know what credentials to ask users
for. This is used during the "Connect Accounts" section of the Zap Editor.
- Triggers, which read data from your API. These have their own section in the Zap Editor.
- Creates, which send data to your API to create new records. These are listed under "Actions" in the Zap Editor.
- Searches, which find specific records in your system. These are also listed under "Actions" in the Zap Editor.
- Resources, which define an object type in your API (say a contact) and the operations available to perform on it. These are automatically extracted into Triggers, Searches, and Creates.
How does Zapier Platform CLI Work?
Zapier takes the App you upload and sends it over to Amazon Web Service's Lambda. We then make calls to execute the operations your App defines as we execute Zaps. Your App takes the input data we provide (if any), makes the necessary HTTP calls, and returns the relevant data, which gets fed back into Zapier.
Zapier Platform CLI vs UI
The Zapier Platform includes two ways to build integrations: a CLI (to build integrations in your local development environment and deploy them from the command line), and a Visual Builder (to create integrations with a visual builder from your browser). Both use the same underlying platform, so pick the one that fits your team's needs best. The main difference is how you make changes to your code.
Zapier Platform CLI is designed to be used by development teams who collaborate with version control and CI, and can be used to build more advanced integrations with custom coding for every part of your API calls and response parsing.
Zapier Platform UI is designed to quickly spin up new integrations, and collaborate on them with teams that include non-developers. It's the quickest way to start using the Zapier platform—and you can manage your CLI apps' core details from its online UI as well. You can also export Zapier Platform UI integrations to CLI to start development in your browser, then finish out the core features in your local development environment.
Learn more in our Zapier Platform UI vs CLI post.
Requirements
All Zapier CLI apps are run using Node.js v18.
You can develop using any version of Node you'd like, but your eventual code must be compatible with v18. If you're using features not yet available in v18, you can transpile your code to a compatible format with Babel (or similar).
To ensure stability for our users, we strongly encourage you run tests on v18 sometime before your code reaches users. This can be done multiple ways.
Firstly, by using a CI tool (like Travis CI or Circle CI, which are free for open source projects). We provide a sample .travis.yml file in our template apps to get you started.
Alternatively, you can change your local node version with tools such as nvm. Then you can either swap to that version with nvm use v18, or do nvm exec v18 zapier test so you can run tests without having to switch versions while developing.
Quick Setup Guide
First up is installing the CLI and setting up your auth to create a working "Zapier Example" application. It will be private to you and visible in your live Zap Editor.
npm install -g zapier-platform-cli
zapier login
Note: If you log into Zapier via the single sign-on (Google, Facebook, or Microsoft), you may not have a Zapier password. If that's the case, you'll need to generate a deploy key, go to your Zapier developer account here and create/copy a key, then run zapier login command with the --sso flag.
Your Zapier CLI should be installed and ready to go at this point. Next up, we'll create our first app!
zapier init example-app
> Note: When you run `zapier init`, you'll be presented with a list of templates to start with. Pick the one that matches a feature you'll need (such as "dynamic-dropdown" for an integration with [dynamic dropdown fields](https://github.com/zapier/zapier-platform/blob/main/packages/cli/README.md
cd example-app
npm install
Depending on the authentication method for your app, you'll also likely need to set your CLIENT_ID and CLIENT_SECRET as environment variables. These are the consumer key and secret in OAuth1 terminology.
$ zapier env:set 1.0.0 CLIENT_ID=1234
$ zapier env:set 1.0.0 CLIENT_SECRET=abcd
You should now have a working local app. You can run several local commands to try it out.
zapier test
Next, you'll probably want to upload app to Zapier itself so you can start testing live.
zapier push
Go check out our full CLI reference documentation to see all the other commands!
Tutorial
For a full tutorial, head over to our Tutorial for a comprehensive walkthrough for creating your first app. If this isn't your first rodeo, read on!
Creating a Local App
Tip: Check the Quick Setup if this is your first time using the platform!
Creating an App can be done entirely locally and they are fairly simple Node.js apps using the standard Node environment and should be completely testable. However, a local app stays local until you zapier register.
mkdir zapier-example
cd zapier-example
zapier init . --template minimal
npm install
If you'd like to manage your local App, use these commands:
zapier init myapp - initialize/start a local app projectzapier convert 1234 . - initialize/start from an existing appzapier scaffold resource Contact - auto-injects a new resource, trigger, etc.zapier test - run the same tests as npm testzapier validate - ensure your app is validzapier describe - print some helpful information about your app
Local Project Structure
In your app's folder, you should see this general recommended structure. The index.js is Zapier's entry point to your app. Zapier expects you to export an App definition there.
$ tree .
.
├── README.md
├── index.js
├── package.json
├── triggers
│ └── contact-by-tag.js
├── resources
│ └── Contact.js
├── test
│ ├── basic.js
│ ├── triggers.js
│ └── resources.js
├── build
│ └── build.zip
└── node_modules
├── ...
└── ...
Local App Definition
The core definition of your App will look something like this, and is what your index.js should provide as the only export:
const App = {
version: require('./package.json').version,
platformVersion: require('zapier-platform-core').version,
authentication: {},
hydrators: {},
requestTemplate: {},
beforeRequest: [],
afterResponse: [],
resources: {},
triggers: {},
searches: {},
creates: {},
};
module.exports = App;
Tip: You can use higher order functions to create any part of your App definition!
Registering an App
Registering your App with Zapier is a necessary first step which only enables basic administrative functions. It should happen before zapier push which is to used to actually expose an App Version in the Zapier interface and editor.
zapier register "Zapier Example"
zapier integrations
Note: This doesn't put your app in the editor - see the docs on pushing an App Version to do that!
If you'd like to manage your App, use these commands:
zapier integrations - list the apps in Zapier you can administerzapier register "App Title" - creates a new app in Zapierzapier link - lists and links a selected app in Zapier to your current folderzapier history - print the history of your appzapier team:add user@example.com admin - add an admin to help maintain/develop your appzapier users:add user@example.com 1.0.0 - invite a user try your app version 1.0.0
Deploying an App Version
An App Version is related to a specific App but is an "immutable" implementation of your app. This makes it easy to run multiple versions for multiple users concurrently. The App Version is pulled from the version within the package.json. To create a new App Version, update the version number in that file. By default, every App Version is private but you can zapier promote it to production for use by over 1 million Zapier users.
zapier push
zapier versions
If you'd like to manage your Version, use these commands:
zapier versions - list the versions for the current directory's appzapier push - push the current version of current directory's app & version (read from package.json)zapier promote 1.0.0 - mark a version as the "production" versionzapier migrate 1.0.0 1.0.1 [100%] - move users between versions, regardless of deployment statuszapier deprecate 1.0.0 2020-06-01 - mark a version as deprecated, but let users continue to use it (we'll email them)zapier env:set 1.0.0 KEY=VALUE - set an environment variable to some valuezapier delete:version 1.0.0 - delete a version entirely. This is mostly for clearing out old test apps you used personally. It will fail if there are any users. You probably want deprecate instead.
Note: To see the changes that were just pushed reflected in the browser, you have to manually refresh the browser each time you push.
Private App Version (default)
A simple zapier push will only create the App Version in your editor. No one else using Zapier can see it or use it.
Sharing an App Version
This is how you would share your app with friends, co-workers or clients. This is perfect for quality assurance, testing with active users or just sharing any app you like.
zapier users:add user@example.com 1.0.0
zapier team:add user@example.com
You can also invite anyone on the internet to your app by using the links from zapier users:links. The link should look something like https://zapier.com/platform/public-invite/1/222dcd03aed943a8676dc80e2427a40d/. You can put this in your help docs, post it to Twitter, add it to your email campaign, etc. You can choose an invite link specific to an app version or for the entire app (i.e. all app versions).
Promoting an App Version
Promotion is how you would share your app with every one of the 1 million+ Zapier users. If this is your first time promoting - you may have to wait for the Zapier team to review and approve your app.
If this isn't the first time you've promoted your app - you might have users on older versions. You can zapier migrate to either move users over (which can be dangerous if you have breaking changes). Or, you can zapier deprecate to give users some time to move over themselves.
zapier promote 1.0.1
zapier migrate 1.0.0 1.0.1
zapier deprecate 1.0.0 2020-06-01
Converting an Existing App
If you have an existing Zapier legacy Web Builder app, you can use it as a template to kickstart your local application.
zapier convert 1234 my-app
Your CLI app will be created and you can continue working on it.
Note: There is no way to convert a CLI app to a Web Builder app and we do not plan on implementing this.
Introduced in v8.2.0, you are able to convert new integrations built in Zapier Platform UI to CLI.
zapier convert 1234 --version 1.0.1 my-app
Authentication
Most applications require some sort of authentication. The Zapier platform provides core behaviors for several common authentication methods that might be used with your application, as well as the ability to customize authentication further.
When a user authenticates to your application through Zapier, a "connection" is created representing their authentication details. Data tied to a specific authentication connection is included in the bundle object under bundle.authData.
Basic
Useful if your app requires two pieces of information to authenticate: username and password, which only the end user can provide. By default, Zapier will do the standard Basic authentication base64 header encoding for you (via an automatically registered middleware).
To create a new integration with basic authentication, run zapier init [your app name] --template basic-auth. You can also review an example of that code here.
If your app uses Basic auth with an encoded API key rather than a username and password, like Authorization: Basic APIKEYHERE:x, consider the Custom authentication method instead.
const authentication = {
type: 'basic',
test: {
url: 'https://example.com/api/accounts/me.json',
},
connectionLabel: '{{username}}',
};
const App = {
authentication,
};
Digest
Added in v7.4.0.
The setup and user experience of Digest Auth is identical to Basic Auth. Users provide Zapier their username and password, and Zapier handles all the nonce and quality of protection details automatically.
To create a new integration with digest authentication, run zapier init [your app name] --template digest-auth. You can also review an example of that code here.
Limitation: Currently, MD5-sess and SHA are not implemented. Only the MD5 algorithm is supported. In addition, server nonces are not reused. That means for every z.request call, Zapier will send an additional request beforehand to get the server nonce.
const getConnectionLabel = (z, bundle) => {
return bundle.inputData.username;
};
const authentication = {
type: 'digest',
test: {
url: 'https://example.com/api/accounts/me.json',
},
connectionLabel: getConnectionLabel,
};
const App = {
authentication,
};
Custom
Custom auth is most commonly used for apps that authenticate with API keys, although it also provides flexibility for any unusual authentication setup. You'll likely provide some custom beforeRequest middleware or a requestTemplate (see Making HTTP Requests) to pass in data returned from the authentication process, most commonly by adding/computing needed headers.
To create a new integration with custom authentication, run zapier init [your app name] --template custom-auth. You can also review an example of that code here.
const authentication = {
type: 'custom',
test: {
url: 'https://{{bundle.authData.subdomain}}.example.com/api/accounts/me.json',
},
fields: [
{
key: 'subdomain',
type: 'string',
required: true,
helpText: 'Found in your browsers address bar after logging in.',
},
{
key: 'api_key',
type: 'string',
required: true,
helpText: 'Found on your settings page.',
},
],
};
const addApiKeyToHeader = (request, z, bundle) => {
request.headers['X-Subdomain'] = bundle.authData.subdomain;
const basicHash = Buffer.from(`${bundle.authData.api_key}:x`).toString(
'base64'
);
request.headers.Authorization = `Basic ${basicHash}`;
return request;
};
const App = {
authentication,
beforeRequest: [addApiKeyToHeader],
};
Session
Session auth gives you the ability to exchange some user-provided data for some authentication data; for example, username and password for a session key. It can be used to implement almost any authentication method that uses that pattern - for example, alternative OAuth flows.
To create a new integration with session authentication, run zapier init [your app name] --template session-auth. You can also review an example of that code here.
const getSessionKey = async (z, bundle) => {
const response = await z.request({
method: 'POST',
url: 'https://example.com/api/accounts/login.json',
body: {
username: bundle.authData.username,
password: bundle.authData.password,
},
});
return {
sessionKey: response.data.sessionKey,
};
};
const authentication = {
type: 'session',
test: {
url: 'https://example.com/api/accounts/me.json',
},
fields: [
{
key: 'username',
type: 'string',
required: true,
helpText: 'Your login username.',
},
{
key: 'password',
type: 'string',
required: true,
helpText: 'Your login password.',
},
],
sessionConfig: {
perform: getSessionKey,
},
};
const includeSessionKeyHeader = (request, z, bundle) => {
if (bundle.authData.sessionKey) {
request.headers = request.headers || {};
request.headers['X-Session-Key'] = bundle.authData.sessionKey;
}
return request;
};
const App = {
authentication,
beforeRequest: [includeSessionKeyHeader],
};
For Session auth, the function that fetches the additional authentication data needed to make API calls (authentication.sessionConfig.perform) has the user-provided fields in bundle.inputData. Afterwards, bundle.authData contains the data returned by that function (usually the session key or token).
OAuth1
Added in v7.5.0.
Zapier's OAuth1 implementation matches Twitter and Trello implementations of the 3-legged OAuth flow.
To create a new integration with OAuth1, run zapier init [your app name] --template oauth1-trello. You can also check out oauth1-trello, oauth1-tumblr, and oauth1-twitter for working example apps with OAuth1.
The flow works like this:
- Zapier makes a call to your API requesting a "request token" (also known as "temporary credentials").
- Zapier sends the user to the authorization URL, defined by your app, along with the request token.
- Once authorized, your website sends the user to the
redirect_uri Zapier provided. Use zapier describe command to find out what it is: 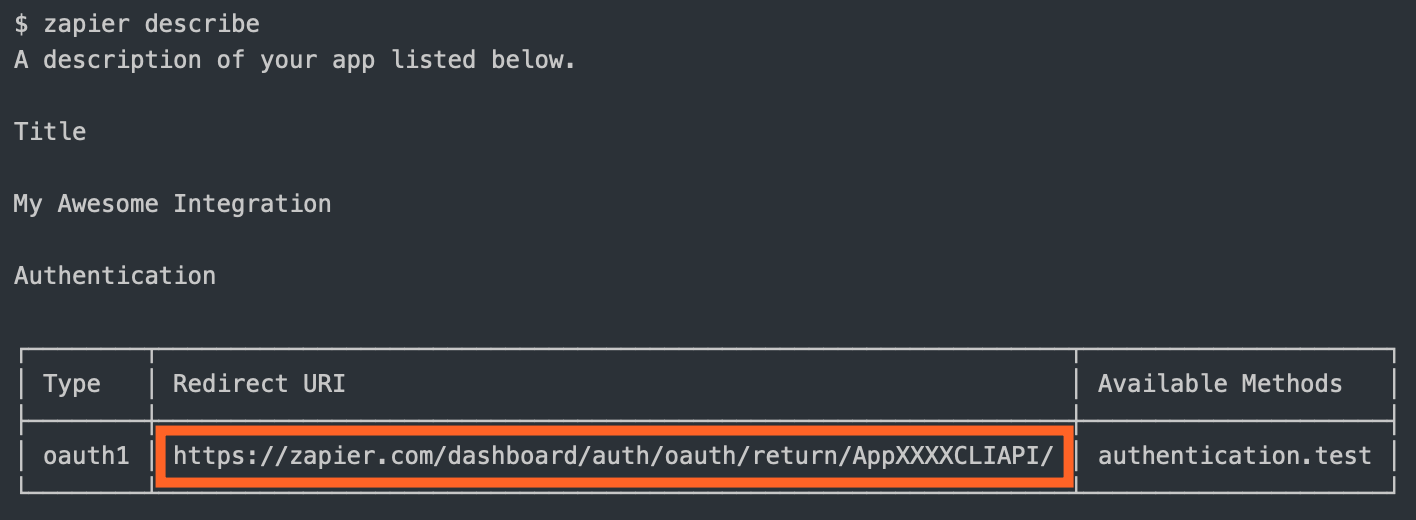
- Zapier makes a backend call to your API to exchange the request token for an "access token" (also known as "long-lived credentials").
- Zapier stores the
access_token and uses it to make calls on behalf of the user.
You are required to define:
getRequestToken: The API call to fetch the request tokenauthorizeUrl: The authorization URLgetAccessToken: The API call to fetch the access token
You'll also likely need to set your CLIENT_ID and CLIENT_SECRET as environment variables. These are the consumer key and secret in OAuth1 terminology.
$ zapier env:set 1.0.0 CLIENT_ID=1234
$ zapier env:set 1.0.0 CLIENT_SECRET=abcd
$ CLIENT_ID=1234 CLIENT_SECRET=abcd zapier test
Your auth definition would look something like this:
const _ = require('lodash');
const authentication = {
type: 'oauth1',
oauth1Config: {
getRequestToken: {
url: 'https://{{bundle.inputData.subdomain}}.example.com/request-token',
method: 'POST',
auth: {
oauth_consumer_key: '{{process.env.CLIENT_ID}}',
oauth_consumer_secret: '{{process.env.CLIENT_SECRET}}',
oauth_signature_method: 'HMAC-SHA1',
oauth_callback: '{{bundle.inputData.redirect_uri}}',
},
},
authorizeUrl: {
url: 'https://{{bundle.inputData.subdomain}}.example.com/authorize',
params: {
oauth_token: '{{bundle.inputData.oauth_token}}',
},
},
getAccessToken: {
url: 'https://{{bundle.inputData.subdomain}}.example.com/access-token',
method: 'POST',
auth: {
oauth_consumer_key: '{{process.env.CLIENT_ID}}',
oauth_consumer_secret: '{{process.env.CLIENT_SECRET}}',
oauth_token: '{{bundle.inputData.oauth_token}}',
oauth_token_secret: '{{bundle.inputData.oauth_token_secret}}',
oauth_verifier: '{{bundle.inputData.oauth_verifier}}',
},
},
},
test: {
url: 'https://{{bundle.authData.subdomain}}.example.com/me',
},
fields: [
{ key: 'subdomain', type: 'string', required: true, default: 'app' },
],
};
const includeAccessToken = (req, z, bundle) => {
if (
bundle.authData &&
bundle.authData.oauth_token &&
bundle.authData.oauth_token_secret
) {
req.auth = req.auth || {};
_.defaults(req.auth, {
oauth_consumer_key: process.env.CLIENT_ID,
oauth_consumer_secret: process.env.CLIENT_SECRET,
oauth_token: bundle.authData.oauth_token,
oauth_token_secret: bundle.authData.oauth_token_secret,
});
}
return req;
};
const App = {
authentication,
beforeRequest: [includeAccessToken],
};
module.exports = App;
For OAuth1, authentication.oauth1Config.getRequestToken, authentication.oauth1Config.authorizeUrl, and authentication.oauth1Config.getAccessToken have fields like redirect_uri and the temporary credentials in bundle.inputData. After getAccessToken runs, the resulting token value(s) will be stored in bundle.authData for the connection.
Also, authentication.oauth1Config.getAccessToken has access to the additional return values in rawRequest and cleanedRequest should you need to extract other values (for example, from the query string).
OAuth2
Zapier's OAuth2 implementation is based on the authorization_code flow, similar to GitHub and Facebook.
To create a new integration with OAuth2, run zapier init [your app name] --template oauth2. You can also check out our working example app.
If your app's OAuth2 flow uses a different grant type, such as client_credentials, try using Session auth instead.
The OAuth2 flow looks like this:
- Zapier sends the user to the authorization URL defined by your app.
- Once authorized, your website sends the user to the
redirect_uri Zapier provided. Use the zapier describe command to find out what it is: 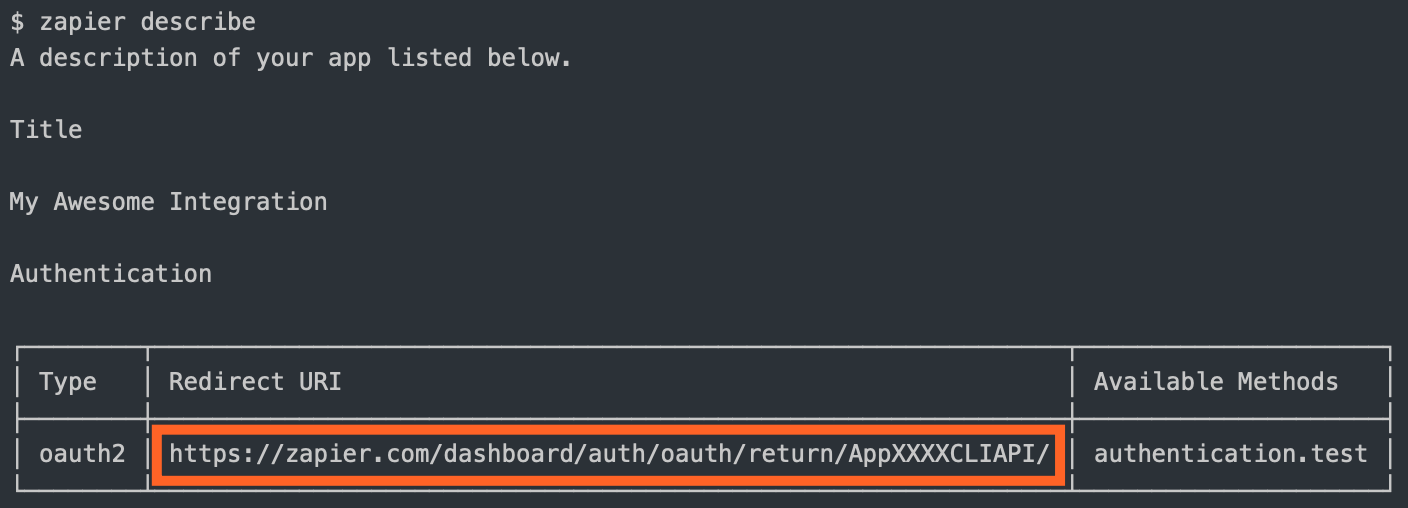
- Zapier makes a backend call to your API to exchange the
code for an access_token. - Zapier stores the
access_token and uses it to make calls on behalf of the user. - (Optionally) Zapier can refresh the token if it expires.
You are required to define:
authorizeUrl: The authorization URLgetAccessToken: The API call to fetch the access token
If the access token has a limited life and you want to refresh the token when it expires, you'll also need to define the API call to perform that refresh (refreshAccessToken). You can choose to set autoRefresh: true, as in the example app, if you want Zapier to automatically make a call to refresh the token after receiving a 401. See Stale Authentication Credentials for more details on handling auth refresh.
You'll also likely want to set your CLIENT_ID and CLIENT_SECRET as environment variables:
$ zapier env:set 1.0.0 CLIENT_ID=1234
$ zapier env:set 1.0.0 CLIENT_SECRET=abcd
$ CLIENT_ID=1234 CLIENT_SECRET=abcd zapier test
Your auth definition would look something like this:
const authentication = {
type: 'oauth2',
test: {
url: 'https://{{bundle.authData.subdomain}}.example.com/api/accounts/me.json',
},
oauth2Config: {
authorizeUrl: {
method: 'GET',
url: 'https://{{bundle.inputData.subdomain}}.example.com/api/oauth2/authorize',
params: {
client_id: '{{process.env.CLIENT_ID}}',
state: '{{bundle.inputData.state}}',
redirect_uri: '{{bundle.inputData.redirect_uri}}',
response_type: 'code',
},
},
getAccessToken: {
method: 'POST',
url: 'https://{{bundle.inputData.subdomain}}.example.com/api/v2/oauth2/token',
body: {
code: '{{bundle.inputData.code}}',
client_id: '{{process.env.CLIENT_ID}}',
client_secret: '{{process.env.CLIENT_SECRET}}',
redirect_uri: '{{bundle.inputData.redirect_uri}}',
grant_type: 'authorization_code',
},
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
},
scope: 'read,write',
},
fields: [
{ key: 'subdomain', type: 'string', required: true, default: 'app' },
],
};
const addBearerHeader = (request, z, bundle) => {
if (bundle.authData && bundle.authData.access_token) {
request.headers.Authorization = `Bearer ${bundle.authData.access_token}`;
}
return request;
};
const App = {
authentication,
beforeRequest: [addBearerHeader],
};
module.exports = App;
For OAuth2, authentication.oauth2Config.authorizeUrl, authentication.oauth2Config.getAccessToken, and authentication.oauth2Config.refreshAccessToken have fields like redirect_uri and state in bundle.inputData. After the code is exchanged for an access token and/or refresh token, those tokens are stored in bundle.authData for the connection.
Also, authentication.oauth2Config.getAccessToken has access to the additional return values in rawRequest and cleanedRequest should you need to extract other values (for example, from the query string).
If you define fields to collect additional details from the user, please note that client_id and client_secret are reserved keys and cannot be used as keys for input form fields.
Note: The OAuth2 state param is a standard security feature that helps ensure that authorization requests are only coming from your servers. Most OAuth clients have support for this and will send back the state query param that the user brings to your app. The Zapier Platform performs this check and this required field cannot be disabled. The state parameter is automatically generated by Zapier in the background, and can be accessed at bundle.inputData.state.
Since Zapier uses the state to verify that GET requests to your redirect URL truly come from your app, it needs to be generated by Zapier so that it can be validated later (once the user confirms that they'd like to grant Zapier permission to access their account in your app).
OAuth2 with PKCE
Added in v14.0.0.
Zapier's OAuth2 implementation also supports PKCE. This implementation is an extension of the OAuth2 authorization_code flow described above.
To use PKCE in your OAuth2 flow, you'll need to set the following variables:
enablePkce: truegetAccessToken.body to include code_verifier: "{{bundle.inputData.code_verifier}}"
The OAuth2 PKCE flow uses the same flow as OAuth2 but adds a few extra parameters:
- Zapier computes a
code_verifier and code_challenge internally and stores the code_verifier in the Zapier bundle. - Zapier sends the user to the authorization URL defined by your app. We automatically include the computed
code_challenge and code_challenge_method in the authorization request. - Once authorized, your website sends the user to the
redirect_uri Zapier provided. - Zapier makes a call to your API to exchange the code but you must include the computed
code_verifier in the request for an access_token. - Zapier stores the
access_token and uses it to make calls on behalf of the user.
Your auth definition would look something like this:
const authentication = {
type: 'oauth2',
test: {
url: 'https://{{bundle.authData.subdomain}}.example.com/api/accounts/me.json',
},
oauth2Config: {
authorizeUrl: {
method: 'GET',
url: 'https://{{bundle.inputData.subdomain}}.example.com/api/oauth2/authorize',
params: {
client_id: '{{process.env.CLIENT_ID}}',
state: '{{bundle.inputData.state}}',
redirect_uri: '{{bundle.inputData.redirect_uri}}',
response_type: 'code',
},
},
getAccessToken: {
method: 'POST',
url: 'https://{{bundle.inputData.subdomain}}.example.com/api/v2/oauth2/token',
body: {
code: '{{bundle.inputData.code}}',
client_id: '{{process.env.CLIENT_ID}}',
client_secret: '{{process.env.CLIENT_SECRET}}',
redirect_uri: '{{bundle.inputData.redirect_uri}}',
grant_type: 'authorization_code',
code_verifier: '{{bundle.inputData.code_verifier}}',
},
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
},
scope: 'read,write',
enablePkce: true,
},
fields: [
{ key: 'subdomain', type: 'string', required: true, default: 'app' },
],
};
const addBearerHeader = (request, z, bundle) => {
if (bundle.authData && bundle.authData.access_token) {
request.headers.Authorization = `Bearer ${bundle.authData.access_token}`;
}
return request;
};
const App = {
authentication,
beforeRequest: [addBearerHeader],
};
module.exports = App;
The computed code_verifier uses this standard: RFC 7636 Code Verifier
The computed code_challenge uses this standard: RFC 7636 Code Challenge
Connection Label
When a user connects to your app via Zapier and a connection is created to hold the related data in bundle.authData, the connection is automatically labeled with the app name. You also have the option of setting a connection label (connectionLabel), which can be extremely helpful to identify information like which user is connected or what instance of your app they are connected to. That way, users don't get confused if they have multiple connections to your app.
When setting a connection label, you can use either a string with variable references (as shown in Basic Auth) or a function (as shown in Digest Auth).
When using a string, you have access to the information in bundle.authData and the information returned from the test request in bundle.inputData, all at the top level. So in Basic auth, if connectionLabel is {{username}}, that refers to the username used for authentication.
When using a function, this "hoisting" of data to the top level is skipped, and you must refer to data items by their fully qualified name, as shown in the line return bundle.inputData.username; in the Digest Auth snippet. return username; would not work in this context.
NOTE: Do not use sensitive authentication data such as passwords or API keys in the connection label. It's visible in plain text on Zapier. The purpose of the label is to identify the connection for the user, so stick with data such as username or instance identifier that is meaningful but not sensitive.
Domain and subdomain validation
When adding a subdomain input field, commonly used in OAuth implementations, additional validation is strongly recommended to prevent a potential security vulnerability. If not taken into account, an attacker could utilize a maliciously constructed subdomain field (like attacker-domain.com/) in order to redirect OAuth connection requests to that attacker-controlled domain (because attacker-domain.com/.your-domain.com resolves to the attacker’s domain instead of the expected one).
This vulnerability presents itself when:
- The authentication method uses pre-configured tokens or secret values (for example, OAuth v2)
- User is able to input a domain or subdomain when authenticating within Zapier
- Integration stores sensitive authentication details (in environment variables, for example) which are used as part of the authentication process
Taking the following steps prevents the potential for an attacker to access your integration’s sensitive authentication information, such as the OAuth client ID or secret.
-
If your integration allows for the user to provide a domain, validate the input against an allow-list of trusted domains.
-
If your integration allows for the user to provide a subdomain, add conditional validation for the subdomain string whenever you include the value in your OAuth HTTP requests. This change will prevent potential exploitation of the subdomain vulnerability.
- If you’re using OAuth-based authentications, update the
getAccessToken and optional refreshAccessToken configuration methods. If the integration uses shorthand HTTP requests, switching to manual HTTP requests will allow you to perform this manual subdomain validation.
Example code for handling subdomain validation:
const refreshAccessToken = async (z, bundle) => {
if (!/^[a-z0-9-]+$/.test(bundle.authData.yourSubdomainField)) {
throw new Error(
"Subdomain can only contain letters, numbers and dashes (-)."
);
}
const response = await z.request({
url: `https://${bundle.authData.yourSubdomainField}.mydomain.com/oauth/token`,
method: "POST",
body: {
client_id: process.env.CLIENT_ID,
client_secret: process.env.CLIENT_SECRET,
grant_type: "refresh_token",
refresh_token: bundle.authData.refresh_token,
redirect_uri: bundle.inputData.redirect_uri,
},
});
return {
access_token: response.data.access_token,
refresh_token: response.data.refresh_token,
};
};
Resources
A resource is a representation (as a JavaScript object) of one of the REST resources of your API. Say you have a /recipes
endpoint for working with recipes; you can define a recipe resource in your app that will tell Zapier how to do create,
read, and search operations on that resource.
const Recipe = {
key: 'recipe',
noun: 'Recipe',
list: {
},
create: {
},
};
The quickest way to create a resource is with the zapier scaffold command:
zapier scaffold resource "Recipe"
This will generate the resource file and add the necessary statements to the index.js file to import it.
Resource Definition
A resource has a few basic properties. The first is the key, which allows Zapier to identify the resource on our backend.
The second is the noun, the user-friendly name of the resource that is presented to users throughout the Zapier UI.
Check out this working example app to see resources in action.
After those, there is a set of optional properties that tell Zapier what methods can be performed on the resource.
The complete list of available methods can be found in the Resource Schema Docs.
For now, let's focus on two:
list - Tells Zapier how to fetch a set of this resource. This becomes a Trigger in the Zapier Editor.create - Tells Zapier how to create a new instance of the resource. This becomes an Action in the Zapier Editor.
Here is a complete example of what the list method might look like
const Recipe = {
key: 'recipe',
list: {
display: {
label: 'New Recipe',
description: 'Triggers when a new recipe is added.',
},
operation: {
perform: {
url: 'https://example.com/recipes',
},
},
},
};
The method is made up of two properties, a display and an operation. The display property (schema) holds the info needed to present the method as an available Trigger in the Zapier Editor. The operation (schema) provides the implementation to make the API call.
Adding a create method looks very similar.
const Recipe = {
key: 'recipe',
list: {
},
create: {
display: {
label: 'Add Recipe',
description: 'Adds a new recipe to our cookbook.',
},
operation: {
perform: {
method: 'POST',
url: 'https://example.com/recipes',
body: {
name: 'Baked Falafel',
style: 'mediterranean',
},
},
},
},
};
Every method you define on a resource Zapier converts to the appropriate Trigger, Create, or Search. Our examples
above would result in an app with a New Recipe Trigger and an Add Recipe Create.
Note the keys for the Trigger, Create, Search, and Search or Create are automatically generated (in case you want to use them in a dynamic dropdown), like: {resourceName}List, {resourceName}Create, {resourceName}Search, and {resourceName}SearchOrCreate; in the examples above, {resourceName} would be recipe.
Triggers, Searches, and Creates are the way an app defines what it is able to do. Triggers read
data into Zapier (i.e. watch for new recipes). Searches locate individual records (find recipe by title). Creates create
new records in your system (add a recipe to the catalog).
The definition for each of these follows the same structure. Here is an example of a trigger:
const App = {
triggers: {
new_recipe: {
key: 'new_recipe',
noun: 'Recipe',
display: {
label: 'New Recipe',
description: 'Triggers when a new recipe is added.',
},
operation: {
perform: {
url: 'https://example.com/recipes',
},
},
},
another_trigger: {
},
},
};
You can find more details on the definition for each by looking at the Trigger Schema,
Search Schema, and Create Schema.
To create a new integration with a premade trigger, search, or create, run zapier init [your app name] and select from the list that appears. You can also check out our working example apps here.
To add a trigger, search, or create to an existing integration, run zapier scaffold [trigger|search|create] [noun] to create the necessary files to your project. For example, zapier scaffold trigger post will create a new trigger called "New Post".
Return Types
Each of the 3 types of function should return a certain data type for use by the platform. There are automated checks to let you know when you're trying to pass the wrong type back. For reference, each expects:
| Method | Return Type | Notes |
|---|
| Trigger | Array | 0 or more objects; passed to the deduper if polling |
| Search | Array | 0 or more objects. Only the first object will be returned, so if len > 1, put the best match first |
| Create | Object | Return values are evaluated by isPlainObject |
When a trigger function returns an empty array, the Zap will not trigger. For REST Hook triggers, this can be used to filter data if the available subscription options are not specific enough for the Zap's needs.
Returning Line Items (Array of Objects)
In some cases, you may want to include multiple items in the data you return for Searches or Creates. To do that, return the set of items as an array of objects under a descriptive key. This may be as part of another object (like items in an invoice) or as multiple top-level items.
For example, a Create Order action returning an order with multiple items might look like this:
order = {
name: 'Zap Zaplar',
total_cost: 25.96,
items: [
{ name: 'Zapier T-Shirt', unit_price: 11.99, quantity: 3, line_amount: 35.97, category: 'shirts' },
{ name: 'Orange Widget', unit_price: 7.99, quantity: 10, line_amount: 79.90, category: 'widgets' },
{ name:'Stuff', unit_price: 2.99, quantity: 7, line_amount: 20.93, category: 'stuff' },
{ name: 'Allbird Shoes', unit_price: 2.99, quantity: 7, line_amount: 20.93, category: 'shoes' },
],
zip: 01002
}
While a Find Users search could return multiple items under an object key within an array, like this:
result = [{
users: [
{ name: 'Zap Zaplar', age: 12, city: 'Columbia', region: 'Missouri' },
{ name: 'Orange Crush', age: 28, city: 'West Ocean City', region: 'Maryland' },
{ name: 'Lego Brick', age: 91, city: 'Billund', region: 'Denmark' },
],
}];
A standard search would return just the inner array of users, and only the first user would be provided as a final result. Returning line items instead means that the "first result" return is the object containing all the user details within it.
Using the standard approach is recommended, because not all Zapier integrations support line items directly, so users may need to take additional actions to reformat this data for use in their Zaps. More detail on that at Use line items in Zaps. However, there are use cases where returning multiple results is helpful enough to outweigh that additional effort.
Fallback Sample
In cases where Zapier needs to show an example record to the user, but we are unable to get a live example from the API, Zapier will fallback to this hard-coded sample. This should reflect the data structure of the Trigger's perform method, and have dummy values that we can show to any user.
,sample: {
dummydata_field1: 'This will be compared against your perform method output'
style: 'mediterranean'
}
Input Fields
On each trigger, search, or create in the operation directive, you can provide fields as an array of objects under inputFields. Input Fields are what your users see in Zapier when setting up your app's triggers and actions. For example, you might have a "Create Contact" action with fields like "First name", "Last name", "Email", etc. These fields will be able to accept input from the user, or from previous steps in a Zap. For example:
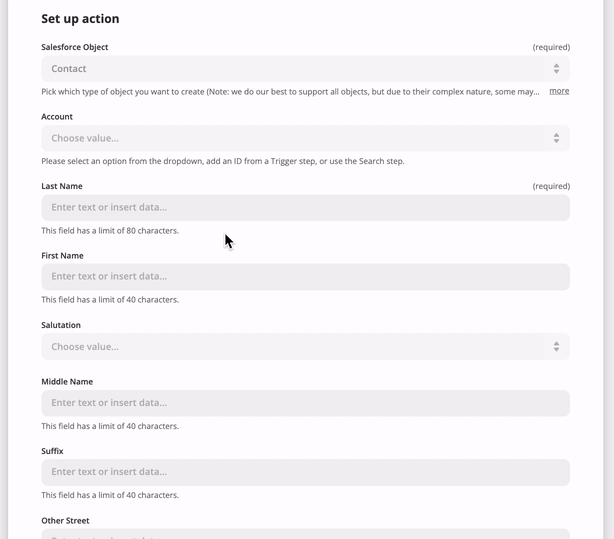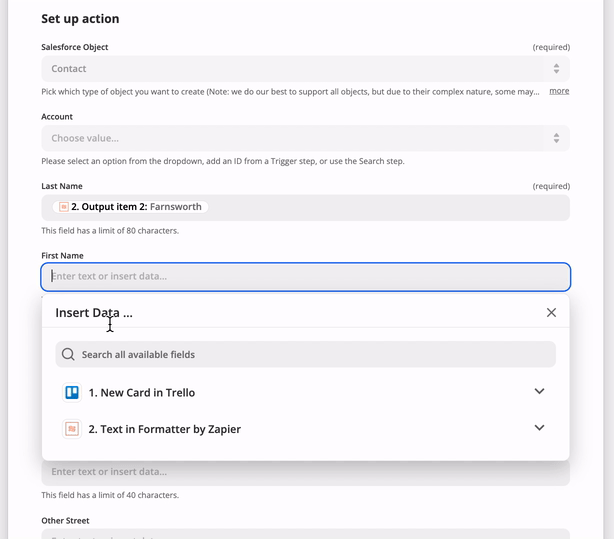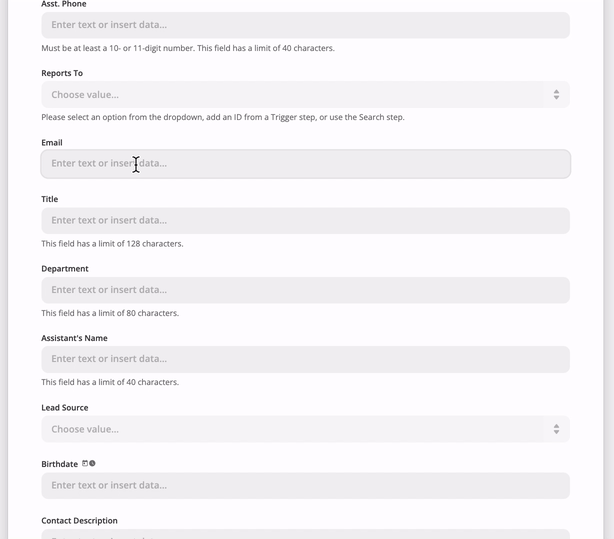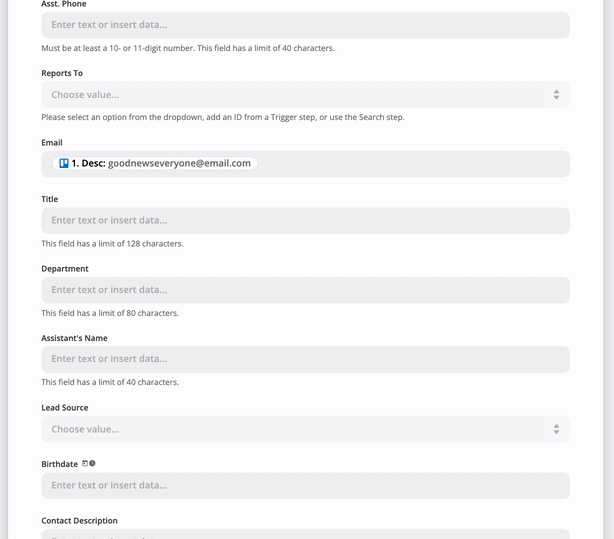
You can find more details about setting action fields from a user perspective in our help documentation.
Those fields have various options you can provide. Here is a brief example:
const App = {
creates: {
create_recipe: {
operation: {
inputFields: [
{
key: 'title',
required: true,
label: 'Title of Recipe',
helpText: 'Name your recipe!',
},
{
key: 'style',
required: true,
choices: { mexican: 'Mexican', italian: 'Italian' },
},
],
perform: () => {},
},
},
},
};
Notably, fields come in different types, which may look and act differently in the Zap editor. The default field display is a single-line input field.
| Type | Behavior |
|---|
string | Accepts text input. |
text | Displays large, <textarea>-style entry box, accepts text input. |
code | Displays large, <textarea>-style box with a fixed-width font, accepts text input. |
integer | Accepts integer number values. |
number | Accepts any numeric value, including decimal numbers. |
boolean | Displays dropdown menu offering true and false options. Passes along true or false. |
datetime | Accepts both precise and human-readable date-time values. Passes along an ISO-formatted time string. |
file | Accepts a file object or a string. If a URL is provided in the string, Zapier will automatically make a GET for that file. Otherwise, a text file will be generated. |
password | Displays entered characters as hidden, accepts text input. Does not accept input from previous steps. |
copy | Does not allow users to enter data. Shows the value of the Markdown-formatted Help Text for the field as a rich text note in the Zap editor. Good for important notices to users. |
You can find more details on the different field schema options at our Field Schema.
Custom/Dynamic Fields
In some cases, you may need to provide dynamically-generated fields - especially for custom ones. This is common functionality for CRMs, form software, databases, and other highly-customizable platforms. Instead of an explicit field definition, you can provide a function we'll evaluate to return a list of fields - merging the dynamic with the static fields.
You should see bundle.inputData partially filled in as users provide data - even in field retrieval. This allows you to build hierarchical relationships into fields (e.g. only show issues from the previously selected project).
A function that returns a list of dynamic fields cannot include additional functions in that list to call for dynamic fields.
const recipeFields = async (z, bundle) => {
const response = await z.request('https://example.com/api/v2/fields.json');
return response.data;
};
const App = {
creates: {
create_recipe: {
operation: {
inputFields: [
{
key: 'title',
required: true,
label: 'Title of Recipe',
helpText: 'Name your recipe!',
},
{
key: 'style',
required: true,
choices: { mexican: 'Mexican', italian: 'Italian' },
},
recipeFields,
],
perform: () => {},
},
},
},
};
Additionally, if there is a field that affects the generation of dynamic fields, you can set the property altersDynamicFields: true. This informs the Zapier UI whenever the value of that field changes, the input fields need to be recomputed. For example, imagine the selection on a static dropdown called "Dessert Type" determining whether the function generating dynamic fields includes the field "With Sprinkles?" or not. If the value in one input field affects others, this is an important property to set.
module.exports = {
key: 'dessert',
noun: 'Dessert',
display: {
label: 'Order Dessert',
description: 'Orders a dessert.',
},
operation: {
inputFields: [
{
key: 'type',
required: true,
choices: { 1: 'cake', 2: 'ice cream', 3: 'cookie' },
altersDynamicFields: true,
},
function (z, bundle) {
if (bundle.inputData.type === '2') {
return [{ key: 'with_sprinkles', type: 'boolean' }];
}
return [];
},
],
perform: function (z, bundle) {
},
},
};
Only dropdowns support altersDynamicFields.
When using dynamic fields, the fields will be retrieved in three different contexts:
- Whenever the value of a field with
altersDynamicFields is changed, as described above. - Whenever the Zap Editor opens the "Set up" section for the trigger or action.
- Whenever the "Refresh fields" button at the bottom of the Editor's "Set up" section is clicked.
Be sure to set up your code accordingly - for example, don't rely on any input fields already having a value, since they won't have one the first time the "Set up" section loads.
Dynamic Dropdowns
Sometimes, API endpoints require clients to specify a parent object in order to create or access the child resources. For instance, specifying a spreadsheet id in order to retrieve its worksheets. Since people don't speak in auto-incremented ID's, it is necessary that Zapier offer a simple way to select that parent using human readable handles.
Our solution is to present users a dropdown that is populated by making a live API call to fetch a list of parent objects. We call these special dropdowns "dynamic dropdowns."
To define one you include the dynamic property on the inputFields object. The value for the property is a dot-separated string concatenation.
issue: {
key: 'issue',
create: {
operation: {
inputFields: [
{
key: 'project_id',
required: true,
label: 'This is a dynamic dropdown',
dynamic: 'project.id.name'
},
{
key: 'title',
required: true,
label: 'Title',
helpText: 'What is the name of the issue?'
}
]
}
}
}
The dot-separated string concatenation follows this pattern:
- The key of the trigger you want to use to power the dropdown. required
- The value to be made available in bundle.inputData. required
- The human friendly value to be shown on the left of the dropdown in bold. optional
In the above code example the dynamic property makes reference to a trigger with a key of project. Assuming the project trigger returns an array of objects and each object contains an id and name key, i.e.
[
{ id: '1', name: 'First Option', dateCreated: '01/01/2000' },
{ id: '2', name: 'Second Option', dateCreated: '01/01/2000' },
{ id: '3', name: 'Third Option', dateCreated: '01/01/2000' },
{ id: '4', name: 'Fourth Option', dateCreated: '01/01/2000' },
];
The dynamic dropdown would look something like this.
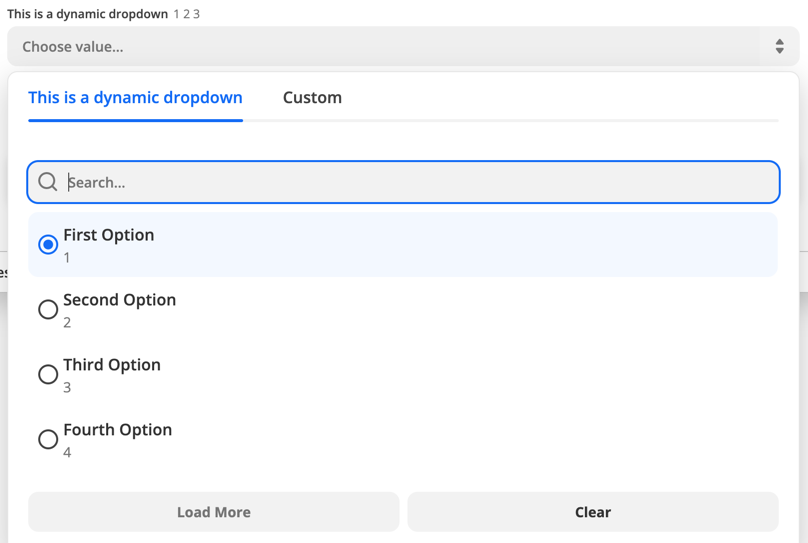
In the first code example the dynamic dropdown is powered by a trigger. You can also use a resource to power a dynamic dropdown. To do this combine the resource key and the resource method using camel case.
const App = {
resources: {
project: {
key: 'project',
list: {
operation: {
perform: () => {
return [{ id: 123, name: 'Project 1' }];
},
},
},
},
issue: {
key: 'issue',
create: {
operation: {
inputFields: [
{
key: 'project_id',
required: true,
label: 'Project',
dynamic: 'projectList.id.name',
},
{
key: 'title',
required: true,
label: 'Title',
helpText: 'What is the name of the issue?',
},
],
},
},
},
},
};
In some cases you will need to power a dynamic dropdown but do not want to make the Trigger available to the end user. Here it is best practice to create the trigger and set hidden: true on it's display object.
const App = {
triggers: {
new_project: {
key: 'project',
noun: 'Project',
display: {
label: 'New Project',
description: 'Triggers when a new project is added.',
hidden: true,
},
operation: {
perform: projectListRequest,
},
},
another_trigger: {
},
},
};
You can have multiple dynamic dropdowns in a single Trigger or Action. And a dynamic dropdown can depend on the value chosen in another dynamic dropdown when making it's API call. Such as a Spreadsheet and Worksheet dynamic dropdown in a trigger or action. This means you must make sure that the key of the first dynamic dropdown is the same as referenced in the trigger powering the second.
Let's say you have a Worksheet trigger with a perform method similar to this.
perform: async (z, bundle) => {
const response = await z.request('https://example.com/api/v2/projects.json', {
params: {
spreadsheet_id: bundle.inputData.spreadsheet_id,
},
});
return response.data;
};
And your New Records trigger has a Spreadsheet and a Worksheet dynamic dropdown. The Spreadsheet dynamic dropdown must have a key of spreadsheet_id. When the user selects a spreadsheet via the dynamic dropdown the value chosen is made available in bundle.inputData. It will then be passed to the Worksheet trigger when the user clicks on the Worksheet dynamic dropdown.
const App = {
triggers: {
issue: {
key: 'new_records',
operation: {
inputFields: [
{
key: 'spreadsheet_id',
required: true,
label: 'Spreadsheet',
dynamic: 'spreadsheet.id.name',
},
{
key: 'worksheet_id',
required: true,
label: 'Worksheet',
dynamic: 'worksheet.id.name',
},
],
},
},
},
};
The Google Sheets integration is an example of this pattern.
If you want your trigger to perform specific scripting for a dynamic dropdown you will need to make use of bundle.meta.isFillingDynamicDropdown. This can be useful if need to make use of pagination in the dynamic dropdown to load more options.
const App = {
resources: {
project: {
key: 'project',
list: {
operation: {
canPaginate: true,
perform: () => {
if (bundle.meta.isFillingDynamicDropdown) {
} else {
return [{ id: 123, name: 'Project 1' }];
}
},
},
},
},
issue: {
key: 'issue',
create: {
operation: {
inputFields: [
{
key: 'project_id',
required: true,
label: 'Project',
dynamic: 'projectList.id.name',
},
{
key: 'title',
required: true,
label: 'Title',
helpText: 'What is the name of the issue?',
},
],
},
},
},
},
};
Search-Powered Fields
For fields that take id of another object to create a relationship between the two (EG: a project id for a ticket), you can specify the search property on the field to indicate that Zapier needs to prompt the user to setup a Search step to populate the value for this field. Similar to dynamic dropdowns, the value for this property is a dot-separated concatenation of a search's key and the field to use for the value.
const App = {
resources: {
project: {
key: 'project',
search: {
operation: {
perform: () => {
return [{ id: 123, name: 'Project 1' }];
},
},
},
},
issue: {
key: 'issue',
create: {
operation: {
inputFields: [
{
key: 'project_id',
required: true,
label: 'Project',
dynamic: 'projectList.id.name',
search: 'projectSearch.id',
},
{
key: 'title',
required: true,
label: 'Title',
helpText: 'What is the name of the issue?',
},
],
},
},
},
},
};
NOTE: This has to be combined with the dynamic property to give the user a guided experience when setting up a Zap.
If you don't define a trigger for the dynamic property, the search connector won't show.
Computed Fields
In OAuth and Session Auth, Zapier automatically stores every value from an integration’s auth API response i.e. that’s getAccessToken and refreshAccessToken for OAuth and getSessionKey for session auth.
You can return additional fields in these responses, on top of the expected access_token or refresh_token for OAuth and sessionKey for Session auth. They will be saved in bundle.authData. You can reference these fields in any subsequent API call as needed.
Note: Only OAuth and Session Auth support computed fields.
If you want Zapier to validate that these additional fields exist, you need to use Computed Fields. If you define computed fields in your integration, Zapier will check to make sure those fields exist when it runs the authentication test API call.
Computed fields work like any other field, though with computed: true property, and required: false as user can not enter computed fields themselves. Reference computed fields in API calls as {{bundle.authData.field}}, replacing field with that field's name from your test API call response.
You can see examples of computed fields in the OAuth2 or Session Auth example sections.
Nested & Children (Line Item) Fields
When your action needs to accept an array of items, you can include an input field with the children attribute. The children attribute accepts a list of fields that can be input for each item in this array.
const App = {
operation: {
inputFields: [
{
key: 'lineItems',
children: [
{
key: 'lineItemId',
type: 'integer',
label: 'Line Item ID',
required: true,
},
{
key: 'name',
type: 'string',
label: 'Name',
required: true,
},
{
key: 'description',
type: 'string',
label: 'Description',
},
],
},
],
},
};
Output Fields
On each trigger, search, or create in the operation directive - you can provide an array of objects as fields under the outputFields. Output Fields are what users see when they select a field provided by your trigger, search or create to map it to another.
Output Fields are optional, but can be used to:
- Define friendly labels for the returned fields. By default, we will humanize for example
my_key as My Key. - Make sure that custom fields that may not be found in every live sample and - since they're custom to the connected account - cannot be defined in the static sample, can still be mapped.
- (Added in v15.6.0) Define what field(s) can be used to uniquely identify and deduplicate items returned by a polling trigger call.
The schema for outputFields is shared with inputFields but only these properties are relevant:
key - includes the field when not present in the live sample. When no label property is provided, key will be humanized and displayed as the field name.label - defines the field name displayed to users.type - defines the type for static sample data. A validation warning will be displayed if the static sample does not match the specified type.required - defines whether the field is required in static sample data. A validation warning will be displayed if the value is true and the static sample does not contain the field.primary - defines whether the field is part of the primary key for polling trigger deduplication.
Custom/Dynamic Output Fields are defined in the same way as Custom/Dynamic Input Fields.
Nested & Children (Line Item) Fields
To define an Output Field for a nested field use {{parent}}__{{key}}. For children (line item) fields use {{parent}}[]{{key}}.
const recipeOutputFields = async (z, bundle) => {
const response = await z.request('https://example.com/api/v2/fields.json');
return response.data;
};
const App = {
triggers: {
new_recipe: {
operation: {
perform: () => {},
sample: {
id: 1,
title: 'Pancake',
author: {
id: 1,
name: 'Amy',
},
ingredients: [
{
name: 'Egg',
amount: 1,
},
{
name: 'Milk',
amount: 60,
unit: 'g',
},
{
name: 'Flour',
amount: 30,
unit: 'g',
},
],
},
outputFields: [
{
key: 'id',
label: 'Recipe ID',
type: 'integer',
},
{
key: 'title',
label: 'Recipe Title',
type: 'string',
},
{
key: 'author__id',
label: 'Author User ID',
type: 'integer',
},
{
key: 'author__name',
label: 'Author Name',
type: 'string',
},
{
key: 'ingredients[]name',
label: 'Ingredient Name',
type: 'string',
},
{
key: 'ingredients[]amount',
label: 'Ingredient Amount',
type: 'number',
},
{
key: 'ingredients[]unit',
label: 'Ingredient Unit',
type: 'string',
},
recipeOutputFields,
],
},
},
},
};
Buffered Create Actions
Added in v15.15.0. This feature is currently internal-only.
A Buffered Create allows you to create objects in bulk with a single or fewer API request(s). This is useful when you want to reduce the number of requests made to your server. When enabled, Zapier holds the data until the buffer reaches a size limit or a certain time has passed, then sends the buffered data using the performBuffer function you define.
To implement a Buffered Create, you define a buffer configuration object and a performBuffer function in the operation object. In the buffer config object, you specify how you want to group the buffered data using the groupedBy setting and the maximum number of items to buffer using the limit setting.
The performBuffer function should replace the perform function. Note that perform cannot be defined along with performBuffer. Check out the create action operation schema for details.
Similar to the general perform function accepting two arguments, z and bundle objects, the performBuffer function accepts z and bufferedBundle objects. They share the same z object, but the bufferedBundle object is different from the bundle object. The bufferedBundle object has an idempotency ID set at bufferedBundle.buffer[].meta.id for each object in the buffer. performBuffer would have to return the idempotency IDs to tell Zapier which objects were successfully written. Find the details about the bufferedBundle object here.
Here is an example of a Buffered Create action:
const performBuffer = async (z, bufferedBundle) => {
const rows = bufferedBundle.buffer.map(({ inputData }) => {
return { title: inputData.title, year: inputData.year };
});
const response = await z.request({
method: 'POST',
url: 'https://api.example.com/add_rows',
body: {
spreadsheet: bufferedBundle.groupedBy.spreadsheet,
worksheet: bufferedBundle.groupedBy.worksheet,
rows,
},
});
const result = {};
bufferedBundle.buffer.forEach(({ inputData, meta }, index) => {
let error = '';
let outputData = {};
if (response.data.rows.length > index) {
if (response.data.rows[index].error) {
error = response.data.rows[index].error;
} else {
outputData = response.data.rows[index];
}
}
result[meta.id] = { outputData, error };
});
return result;
};
module.exports = {
key: 'add_rows',
noun: 'Rows',
display: {
label: 'Add Rows',
description: 'Add rows to a worksheet.',
},
operation: {
buffer: {
groupedBy: ['spreadsheet', 'worksheet'],
limit: 3,
},
performBuffer,
inputFields: [
{
key: 'spreadsheet',
type: 'string',
required: true,
},
{
key: 'worksheet',
type: 'string',
required: true,
},
{
key: 'title',
type: 'string',
},
{
key: 'year',
type: 'string',
},
],
outputFields: [{ key: 'id', type: 'string' }],
sample: { id: '12345' },
},
};
Z Object
We provide several methods off of the z object, which is provided as the first argument to all function calls in your app.
The z object is passed into your functions as the first argument - IE: perform: (z) => {}.
z.request([url], options)
z.request([url], options) is a promise based HTTP client with some Zapier-specific goodies. See Making HTTP Requests. z.request() will percent-encode non-ascii characters and these reserved characters: :$/?#[]@$&+,;=^@`\. Use skipEncodingChars to modify this behaviour.
z.console
z.console.log(message) is a logging console, similar to Node.js console but logs remotely, as well as to stdout in tests. See Log Statements
z.dehydrate(func, inputData)
z.dehydrate(func, inputData) is used to lazily evaluate a function, perfect to avoid API calls during polling or for reuse. See Dehydration.
z.dehydrateFile(func, inputData)
z.dehydrateFile is used to lazily download a file, perfect to avoid API calls during polling or for reuse. See File Dehydration.
z.stashFile(bufferStringStream, [knownLength], [filename], [contentType])
z.stashFile(bufferStringStream, [knownLength], [filename], [contentType]) is a promise based file stasher that returns a URL file pointer. See Stashing Files.
z.JSON
z.JSON is similar to the JSON built-in like z.JSON.parse('...'), but catches errors and produces nicer tracebacks.
z.hash()
z.hash() is a crypto tool for doing things like z.hash('sha256', 'my password')
z.errors
z.errors is a collection error classes that you can throw in your code, like throw new z.errors.HaltedError('...').
The available errors are:
Error (added in v9.3.0) - Stops the current operation, allowing for (auto) replay. Read more on General ErrorsHaltedError - Stops current operation, but will never turn off Zap. Read more on Halting ExecutionExpiredAuthError - Stops the current operation and emails user to manually reconnect. Read more on Stale Authentication CredentialsRefreshAuthError - (OAuth2 or Session Auth) Tells Zapier to refresh credentials and retry operation. Read more on Stale Authentication CredentialsThrottledError (new in v11.2.0) - Tells Zapier to retry the current operation after a delay specified in seconds. Read more on Handling Throttled Requests
For more details on error handling in general, see here.
z.cursor
The z.cursor object exposes two methods:
z.cursor.get(): Promise<string|null>z.cursor.set(string): Promise<null>
Any data you set will be available to that Zap for about an hour (or until it's overwritten). For more information, see: paging.
z.generateCallbackUrl()
The z.generateCallbackUrl() will return a callback URL your app can POST to later for handling long running tasks (like transcription or encoding jobs). In the meantime, the Zap and Task will wait for your response and the user will see the Task marked as waiting.
For example, in your perform you might do:
const perform = async (z, bundle) => {
const callbackUrl = z.generateCallbackUrl();
await z.request({
url: 'https://example.com/api/slow-job',
method: 'POST',
body: {
url: callbackUrl,
},
});
return {"hello": "world"};
};
And in your own /api/slow-job view (or more likely, an async job) you'd make this request to Zapier when the long-running job completes to populate bundle.cleanedRequest:
POST /hooks/callback/123/abcdef01-2345-6789-abcd-ef0123456789/abcdef0123456789abcdef0123456789abcdef01/ HTTP/1.1
Host: zapier.com
Content-Type: application/json
{"foo":"bar"}
We recommend using bundle.meta.isLoadingSample to determine if the execution is happening in the foreground (IE: during Zap setup) as using z.generateCallbackUrl() can be inappropriate given the disconnect. Instead, wait for the long running request without generating a callback, or if you must, return stubbed data.
By default the payload POSTed to the callback URL will augment the data returned from the initial perform to compose the final value.
If you need to customize what the final value should be you can define a performResume method that receives three bundle properties:
bundle.outputData is {"hello": "world"}, the data returned from the initial performbundle.cleanedRequest is {"foo": "bar"}, the payload from the callback URLbundle.rawRequest is the full request object corresponding to bundle.cleanedRequest
const performResume = async (z, bundle) => {
return { ...bundle.outputData, ...bundle.cleanedRequest };
};
The app will have a maximum of 30 days to POST to the callback URL. If a user deletes or modifies the Zap or Task in the meantime, we will not resume the task.
performResume will only run when the Zap runs live, and cannot be tested in the Zap Editor when configuring the Zap. It is possible to use bundle.meta.isLoadingSample to load a fixed sample to allow users to test a step that includes performResume.
Bundle Object
This object holds the user's auth details and the data for the API requests.
The bundle object is passed into your functions as the second argument - IE: perform: (z, bundle) => {}.
bundle.authData
bundle.authData is user-provided authentication data, like api_key or access_token. Read more on authentication.
bundle.inputData
bundle.inputData is user-provided data for this particular run of the trigger/search/create, as defined by the inputFields. For example:
{
createdBy: 'his name is Bobby Flay',
style: 'he cooks mediterranean',
scheduledAt: "2021-09-09T09:00:00-07:00"
}
bundle.inputDataRaw
bundle.inputDataRaw is like bundle.inputData, but before processing such as interpreting friendly datetimes and rendering {{curlies}}:
{
createdBy: 'his name is {{123__chef_name}}',
style: 'he cooks {{456__style}}',
scheduledAt: "today"
}
"curlies" represent data mapped in from previous steps. They take the form {{NODE_ID__key_name}}.
You'll usually want to use bundle.inputData instead.
bundle.meta
bundle.meta contains extra information useful for doing advanced behaviors depending on what the user is doing. It has the following options:
| key | default | description |
|---|
isLoadingSample | false | If true, this run was initiated manually via the Zap Editor |
isFillingDynamicDropdown | false | If true, this poll is being used to populate a dynamic dropdown. You only need to return the fields you specified (such as id and name), though returning everything is fine too |
isPopulatingDedupe | false | If true, the results of this poll will be used to initialize the deduplication list rather than trigger a zap. You should grab as many items as possible. See also: deduplication |
limit | -1 | The number of items you should fetch. -1 indicates there's no limit. Build this into your calls insofar as you are able |
page | 0 | Used in paging to uniquely identify which page of results should be returned |
isTestingAuth | false | (legacy property) If true, the poll was triggered by a user testing their account (via clicking "test" or during setup). We use this data to populate the auth label, but it's mostly used to verify we made a successful authenticated request |
withSearch | undefined | When a create is called as part of a search-or-create step, withSearch will be the key of the search. |
Before v8.0.0, the information in bundle.meta was different. See the old docs for the previous values and the wiki for a mapping of old values to new.
Here's an example of a polling trigger that is also used to power a dynamic dropdown:
const perform = async (z, bundle) => {
const params = { per_page: 100 };
if (bundle.meta.isFillingDynamicDropdown) {
params.per_page = 30;
params.offset = params.per_page * bundle.meta.page;
}
const response = await z.request({
url: `${API_BASE_URL}/teams`,
params,
});
return response.json;
};
bundle.rawRequest
bundle.rawRequest is only available in the perform for webhooks, getAccessToken for OAuth authentication methods, and performResume in a callback action.
bundle.rawRequest holds raw information about the HTTP request that triggered the perform method or that represents the user's browser request that triggered the getAccessToken call:
{
method: 'POST',
querystring: 'foo=bar&baz=qux',
headers: {
'Content-Type': 'application/json'
},
content: '{"hello": "world"}'
}
In bundle.rawRequest, headers other than Content-Length and Content-Type will be prefixed with Http-, and all headers will be named in Camel-Case. For example, the header X-Time-GMT would become Http-X-Time-Gmt.
bundle.cleanedRequest
bundle.cleanedRequest is only available in the perform for webhooks, getAccessToken for OAuth authentication methods, and performResume in a callback action.
bundle.cleanedRequest will return a formatted and parsed version of the request. Some or all of the following will be available:
{
method: 'POST',
querystring: {
foo: 'bar',
baz: 'qux'
},
headers: {
'Content-Type': 'application/json'
},
content: {
hello: 'world'
}
}
bundle.outputData
bundle.outputData is only available in the performResume in a callback action.
bundle.outputData will return a whatever data you originally returned in the perform, allowing you to mix that with bundle.rawRequest or bundle.cleanedRequest.
bundle.targetUrl
bundle.targetUrl is only available in the performSubscribe and performUnsubscribe methods for webhooks.
This the URL to which you should send hook data. It'll look something like https://hooks.zapier.com/1234/abcd. We provide it so you can make a POST request to your server. Your server should store this URL and use is as a destination when there's new data to report.
For example:
const subscribeHook = async (z, bundle) => {
const options = {
url: 'https://57b20fb546b57d1100a3c405.mockapi.io/api/hooks',
method: 'POST',
body: {
url: bundle.targetUrl,
},
};
const response = await z.request(options);
return response.data;
};
module.exports = {
performSubscribe: subscribeHook,
};
Read more in the REST hook example.
bundle.subscribeData
bundle.subscribeData is available in the perform and performUnsubscribe method for webhooks.
This is an object that contains the data you returned from the performSubscribe function. It should contain whatever information you need send a DELETE request to your server to stop sending webhooks to Zapier.
Read more in the REST hook example.
BufferedBundle Object
Added in v15.15.0.
This object holds a user's auth details (bufferedBundle.authData) and the buffered data (bufferedBundle.buffer) for the API requests. It is used only with a create action's performBuffer function.
The bufferedBundle object is passed into the performBuffer function as the second argument - IE: performBuffer: async (z, bufferedBundle) => {}.
bufferedBundle.authData
It is a user-provided authentication data, like api_key or access_token. Read more on authentication.
bufferedBundle.groupedBy
It is a user-provided data for a set of selected inputFields to group the multiple runs of a create action by.
bufferedBundle.buffer
It is an array of objects of user-provided data and some meta data to allow multiple runs of a create action be processed in a single API request.
bufferedBundle.buffer[].inputData
It is a user-provided data for a particular run of a create action in the buffer, as defined by the inputFields.
bufferedBundle.buffer[].meta
It contains an idempotency id provided to the create action to identify each run's data in the buffered data.
Environment
Apps can define environment variables that are available when the app's code executes. They work just like environment
variables defined on the command line. They are useful when you have data like an OAuth client ID and secret that you
don't want to commit to source control. Environment variables can also be used as a quick way to toggle between
a staging and production environment during app development.
It is important to note that variables are defined on a per-version basis! When you push a new version, the
existing variables from the previous version are copied, so you don't have to manually add them. However, edits
made to one version's environment will not affect the other versions.
Defining Environment Variables
To define an environment variable, use the env command:
zapier env:set 1.0.0 MY_SECRET_VALUE=1234
You will likely also want to set the value locally for testing.
export MY_SECRET_VALUE=1234
Alternatively, we provide some extra tooling to work with an .env (or .environment, see below note) that looks like this:
MY_SECRET_VALUE=1234
.env is the new recommended name for the environment file since v5.1.0. The old name .environment is deprecated but will continue to work for backward compatibility.
And then in your test/basic.js file:
const zapier = require('zapier-platform-core');
should('some tests', () => {
zapier.tools.env.inject();
console.log(process.env.MY_SECRET_VALUE);
});
This is a popular way to provide process.env.ACCESS_TOKEN || bundle.authData.access_token for convenient testing.
NOTE Variables defined via zapier env:set will always be uppercased. For example, you would access the variable defined by zapier env:set 1.0.0 foo_bar=1234 with process.env.FOO_BAR.
Accessing Environment Variables
To view existing environment variables, use the env command.
zapier env:get 1.0.0
Within your app, you can access the environment via the standard process.env - any values set via local export or zapier env:set will be there.
For example, you can access the process.env in your perform functions and in templates:
const listExample = async (z, bundle) => {
const httpOptions = {
headers: {
'my-header': process.env.MY_SECRET_VALUE,
},
};
const response = await z.request(
'https://example.com/api/v2/recipes.json',
httpOptions
);
return response.data;
};
const App = {
triggers: {
example: {
noun: '{{process.env.MY_NOUN}}',
operation: {
perform: listExample,
},
},
},
};
Note! Be sure to lazily access your environment variables - see When to use placeholders or curlies?.
Adding Throttle Configuration
Added in v15.4.0.
When a throttle configuration is set for an action, Zapier uses it to apply throttling when the limit for the timeframe window is exceeded. It can be set at the root level and/or on an action. When set at the root level, it is the default throttle configuration used on each action of the integration. And when set in an action's operation object, the root-level default is overwritten for that action only. Note that the throttle limit is not shared across actions unless for those with the same key, window, limit, and scope when "action" is not in the scope.
To throttle an action, you need to set a throttle object with the following variables:
window [integer]: The timeframe, in seconds, within which the system tracks the number of invocations for an action. The number of invocations begins at zero at the start of each window.limit [integer]: The maximum number of invocations for an action, allowed within the timeframe window.key [string] (added in v15.6.0): The key to throttle with in combination with the scope. User data provided for the input fields can be used in the key with the use of the curly braces referencing. For example, to access the user data provided for the input field "test_field", use {{bundle.inputData.test_field}}. Note that a required input field should be referenced to get user data always.retry [boolean] (added in v15.8.0): The effect of throttling on the tasks of the action. true means throttled tasks are automatically retried after some delay, while false means tasks are held without retry. It defaults to true. NOTE that it has no effect on polling triggers and should not be set.filter [string] (added in v15.8.0): EXPERIMENTAL: Account-based attribute to override the throttle by. You can set to one of the following: "free", "trial", "paid". Therefore, the throttle scope would be automatically set to "account" and ONLY the accounts based on the specified filter will have their requests throttled based on the throttle overrides while the rest are throttled based on the original configuration.scope [array]: The granularity to throttle by. You can set the scope to one or more of the following options;
- 'user' - Throttles based on user ids.
- 'auth' - Throttles based on auth ids.
- 'account' - Throttles based on account ids for all users under a single account.
- 'action' - Throttles the action it is set on separately from other actions.
overrides [array[object]] (added in v15.6.0): EXPERIMENTAL: Overrides the original throttle configuration based on a Zapier account attribute;
window [integer]: Same description as above.limit [integer]: Same description as above.filter [string]: Account-based attribute to override the throttle by. You can set to one of the following: "free", "trial", "paid". Therefore, the throttle scope would be automatically set to "account" and ONLY the accounts based on the specified filter will have their requests throttled based on the throttle overrides while the rest are throttled based on the original configuration.retry [boolean] (added in v15.6.1): The effect of throttling on the tasks of the action. true means throttled tasks are automatically retried after some delay, while false means tasks are held without retry. It defaults to true. NOTE that it has no effect on polling triggers and should not be set.
Both window and limit are required and others are optional. By default, throttling is scoped to the action and account.
Here is a typical usage of the throttle configuration:
const App = {
version: require('./package.json').version,
platformVersion: require('zapier-platform-core').version,
throttle: {
window: 600,
limit: 50,
scope: ['account'],
},
creates: {
upload_video: {
noun: 'Video',
display: {
label: 'Upload Video',
description: 'Upload a video.',
},
operation: {
perform: () => {},
inputFields: [{ key: 'name', required: true, type: 'string' }],
throttle: {
window: 600,
limit: 5,
key: 'test-key-{{bundle.inputData.name}}',
retry: false,
scope: ['account'],
overrides: [
{
window: 600,
limit: 10,
filter: 'free',
retry: false,
},
{
window: 600,
limit: 100,
filter: 'trial',
retry: false,
},
{
window: 0,
limit: 0,
filter: 'paid',
retry: true,
},
],
},
},
},
},
};
module.exports = App;
Making HTTP Requests
There are two ways to make HTTP requests:
- Shorthand HTTP Requests - Easy to use, but limits what you can control. Best for simple requests.
- Manual HTTP Requests - Gives you full control over the request and response.
Use these helper constructs to reduce boilerplate:
requestTemplate - an object literal of HTTP request options that will be merged with every request.beforeRequest - middleware that mutates every request before it is sent.afterResponse - middleware that mutates every response before it is completed.
Note: you can install any HTTP client you like - but this is greatly discouraged as you lose automatic HTTP logging and middleware.
Shorthand HTTP Requests
For simple HTTP requests that do not require special pre- or post-processing, you can specify the HTTP request options as an object literal in your app definition.
This features:
- Lazy
{{curly}} replacement. - JSON and form body de-serialization.
- Automatic non-2xx error raising.
const triggerShorthandRequest = {
url: 'https://{{bundle.authData.subdomain}}.example.com/v2/api/recipes.json',
method: 'GET',
params: {
sort_by: 'id',
sort_order: 'DESC',
},
};
const App = {
triggers: {
example: {
operation: {
perform: triggerShorthandRequest,
},
},
},
};
In the URL above, {{bundle.authData.subdomain}} is automatically replaced with the live value from the bundle. If the call returns a non 2xx return code, an error is automatically raised. The response body is automatically parsed as JSON or form-encoded and returned.
An error will be raised if the response cannot be parsed as JSON or form-encoded. To use shorthand requests with other response types, add middleware that sets response.data to the parsed response.
Manual HTTP Requests
Use this when you need full control over the request/response. For example:
- To do processing (usually involving
bundle.inputData) before a request is made - To do processing of an API's response before you return data to Zapier
- To process an unusual response type, such as XML
To make a manual request, pass your request options to z.request() then use the resulting response object to return the data you want:
const listRecipes = async (z, bundle) => {
const httpRequestOptions = {
url: 'https://{{bundle.authData.subdomain}}.example.com/v2/api/recipes.json',
method: 'GET',
params: {
cuisine: bundle.inputData.cuisine,
},
};
const response = await z.request(httpRequestOptions);
const recipes = response.data;
return recipes;
};
const App = {
triggers: {
example: {
operation: {
perform: listRecipes,
},
},
},
};
Manual requests perform lazy {{curly}} replacement. In the URL above, {{bundle.authData.subdomain}} is automatically replaced with the live value from the bundle.
POST and PUT Requests
To POST or PUT data to your API you can do this:
const App = {
triggers: {
example: {
operation: {
perform: async (z, bundle) => {
const recipe = {
name: 'Baked Falafel',
style: 'mediterranean',
directions: 'Get some dough....',
};
const options = {
method: 'POST',
url: 'https://example.com/api/v2/recipes.json',
body: JSON.stringify(recipe),
};
const response = await z.request(options);
if (response.status !== 201) {
throw new z.errors.Error(
`Unexpected status code ${response.status}`,
'CreateRecipeError',
response.status
);
}
return response.data;
},
},
},
},
};
Note: you need to call z.JSON.stringify() before setting the body.
Using HTTP middleware
To process all HTTP requests in a certain way, use the beforeRequest and afterResponse middleware functions.
Middleware functions go in your app definition:
const addHeader = (request, z, bundle) => {
request.headers['my-header'] = 'from zapier';
return request;
};
const parseXML = (response, z, bundle) => {
response.data = xml.parse(response.content);
return response;
};
const handleWeirdErrors = (response, z) => {
if (response.status === 456) {
response.skipThrowForStatus = true;
} else if (response.status === 200 && response.data.success === false) {
throw new z.errors.Error(response.data.message, response.data.code);
}
return response;
};
const App = {
beforeRequest: [addHeader],
afterResponse: [parseXML, handleWeirdErrors],
};
A beforeRequest middleware function takes a request options object, and returns a (possibly mutated) request object. An afterResponse middleware function takes a response object, and returns a (possibly mutated) response object. Middleware functions are executed in the order specified in the app definition, and each subsequent middleware receives the request or response object returned by the previous middleware.
Middleware functions can be asynchronous - just return a promise from the middleware function.
The second argument for middleware is the z object, but it does not include z.request() as using that would easily create infinite loops.
Here is the full request lifecycle when you call z.request({...}):
- set defaults on the
request object - run your
beforeRequest middleware functions in order - add applicable auth headers (e.g. adding
Basic ... for basic auth), if applicable - add
request.params to request.url - execute the
request, store the result in response - try to auto-parse response body for non-raw requests, store result in
response.data - log the request to Zapier's logging server
- if the status code is
401, you're using a refresh-able auth (such as oauth2 or session) and autoRefresh is true in your auth configuration, throw a RefreshAuthError. The server will attempt to refresh the authentication again and retry the whole step - run your
afterResponse middleware functions in order - call
response.throwForStatus() unless response.skipThrowForStatus is true
The resulting response object is returned from z.request().
Example App: check out https://github.com/zapier/zapier-platform/tree/main/example-apps/middleware for a working example app using HTTP middleware.
Error Response Handling
Since v10.0.0, z.request() calls response.throwForStatus() before it returns a response. You can disable automatic error throwing by setting skipThrowForStatus on the request object:
const perform = async (z, bundle) => {
const response = await z.request({
url: '...',
skipThrowForStatus: true
});
if (response.status >= 400) {
throw new z.errors.ResponseError(response);
}
};
You can also do it in afterResponse if the API uses a status code >= 400 that should not be treated as an error.
const disableAutoThrowOn456 = (response, z) => {
if (response.status === 456) {
response.skipThrowForStatus = true;
}
return response;
};
const App = {
afterResponse: [disableAutoThrowOn456],
};
For developers using v9.x and below, it's your responsibility to throw an exception for an error response. That means you should call response.throwForStatus() or throw an error yourself, likely following the z.request call.
This behavior has changed periodically across major versions, which changes how/when you have to worry about handling errors. Here's a diagram to illustrate that:
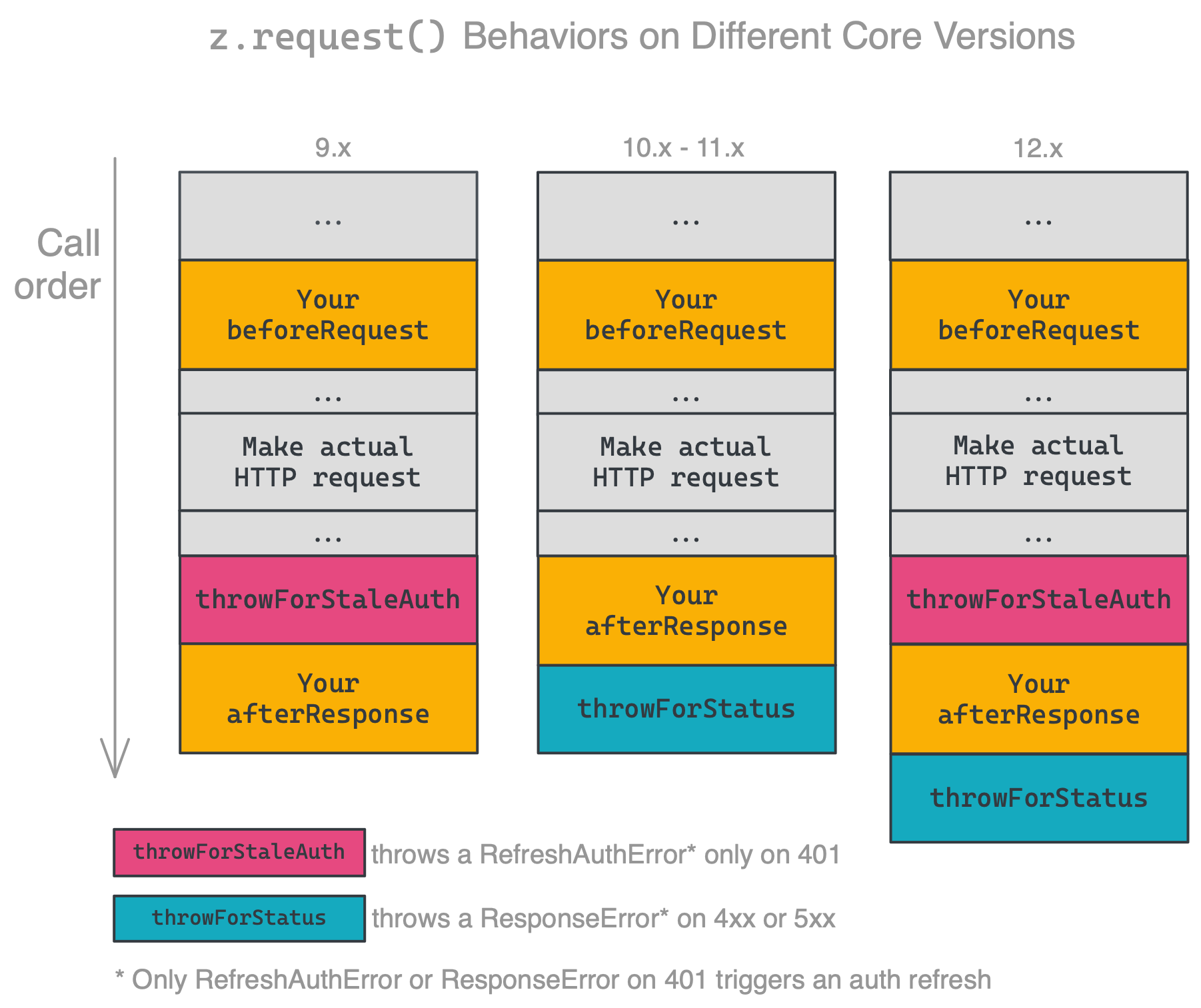
Ensure you're handling errors correctly for your platform version. The latest released version is 15.16.0.
HTTP Request Options
Shorthand requests and manual requests support the following HTTP options:
url: HTTP url, you can provide it as a separate argument (z.request(url, options)) or as part of the options object (z.request({url: url, ...})).method: HTTP method, default is GET.headers: request headers object, format {'header-key': 'header-value'}.params: URL query params object, format {'query-key': 'query-value'}.body: request body, can be a string, buffer, readable stream or plain object. When it is an object/array and the Content-Type header is application/x-www-form-urlencoded the body will be transformed to query string parameters, otherwise we'll set the header to application/json; charset=utf-8 and JSON encode the body. Default is null.allowGetBody: include body in GET requests. Set to true to enable. Default is false. Set only if required by the receiving API. See section 4.3.1 in RFC 7231.json: shortcut object/array/etc. you want to JSON encode into body. Default is null.form: shortcut object. you want to form encode into body. Default is null.raw: set this to stream the response instead of consuming it immediately. Default is false.redirect: set to manual to extract redirect headers, error to reject redirect, default is follow.follow: maximum redirect count, set to 0 to not follow redirects. default is 20.compress: support gzip/deflate content encoding. Set to false to disable. Default is true.agent: Node.js http.Agent instance, allows custom proxy, certificate etc. Default is null.timeout: request / response timeout in ms. Set to 0 to disable (OS limit still applies), timeout reset on redirect. Default is 0 (disabled).signal (added in v15.14.1): enables cancelling requests via a timeout set by an AbortController. More details in node-fetch docs here. Default is null.size: maximum response body size in bytes. Set to 0 to disable. Default is 0 (disabled).skipThrowForStatus (added in v10.0.0): don't call response.throwForStatus() before resolving the request with response. See HTTP Response Object.
const response = await z.request({
url: 'https://example.com',
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: {hello: 'world'},
json: {hello: 'world'},
form: {hello: 'world'},
raw: false,
redirect: 'follow',
follow: 20,
compress: true,
agent: null,
timeout: 0,
size: 0,
})
HTTP Response Object
The response object returned by z.request([url], options) supports the following fields and methods:
status: The response status code, i.e. 200, 404, etc.content: The response content as a String. For Buffer, try options.raw = true.data (added in v10.0.0): The response content as an object if the content is JSON or application/x-www-form-urlencoded (undefined otherwise).headers: Response headers object. The header keys are all lower case.getHeader(key): Retrieve response header, case insensitive: response.getHeader('My-Header')skipThrowForStatus (added in v10.0.0): don't call throwForStatus() before resolving the request with this response.throwForStatus(): Throws an error if 400 <= statusCode < 600.request: The original request options object (see above).
Additionally, if request.raw is true, the raw response has the following properties:
json(): Get the response content as an object, if options.raw = true and content is JSON (returns a promise). undefined in non-raw requests.body: A stream available only if you provide options.raw = true.
const response = await z.request({
});
response.status;
response.headers['Content-Type'];
response.getHeader('content-type');
response.request;
response.throwForStatus();
if (options.raw === false) {
response.data;
z.JSON.parse(response.content);
querystring.parse(response.content);
response.json;
z.JSON.parse(response.content);
} else {
const buf = await response.buffer();
buf.toString();
const text = await response.text();
const json = await response.json();
response.body.pipe(otherStream);
}
Dehydration
Dehydration, and its counterpart Hydration, is a tool that can lazily load data that might be otherwise expensive to retrieve aggressively.
- Dehydration - think of this as "make a pointer", you control the creation of pointers with
z.dehydrate(func, inputData) (or z.dehydrateFile(func, inputData) for files). This usually happens in a trigger step. - Hydration - think of this as an automatic step that "consumes a pointer" and "returns some data", Zapier does this automatically behind the scenes. This usually happens in an action step.
This is very common when Stashing Files - but that isn't their only use!
The method z.dehydrate(func, inputData) has two required arguments:
func - the function to call to fetch the extra data. Can be any raw function, defined in the file doing the dehydration or imported from another part of your app. You must also register the function in the app's hydrators property. Note that since v10.1.0, the maximum payload size to pass to z.dehydrate / z.dehydrateFile is 6KB.inputData - this is an object that contains things like a path or id - whatever you need to load data on the other side- A known limitation of hydration is a 5 minute cache if the hydration call is made with identical
inputData within that timeframe. To workaround this cache for records triggering hydration in close succession, include a unique value in the inputData, for example a timestamp in addition to the record id.
Why do I need to register my functions? Because of how JavaScript works with its module system, we need an explicit handle on the function that can be accessed from the App definition without trying to "automagically" (and sometimes incorrectly) infer code locations.
Here is an example that pulls in extra data for a movie:
const getMovieDetails = async (z, bundle) => {
const url = `https://example.com/movies/${bundle.inputData.id}.json`;
const response = await z.request(url);
return response.data;
};
const movieList = async (z, bundle) => {
const response = await z.request('https://example.com/movies.json');
return response.data.map((movie) => {
movie.details = z.dehydrate(getMovieDetails, { id: movie.id });
return movie;
});
};
const App = {
version: require('./package.json').version,
platformVersion: require('zapier-platform-core').version,
hydrators: {
getMovieDetails,
},
triggers: {
new_movie: {
noun: 'Movie',
display: {
label: 'New Movie',
description: 'Triggers when a new Movie is added.',
},
operation: {
perform: movieList,
},
},
},
};
module.exports = App;
And in future steps of the Zap - if Zapier encounters a pointer as returned by z.dehydrate(func, inputData) - Zapier will tie it back to your app and pull in the data lazily.
Why can't I just load the data immediately? Isn't it easier? In some cases it can be - but imagine an API that returns 100 records when polling - doing 100x GET /id.json aggressive inline HTTP calls when 99% of the time Zapier doesn't need the data yet is wasteful.
Merging Hydrated Data
As you've seen, the usual call to dehydrate will assign the result to an object property:
movie.details = z.dehydrate(getMovieDetails, { id: movie.id });
In this example, all of the movie details will be located in the details property (e.g. details.releaseDate) after hydration occurs. But what if you want these results available at the top-level (e.g. releaseDate)? Zapier supports a specific keyword for this scenario:
movie.$HOIST$ = z.dehydrate(getMovieDetails, { id: movie.id });
Using $HOIST$ as the key will signal to Zapier that the results should be merged into the object containing the $HOIST$ key. You can also use this to merge your hydrated data into a property containing "partial" data that exists before dehydration occurs:
movie.details = {
title: movie.title,
$HOIST$: z.dehydrate(getMovieDetails, { id: movie.id })
};
File Dehydration
Added in v7.3.0.
The method z.dehydrateFile(func, inputData) allows you to download a file lazily. It takes the same arguments as z.dehydrate(func, inputData) does, but is recommended when the data is a file.
An example can be found in the Stashing Files section.
What makes z.dehydrateFile different from z.dehydrate has to do with efficiency and when Zapier chooses to hydrate data. Knowing which pointers give us back files helps us delay downloading files until it's absolutely necessary. Not only will it help avoid unnecessary file downloads, it can also prevent errors if the file has a limited availability. (Stashing files, described below, can also help with that situation.)
A good example is when users are creating Zaps in the Zap Editor. If a pointer is made by z.dehydrate, the Zap Editor will hydrate the data immediately after pulling in samples. This allows users to map fields from the hydrated data into the subsequent steps of the Zap. If, however, the pointer is made by z.dehydrateFile, the Zap Editor will wait to hydrate the file, and will display a placeholder instead. There's nothing inside binary file data for users to map in the subsequent steps.
z.dehydrateFile(func, inputData) was added in v7.3.0. We used to recommend using z.dehydrate(func, inputData) for files, but we now recommend changing it to z.dehydrateFile(func, inputData) for a better user experience.
Stashing Files
It can be expensive to download and stream files or they can require complex handshakes to authorize downloads - so we provide a helpful stash routine that will take any String, Buffer or Stream and return a URL file pointer suitable for returning from triggers, searches, creates, etc.
The interface z.stashFile(bufferStringStream, [knownLength], [filename], [contentType]) takes a single required argument - the extra three arguments will be automatically populated in most cases. Here's a full example:
const content = 'Hello world!';
const url = await z.stashFile(content, content.length, 'hello.txt', 'text/plain');
z.console.log(url);
Most likely you'd want to stream from another URL - note the usage of z.request({raw: true}):
const fileRequest = z.request({url: 'https://example.com/file.pdf', raw: true});
const url = await z.stashFile(fileRequest);
z.console.log(url);
Note: you should only be using z.stashFile() in a hydration method or a hook trigger's perform if you're sending over a short-lived URL to a file. Otherwise, it can be very expensive to stash dozens of files in a polling call - for example!
See a full example with dehydration/hydration wired in correctly:
const stashPDFfunction = (z, bundle) => {
const filePromise = z.request({
url: bundle.inputData.downloadUrl,
raw: true,
});
return z.stashFile(filePromise);
};
const pdfList = async (z, bundle) => {
const response = await z.request('https://example.com/pdfs.json');
return response.data.map((pdf) => {
pdf.file = z.dehydrateFile(stashPDFfunction, {
downloadUrl: pdf.secret_download_url,
});
delete pdf.secret_download_url;
return pdf;
});
};
const App = {
version: require('./package.json').version,
platformVersion: require('zapier-platform-core').version,
hydrators: {
stashPDF: stashPDFfunction,
},
triggers: {
new_pdf: {
noun: 'PDF',
display: {
label: 'New PDF',
description: 'Triggers when a new PDF is added.',
},
operation: {
perform: pdfList,
},
},
},
};
module.exports = App;
To create a new integration for handling files, run zapier init [your app name] --template files. You can also check out our working example app here.
Logging
To view the logs for your application, use the zapier logs command.
There are three types of logs for a Zapier app:
http: logged automatically by Zapier on HTTP requestsbundle: logged automatically on every method executionconsole: manual logs via z.console.log() statements (see below for details)
Note that by default, this command will only fetch logs associated to your user.
For advanced logging options, including the option to fetch logs for other users or specific app versions, look at the help for the logs command:
zapier help logs
Console Logging
To manually print a log statement in your code, use z.console.log:
z.console.log('Here are the input fields', bundle.inputData);
The z.console object has all the same methods and works just like the Node.js Console class - the only difference is we'll log to our distributed datastore and you can view the logs via zapier logs (more below).
Viewing Console Logs
To see your z.console.log logs, do:
zapier logs --type=console
Viewing Bundle Logs
To see the bundle logs, do:
zapier logs --type=bundle
HTTP Logging
If you are using shorthand HTTP requests or the z.request() method that we provide, HTTP logging is handled automatically for you. For example:
z.request('https://57b20fb546b57d1100a3c405.mockapi.io/api/recipes')
.then((res) => {
return res;
})
HTTP logging will often work with other methods of making requests as well, but if you're using another method and having trouble seeing logs, try using z.request().
Viewing HTTP Logs
To see the HTTP logs, do:
zapier logs --type=http
To see detailed HTTP logs, including data such as headers and request and response bodies, do:
zapier logs --type=http --detailed
Error Handling
APIs are not always available. Users do not always input data correctly to
formulate valid requests. Thus, it is a good idea to write apps defensively and
plan for 4xx and 5xx responses from APIs. Without proper handling, errors often
have incomprehensible messages for end users, or possibly go uncaught.
Zapier provides a couple of tools to help with error handling. First is the
afterResponse middleware (docs), which provides a hook for
processing all responses from HTTP calls. Second is response.throwForStatus()
(docs), which throws an error if the response status indicates
an error (status >= 400). Since v10.0.0, we automatically call this method before returning the
response, unless you set skipThrowForStatus on the request or response object. The
last tool is the collection of errors in z.errors (docs), which control
the behavior of Zaps when various kinds of errors occur.
General Errors
Errors due to a misconfiguration in a user's Zap should be handled in your app
by throwing z.errors.Error with a user-friendly message and optional error and
status code. Typically, this will be prettifying 4xx responses or APIs that return
errors as 200s with a payload that describes the error.
Example: throw new z.errors.Error('Contact name is too long.', 'InvalidData', 400);
z.errors.Error was added in v9.3.0. If you're on an older version of zapier-platform-core, throw a standard JavaScript Error instead, such as throw new Error('A user-friendly message').
A couple best practices to keep in mind:
- Elaborate on terse messages. "not_authenticated" -> "Your API Key is invalid. Please reconnect your account."
- If the error calls out a specific field, surface that information to the user. "Provided data is invalid" -> "Contact name is invalid"
- If the error provides details about why a field is invalid, add that in too! "Contact name is invalid" -> "Contact name is too long"
- The second, optional argument should be a code that a computer could use to identify the type of error.
- The last, optional argument should be the HTTP status code, if any.
The code and status can be used by us to provide relevant troubleshooting to the
user when we communicate the error.
Note that if a Zap raises too many error messages it will be automatically
turned off, so only use these if the scenario is truly an error that needs to
be fixed.
Halting Execution
Any operation can be interrupted or "halted" (not success, not error, but
stopped for some specific reason) with a HaltedError. You might find yourself
using this error in cases where a required pre-condition is not met. For instance,
in a create to add an email address to a list where duplicates are not allowed,
you would want to throw a HaltedError if the Zap attempted to add a duplicate.
This would indicate failure, but it would be treated as a soft failure.
Unlike throwing z.errors.Error, a Zap will never by turned off when this error is thrown
(even if it is raised more often than not).
Example: throw new z.errors.HaltedError('Your reason.');
Stale Authentication Credentials
For apps that require manual refresh of authorization on a regular basis, Zapier
provides a mechanism to notify users of expired credentials. With the
ExpiredAuthError, the current operation is interrupted and a predefined email
is sent out asking the user to refresh the credentials. While the auth is
disconnected, Zap runs will not be executed, to prevent more calls with expired
credentials. (The runs will be
Held,
and the user will be able to replay them after reconnecting.)
Example: throw new z.errors.ExpiredAuthError('You must manually reconnect this auth.');
For apps that use OAuth2 with autoRefresh: true or Session Auth, core injects
a built-in afterResponse middleware that throws an error when the response status
is 401. The error will signal Zapier to refresh the credentials and then retry the
failed operation. You can also throw this error manually if your server doesn't use the 401 status or you want to trigger an auth refresh even if the credentials aren't stale.
Example: throw new z.errors.RefreshAuthError();
Handling Throttled Requests
Since v11.2.0, there are two types of errors that can cause Zapier to throttle an operation and retry at a later time.
This is useful if the API you're interfacing with reports it is receiving too many requests, often indicated by
receiving a response status code of 429.
If a response receives a status code of 429 and is not caught, Zapier will re-attempt the operation after a delay.
The delay can be customized by the server response containing a specific
Retry-After header in your error response or with a specified time delay in seconds using a ThrottledError:
const yourAfterResponse = (resp) => {
if (resp.status === 429) {
throw new z.errors.ThrottledError('message here', 60);
}
return resp;
};
Instead of a user’s Zap erroring and halting, the request will be repeatedly retried at the specified time.
For throttled requests that occur during processing of a webhook trigger's perform, before results are produced; there is a max retry delay of 300 seconds and a default delay of 60 seconds if none is specified. For webhook processing only, if a request during the retry attempt is also throttled, it will not be re-attempted again.
Testing
You can write unit tests for your Zapier integration that run locally, outside of the Zapier editor.
You can run these tests in a CI tool like Travis.
Writing Unit Tests
From v10 of zapier-platform-cli, we recommend using the Jest testing framework. After running zapier init you should find an example test to start from in the test directory.
Note: On v9, the recommendation was Mocha. You can still use Mocha if you prefer.
const zapier = require('zapier-platform-core');
const App = require('../index');
const appTester = zapier.createAppTester(App);
zapier.tools.env.inject();
describe('triggers', () => {
test('new recipe', async () => {
const bundle = {
inputData: {
style: 'mediterranean',
},
};
const results = await appTester(
App.triggers.recipe.operation.perform,
bundle
);
expect(results.length).toBeGreaterThan(1);
const firstRecipe = results[0];
expect(firstRecipe.id).toBe(1);
expect(firstRecipe.name).toBe('Baked Falafel');
});
});
Using the z Object in Tests
Introduced in core@11.1.0, appTester can now run arbitrary functions:
const zapier = require('zapier-platform-core');
const App = require('../index');
const appTester = zapier.createAppTester(App);
describe('triggers', () => {
test('new recipe', async () => {
const adHocResult = await appTester(
async (z, bundle) => {
const response = await z.request(
'https://example.com/some/setup/method',
{
params: {
numItems: bundle.inputData.someValue,
},
}
);
return {
someHash: z.hash('md5', 'mySecret'),
data: response.data,
};
},
{
authData: { token: 'some-api-key' },
inputData: {
someValue: 3,
},
}
);
expect(adHocResult.someHash).toEqual('a5beb6624e092adf7be31176c3079e64');
expect(adHocResult.data).toEqual({ whatever: true });
});
});
Mocking Requests
It's useful to test your code without actually hitting any external services. Nock is a Node.js utility that intercepts requests before they ever leave your computer. You can specify a response code, body, headers, and more. It works out of the box with z.request by setting up your nock before calling appTester.
const zapier = require('zapier-platform-core');
const App = require('../index');
const appTester = zapier.createAppTester(App);
const nock = require('nock');
describe('triggers', () => {
test('new recipe', async () => {
const bundle = {
inputData: {
style: 'mediterranean',
},
};
nock('https://example.com/api')
.get('/recipes')
.query(bundle.inputData)
.reply(200, [
{ name: 'name 1', directions: 'directions 1', id: 1 },
{ name: 'name 2', directions: 'directions 2', id: 2 },
]);
const results = await appTester(
App.triggers.recipe.operation.perform,
bundle
);
expect(results.length).toBeGreaterThan(1);
const firstRecipe = results[0];
expect(firstRecipe.id).toBe(1);
expect(firstRecipe.name).toBe('name 1');
});
});
Here's more info about nock and its usage in the README.
Running Unit Tests
To run all your tests do:
zapier test
You can also go direct with npm test or node_modules/.bin/jest.
Testing & Environment Variables
The best way to store sensitive values (like API keys, OAuth secrets, or passwords) is in an .env (or .environment, see below note) file (learn more). Then, you can include the following before your tests run:
const zapier = require('zapier-platform-core');
zapier.tools.env.inject();
.env is the new recommended name for the environment file since v5.1.0. The old name .environment is deprecated but will continue to work for backward compatibility.
Remember: NEVER add your secrets file to version control!
Additionally, you can provide them dynamically at runtime:
CLIENT_ID=1234 CLIENT_SECRET=abcd zapier test
Or, export them explicitly and place them into the environment:
export CLIENT_ID=1234
export CLIENT_SECRET=abcd
zapier test
Testing in Your CI
Whether you use Travis, Circle, Jenkins, or another service, we aim to make it painless to test in an automated environment.
Behind the scenes zapier test does a standard npm test, which could be Jest or Mocha, based on your project setup.
This makes it straightforward to integrate into your testing interface. For example, if you want to test with Travis CI, the .travis.yml would look something like this:
language: node_js
node_js:
- "v18"
before_script: npm install -g zapier-platform-cli
script: CLIENT_ID=1234 CLIENT_SECRET=abcd zapier test
You can substitute zapier test with npm test, or a direct call to node_modules/.bin/jest. We recommend putting environment variables directly into the configuration screens Jenkins, Travis, or other services provide.
Alternatively to reading the deploy key from root (the default location), you may set the ZAPIER_DEPLOY_KEY environment variable to run privileged commands without the human input needed for zapier login. We suggest encrypting your deploy key in the manner your CI provides (such as these instructions, for Travis).
Debugging Tests
Sometimes tests aren't enough, and you may want to step through your code and set breakpoints. The testing suite is a regular Node.js process, so debugging it doesn't take anything special. Because we recommend jest for testing, these instructions will outline steps for debugging w/ jest, but other test runners will work similarly. You can also refer to Jest's own docs on the subject.
To start, add the following line to the scripts section of your package.json:
"test:debug": "node --inspect-brk node_modules/.bin/jest --runInBand"
This will tell node to inspect the jest processes, which is exactly what we need.
Next, add a debugger; statement somewhere in your code, probably in a perform method:
const perform = async (z, bundle) => {
const response = await z.request({
url: "https://jsonplaceholder.typicode.com/posts",
params: {
tag: bundle.inputData.tagName,
},
});
debugger;
return response.data;
};
This creates a breakpoint while inspecting, or a starting point for our manual inspection.
Next, you'll need an inspection client. The most available one is probably the Google Chrome browser, but there are lots of options. We'll use Chrome for this example. In your terminal (and in your integration's root directory), run yarn test:debug (or npm run test:debug). You should see the following:
% yarn test:debug
yarn run v1.22.10
$ node --inspect-brk node_modules/.bin/jest --runInBand
Debugger listening on ws://127.0.0.1:9229/5edaab3c-a1d3-45e4-b374-0536095c559b
For help, see: https://nodejs.org/en/docs/inspector
Now in Chrome, go to chrome://inspect. Make sure Discover Network Targets is checked and you should see a path to your jest file on your local machine:
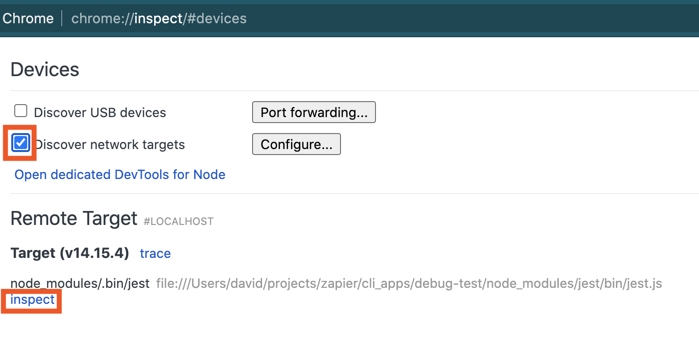
Click inspect. A new window will open. Next, click the little blue arrow in the top right to actually run the code:
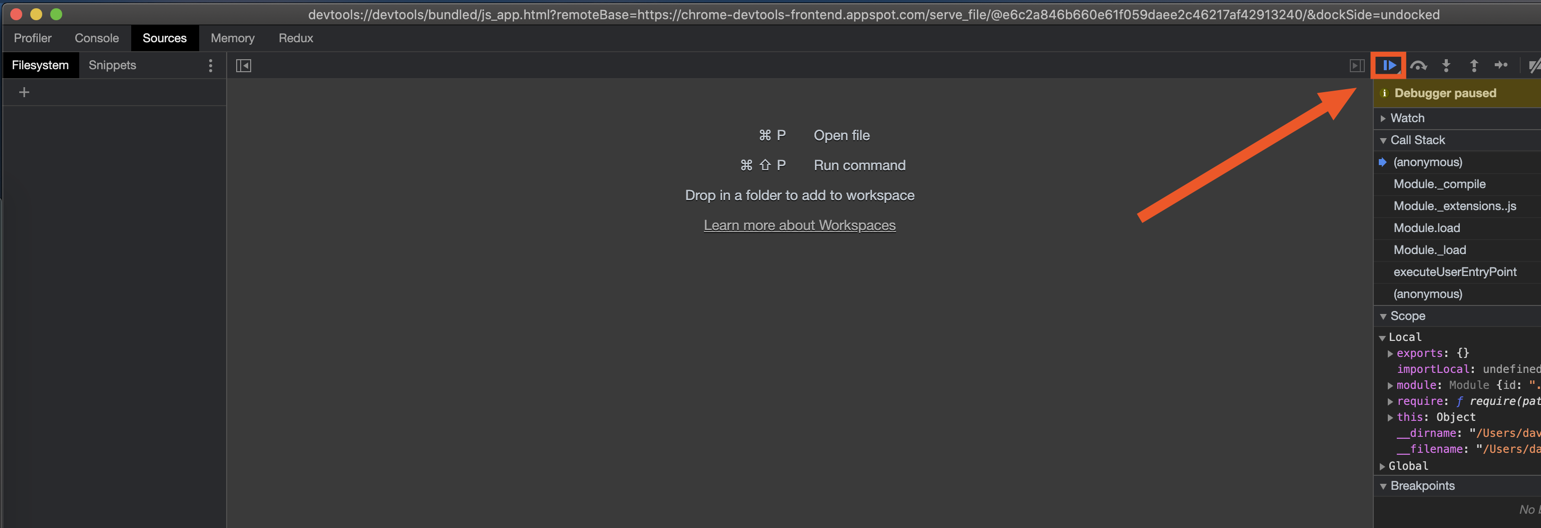
After a few seconds, you'll see your code, the debugger statement, and info about the current environment on the right panel. You should see familiar data in the Locals section, such as the response variable, and the z object.
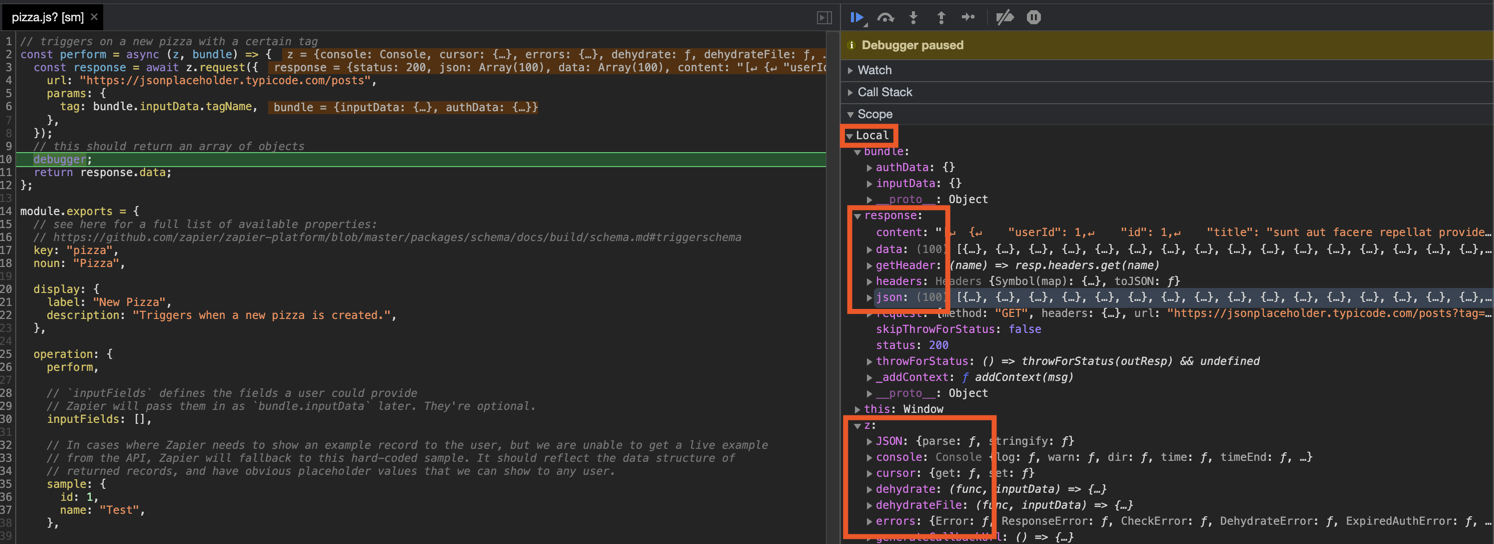
Debugging combined with thorough unit tests will hopefully equip you in keeping your Zapier integration in smooth working order.
Using npm Modules
Use npm modules just like you would use them in any other node app, for example:
npm install --save jwt
And then package.json will be updated, and you can use them like anything else:
const jwt = require('jwt');
During the zapier build or zapier push step - we'll copy all your code to a temporary folder and do a fresh re-install of modules.
Note: If your package isn't being pushed correctly (IE: you get "Error: Cannot find module 'whatever'" in production), try adding the --disable-dependency-detection flag to zapier push.
Note 2: You can also try adding a includeInBuild array property (with paths to include, which will be evaluated to RegExp, with a case insensitive flag) to your .zapierapprc file, to make it look like:
{
"id": 1,
"key": "App1",
"includeInBuild": [
"test.txt",
"testing.json"
]
}
Warning: Do not use compiled libraries unless you run your build on the AWS AMI ami-4fffc834, or follow the Docker instructions below.
Building Native Packages with Docker
Unfortunately if you are developing on a macOS or Windows box you won't be able to build native libraries locally. If you try and push locally build native modules, you'll get runtime errors during usage. However, you can use Docker and Docker Compose to do this in a pinch. Make sure you have all the necessary Docker programs installed and follow along.
First, create your Dockerfile:
FROM amazonlinux:2017.03.1.20170812
RUN yum install zip findutils wget gcc44 gcc-c++ libgcc44 cmake -y
RUN wget https://nodejs.org/dist/v8.10.0/node-v8.10.0.tar.gz && \
tar -zxvf node-v8.10.0.tar.gz && \
cd node-v8.10.0 && \
./configure && \
make && \
make install && \
cd .. && \
rm -rf node-v8.10.0 node-v8.10.0.tar.gz
RUN npm i -g zapier-platform-cli
WORKDIR /app
And finally, create your docker-compose.yml file:
version: '3.4'
services:
pusher:
build: .
volumes:
- .:/app
- node_modules:/app/node_modules:delegated
- ~/.zapierrc:/root/.zapierrc
command: 'bash -c "npm i && zapier push"'
environment:
ZAPIER_DEPLOY_KEY: ${ZAPIER_DEPLOY_KEY}
volumes:
node_modules:
Note: Watch out for your package-lock.json file, if it exists for local install it might incorrectly pin a native version.
Now you should be able to run docker-compose run pusher and see the build and push successfully complete!
Using Transpilers
If you would like to use a transpiler like babel, you can add a script named _zapier-build to your package.json, which will be run during zapier build,
zapier push, and zapier upload. See the following example:
{
"scripts": {
"zapier-dev": "babel src --out-dir lib --watch",
"_zapier-build": "babel src --out-dir lib"
}
}
Then, you can have your fancy ES7 code in src/* and a root index.js like this:
module.exports = require('./lib');
And work with commands like this:
npm run zapier-dev
zapier test
zapier push
There are a lot of details left out - check out the full example app here.
We recommend using zapier init . to create an app - you’ll be presented with a list of currently available example templates to start with.
FAQs
Why doesn't Zapier support newer versions of Node.js?
We run your code on AWS Lambda, which only supports a few versions of Node. Sometimes that doesn't include the latest version. Additionally, with thousands of apps running on the Zapier platform, we have to be sure upgrading to the latest Node version will not have a negative impact.
How do I manually set the Node.js version to run my app with?
Update your zapier-platform-core dependency in package.json. Each major version ties to a specific version of Node.js. You can find the mapping here. We only support the version(s) supported by AWS Lambda.
IMPORTANT CAVEAT: AWS periodically deprecates Node versions as they reach EOL. They announce thison their blog. Similar info and dates are available on github. Well before this date, we'll have a version of core that targets the newer Node version.
If you don't upgrade before the cutoff date, there's a chance that AWS will throw an error when attempting to run your app's code. If that's the case, we'll instead run it under the oldest Node version still supported. All that is to say, we may run your code on a newer version of Node.js than you intend if you don't update your app's dependencies periodically.
When to use placeholders or curlies?
You will see both template literal placeholders ${var} and (double) "curlies" {{var}} used in examples.
In general, use ${var} within functions and use {{var}} anywhere else.
Placeholders get evaluated as soon as the line of code is evaluated. This means that if you use ${process.env.VAR} in a trigger configuration, zapier push will substitute it with your local environment's value for VAR when it builds your app and the value set via zapier env:set will not be used.
If you're not familiar with template literals, know that const val = "a" + b + "c" is essentially the same as const val = `a${b}c`.
Does Zapier support XML (SOAP) APIs?
Not natively, but it can! Users have reported that the following npm modules are compatible with the CLI Platform:
Since core v10, it's possible for shorthand requests to parse XML. Use an afterResponse middleware that sets response.data to the parsed XML:
const xml = require('pixl-xml');
const App = {
afterResponse: [
(response, z, bundle) => {
response.throwForStatus();
response.data = xml.parse(response.content);
return response;
},
],
};
Is it possible to iterate over pages in a polling trigger?
Yes, though there are caveats. Your entire function only gets 30 seconds to run. HTTP requests are costly, so paging through a list may time out (which you should avoid at all costs).
const makeCall = (z, start, limit) => {
return z.request({
url: 'https://jsonplaceholder.typicode.com/posts',
params: {
_start: start,
_limit: limit,
},
});
};
const performPaging = async (z, bundle) => {
const promises = [];
let start = 0;
const limit = 3;
for (let i = 0; i < 5; i++) {
promises.push(makeCall(z, start, limit));
start += limit;
}
const responses = await Promise.all(promises);
return responses.map((res) => res.data);
};
module.exports = {
key: 'paging',
noun: 'Paging',
display: {
label: 'Get Paging',
description: 'Triggers on a new paging.',
},
operation: {
inputFields: [],
perform: performPaging,
},
};
If you need to do more requests conditionally based on the results of an HTTP call (such as the "next URL" param or similar value), using async/await (as shown in the example below) is a good way to go. If you go this route, only page as far as you need to. Keep an eye on the polling guidelines, namely the part about only iterating until you hit items that have probably been seen in a previous poll.
const asyncExample = async (z, bundle) => {
const limit = 3;
let start = 0;
const twoHourMilliseconds = 60 * 60 * 2 * 1000;
const hoursAgo = new Date() - twoHourMilliseconds;
let response = await z.request({
url: 'https://jsonplaceholder.typicode.com/posts',
params: {
_start: start,
_limit: limit,
},
});
let results = response.data;
while (new Date(results[results.length - 1].createdAt) > hoursAgo) {
start += limit;
response = await z.request({
url: 'https://jsonplaceholder.typicode.com/posts',
params: {
_start: start,
_limit: limit,
},
});
results = results.concat(response.data);
}
return results;
};
How do search-powered fields relate to dynamic dropdowns and why are they both required together?
To understand search-powered fields, we have to have a good understanding of dynamic dropdowns.
When users are selecting specific resources (for instance, a Google Sheet), it's important they're able to select the exact sheet they want. Instead of referencing the sheet by name (which may change), we match via id instead. Rather than directing the user copy and paste an id for every item they might encounter, there is the notion of a dynamic dropdown. A dropdown is a trigger that returns a list of resources. It can pull double duty and use its results to power another trigger, search, or action in the same app. It provides a list of ids with labels that show the item's name:
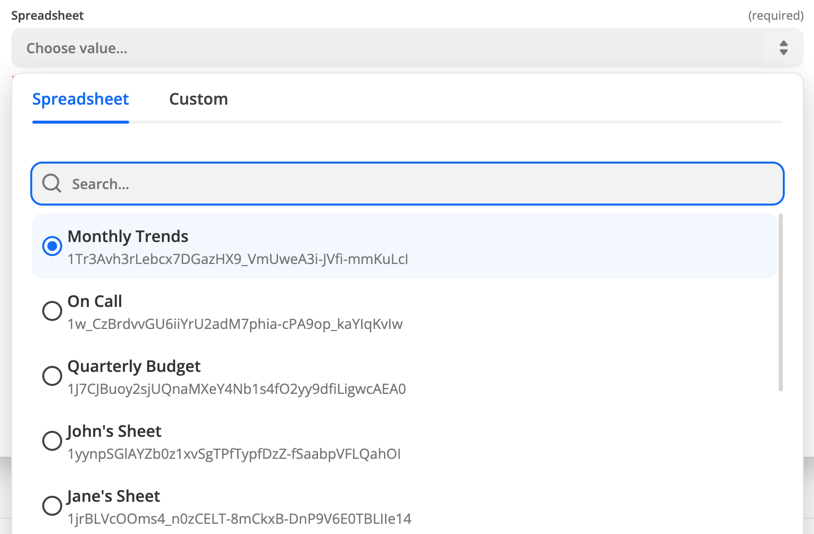
The field's value reaches your app as an id. You define this connection with the dynamic property, which is a string: trigger_key.id_key.label_key. This approach works great if the user setting up the Zap always wants the Zap to use the same spreadsheet. They specify the id during setup and the Zap runs happily.
Search fields take this connection a step further. Rather than set the spreadsheet id at setup, the user could precede the action with a search field to make the id dynamic. For instance, let's say you have a different spreadsheet for every day of the week. You could build the following zap:
- Some Trigger
- Calculate what day of the week it is today (Code)
- Find the spreadsheet that matches the day from Step 2
- Update the spreadsheet (with the id from step 3) with some data
If the connection between steps 3 and 4 is a common one, you can indicate that in your field by specifying search as a search_key.id_key. When paired with a dynamic dropdown, this will add a button to the editor that will add the search step to the user's Zap and map the id field correctly.
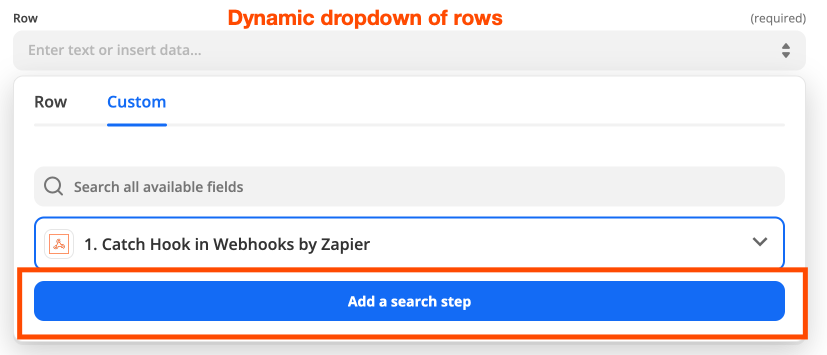
This is paired most often with "update" actions, where a required parameter will be a resource id.
What's the deal with pagination? When is it used and how does it work?
Paging is only used when a trigger is part of a dynamic dropdown. Depending on how many items exist and how many are returned in the first poll, it's possible that the resource the user is looking for isn't in the initial poll. If they hit the "see more" button, we'll increment the value of bundle.meta.page and poll again.
Paging is a lot like a regular trigger except the range of items returned is dynamic. The most common example of this is when you can pass a offset parameter:
const perform = async (z, bundle) => {
const response = await z.request({
url: 'https://example.com/api/list.json',
params: {
limit: 100,
offset: 100 * bundle.meta.page
}
});
return response.data;
};
If your API uses cursor-based paging instead of an offset, you can use z.cursor.get and z.cursor.set:
const perform = async (z, bundle) => {
let cursor;
if (bundle.meta.page > 0) {
cursor = await z.cursor.get();
if (!cursor) {
return [];
}
}
const response = await z.request(
'https://5ae7ad3547436a00143e104d.mockapi.io/api/recipes',
{
params: { cursor },
}
);
await z.cursor.set(response.nextPage ?? '');
return response.items;
};
Cursors are stored per-zap and last about an hour. Per the above, make sure to only include the cursor if bundle.meta.page > 0, so you don't accidentally reuse a cursor from a previous poll.
Lastly, you need to set canPaginate to true in your polling definition (per the schema) for the z.cursor methods to work as expected.
How does deduplication work?
Each time a polling Zap runs, Zapier extracts a unique "primary key" for each item in the response. Zapier needs to decide which of the items should trigger the Zap. To do this, we compare the primary keys to all those we've seen before, trigger on new objects, and update the list of seen primary keys. When a Zap is turned on, we initialize the list of seen primary keys with a single poll. When it's turned off, we clear that list. For this reason, it's important that calls to a polling endpoint always return the newest items.
For example, the initial poll returns objects 4, 5, and 6 (where a higher primary key is newer). If a later poll increases the limit and returns objects 1-6, then 1, 2, and 3 will be (incorrectly) treated like new objects.
By default, the primary key is the item's id field. Since v15.6.0, you can customize the primary key by setting primary to true in outputFields.
There's a more in-depth explanation here.
Why are my triggers complaining if I don't provide an explicit id field?
For deduplication to work, we need to be able to identify and use a unique field. In older, legacy Zapier Web Builder apps, we guessed if id wasn't present. In order to ensure we don't guess wrong, we now require that the developers send us an id field. If your objects have a differently-named unique field, feel free to adapt this snippet and ensure this test passes:
let items = response.data.items;
return items.map((item) => {
item.id = item.contactId;
return item;
});
Since v15.6.0, instead of using the default id field, you can also define one or more outputFields as primary. For example:
{
triggers: {
recipe: {
operation: {
outputField: [
{ key: 'userId', primary: true },
{ key: 'slug', primary: true },
{ key: 'name' }
]
}
}
}
}
will tell Zapier to use (userId, slug) as the unique primary key to deduplicate items when running a polling trigger.
Limitation: The primary option currently doesn't support mixing top-level fields with nested fields that use double underscores in their keys. For example, if you set primary: true on both id and user__id, the primary setting on the user__id field will be ignored; only id will be used for deduplication. However, if all the primary fields are all nested, such as user__id + user__name, it will work as expected.
Node X No Longer Supported
If you're seeing errors like the following:
InvalidParameterValueException An error occurred (InvalidParameterValueException) when calling the CreateFunction operation: The runtime parameter of nodejs6.10 is no longer supported for creating or updating AWS Lambda functions. We recommend you use the new runtime (nodejsX.Y) while creating or updating functions.
... then you need to update your zapier-platform-core dependency to a non-deprecated version that uses a newer version of Node.js. Complete the following instructions as soon as possible:
- Edit
package.json to depend on a later major version of zapier-platform-core. There's a list of all breaking changes (marked with a :exclamation:) in the changelog. - Increment the
version property in package.json - Ensure you're using version
v18 (or greater) of node locally (node -v). Use nvm to use a different one if need be. - Run
rm -rf node_modules && npm i to get a fresh copy of everything - Run
zapier test to ensure your tests still pass - Run
zapier push - Run
zapier promote YOUR_NEW_VERSION (from step 2) - Migrate your users from the previous version (
zapier migrate OLD_VERSION YOUR_NEW_VERSION)
What Analytics are Collected?
Starting with v8.4.0, Zapier collects information about each invocation of the CLI tool.
This data is collected purely to improve the CLI experience and will never be used for advertising or any non-product purpose. There are 3 collection modes that are set on a per-computer basis.
Anonymous
When you run a command with analytics in anonymous mode, the following data is sent to Zapier:
- which command you ran
- if that command is a known command
- how many arguments you supplied (but not the contents of the arguments)
- which flags you used (but not their contents)
- the version of CLI that you're using
Enabled (the default)
When analytics are fully enabled, the above is sent, plus:
- your operating system (the result of calling
process.platform) - your Zapier user id
Disabled
Lastly, analytics can be disabled entirely, either by running zapier analytics --mode disabled or setting the DISABLE_ZAPIER_ANALYTICS environment variable to 1.
We take great care not to collect any information about your filesystem or anything otherwise secret. You can see exactly what's being collecting at runtime by prefixing any command with DEBUG=zapier:analytics.
What's the Difference Between an "App" and an "Integration"?
We're in the process of doing some renaming across our Zapier marketing terms. Eventually we'll use "integration" everywhere. Until then, know that these terms are interchangeable and describe the code that you write that connects your API to Zapier.
Command Line Tab Completion
Introduced in v9.1.0, the zapier autocomplete command shows instructions for generating command line autocomplete.
Follow those instructions to enable completion for zapier commands and flags!
The Zapier Platform Packages
The Zapier Platform consists of 3 npm packages that are released simultaneously.
zapier-platform-cli is the code that powers the zapier command. You use it most commonly with the test, scaffold, and push commands. It's installed with npm install -g zapier-platform-cli and does not correspond to a particular app.zapier-platform-core is what allows your app to interact with Zapier. It holds the z object and app tester code. Your app depends on a specific version of zapier-platform-core in the package.json file. It's installed via npm install along with the rest of your app's dependencies.zapier-platform-schema enforces app structure behind the scenes. It's a dependency of core, so it will be installed automatically.
To learn more about the structure of the code (especially if you're interested in contributing), check out the ARCHITECTURE.md file(s).
Updating These Packages
The Zapier platform and its tools are under active development. While you don't need to install every release, we release new versions because they are better than the last. We do our best to adhere to Semantic Versioning wherein we won't break your code unless there's a major release. Otherwise, we're just fixing bugs (patch) and adding features (minor).
Broadly speaking, all releases will continue to work indefinitely. While you never have to upgrade your app's zapier-platform-core dependency, we recommend keeping an eye on the changelog to see what new features and bug fixes are available.
For more info about which Node versions are supported, see the faq.
The most recently released version of cli and core is 15.16.0. You can see the versions you're working with by running zapier -v.
To update cli, run npm install -g zapier-platform-cli.
To update the version of core your app depends on, set the zapier-platform-core dependency in your package.json to a version listed here and reinstall your dependencies (either yarn or npm install).
For maximum compatibility, keep the versions of cli and core in sync.
Get Help!
You can get help by either emailing partners@zapier.com or by joining our developer community here.
Developing on the CLI
See CONTRIBUTING.md.



