Cdocs
A super simple contextual help library.
Cdocs is a Python library that is intended to help manage files for use in context sensitive help and I18n. The library knows how to find docs given a path called a docpath. Docpaths should mirror a logical or physical structure of the application. This way docs are easy find and map cleanly to the way the app works.
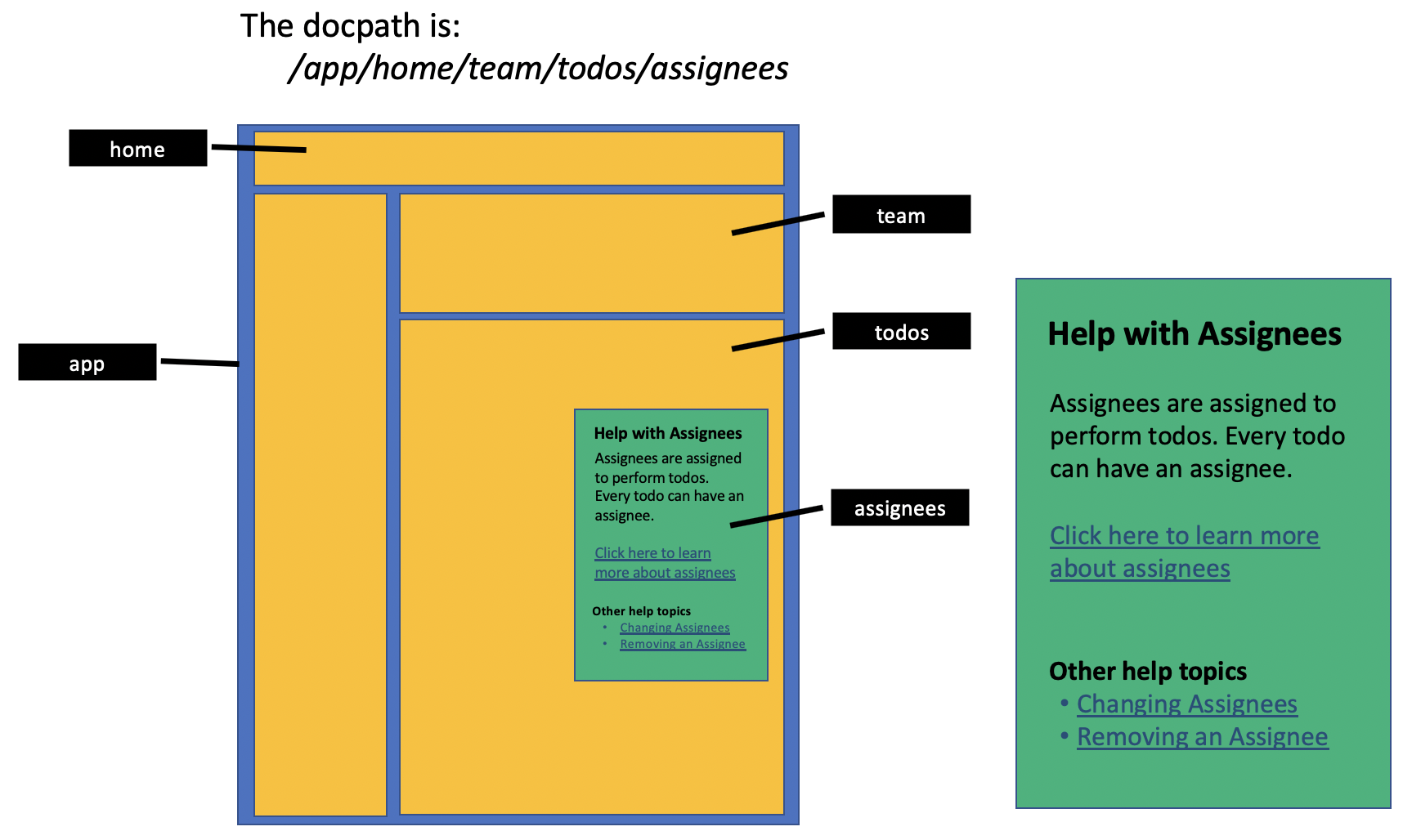
The expected use of Cdocs is to create an endpoint to retrieve in-context help docs and/or UI labels from at runtime. While Cdocs is not an API, the ReadTheDocs Embed API is a good comparison point. Cdocs could also be used to pull docs into an app build. Cdocs is not is not a headless CMS but it could be used to create one.
Cdocs stores documentation as text files in a directory tree. Files are Jinja templates containing whatever doc format you prefer. Cdocs applies tokens to the templates if tokens.json containing dict are found. Files can be concatenated and/or composed.
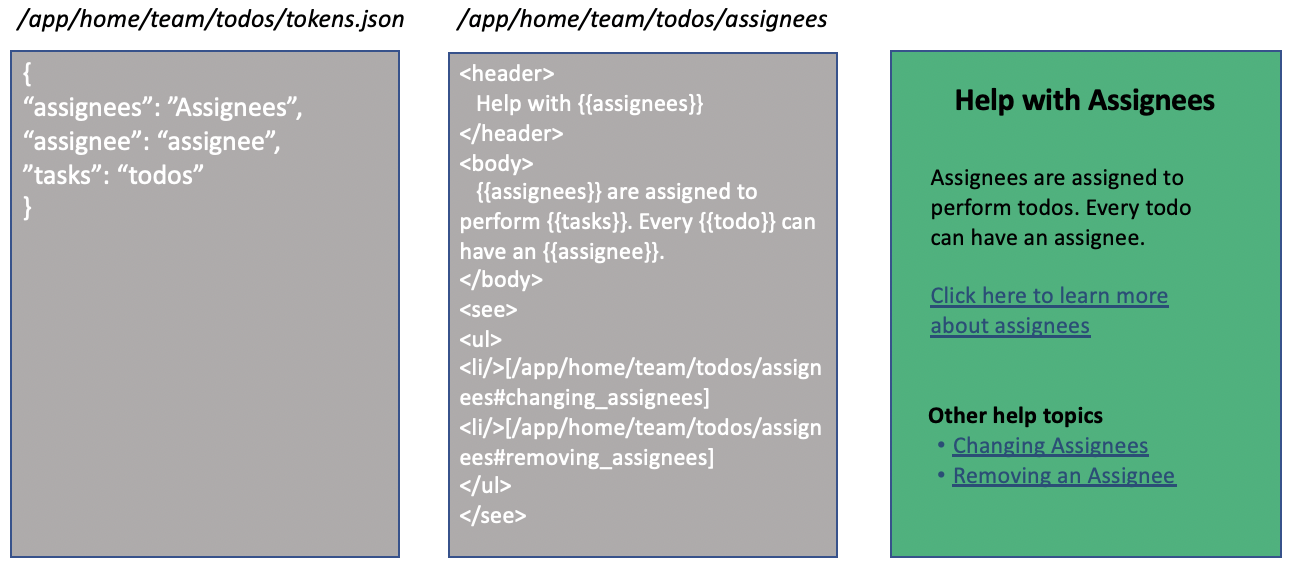
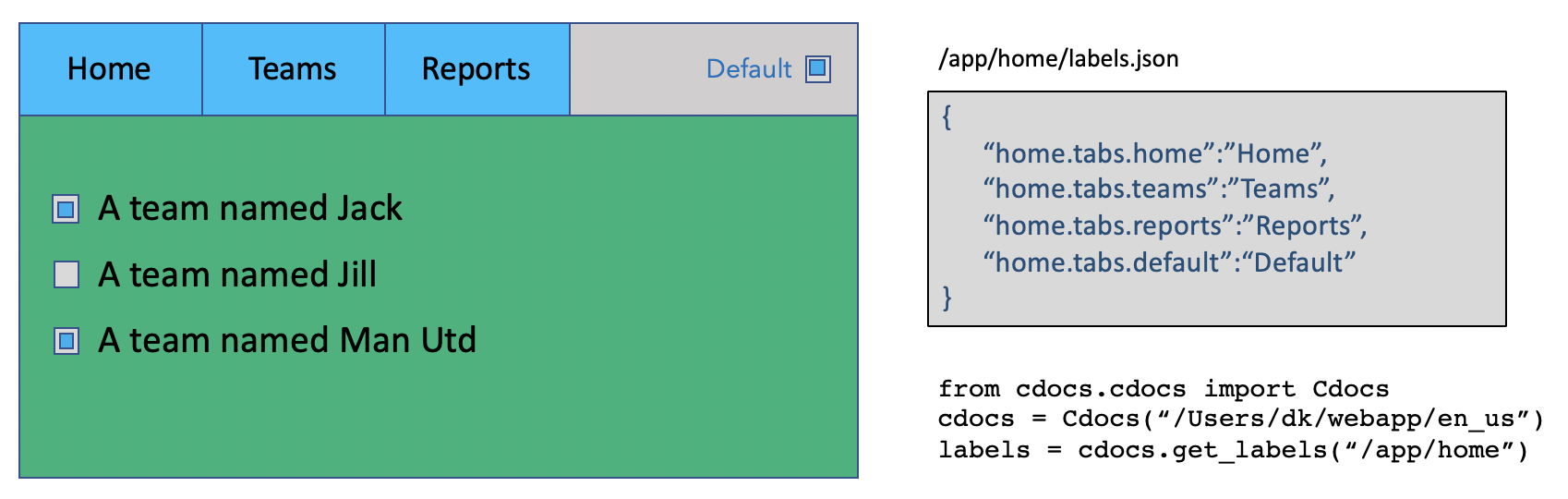
Cdocs can also be used to find text strings referred to as labels. Labels are stored as (non-template) json files containing dict in the same directory tree. The expected use is to find a JSON structure of labels for UI elements that would be seen in the same screen contextual help is available for.
Requests for labels and tokens are aggregated from every directory below root, starting from the requested path. The values found lowest in the directory tree win.
You may configure as many docs directory trees as you find useful. Multi tree requests go against a Context object that implements the MultiContextDocs abstract base class and returns docs by searching the trees in the order they appear in config.ini. You may limit each directory tree to certain file types. Each root is self-contained, meaning that labels and tokens used in doc file transformations are found and applied only within their directory tree. However, multi-context requests for labels return labels aggregated from all trees. If this is not desireable, use the MultiContextDocs interface passing in only the roots you want labels from.
Every transform template -- a doc found at a docpath -- has access to the MultiContextDocs methods and the ContextualDocs methods. The template also includes a docroot variable that indicates the root of the cdocs object that is doing the transformation. This means that transformed docs can include pointers to specific roots to resolve included docpath. For example:
{{ get_doc_from_roots(['public', 'en_US', 'en_UK'], '/app/home/teams/todos/assignee#edit_assignee') }}
One use for this might be for one root to hold user facing docs composed of reusable chunks of content from another root. Finding translated help docs from the same locale would be another good use for this.
Cdocs will return binary files based on a limited set of known file types. Currently the types are 'gif', 'jpeg', 'jpg', 'png', 'pdf'.
Use a config.ini to set the root directories, file extension, etc. The default location for the config file is os.getcwd()/config/config.ini. You can pass a different path in the Cdocs constructor. The contents should be similar to this:
# docs section lists the doc directory roots. use as many as you need.
[docs]
public = /Users/dk/dev/cdocs/docs/example
internal = /Users/dk/dev/cdocs/docs/internal
# accepts limits the file types handled by each root. root names passed to the context will be filtered according to this list.
[accepts]
public = cdocs
internal = gif,png,jpeg
# you can configure defaults to point to a file to return if a doc is not found. if not configured, the response to a path that doesn't exist is None.
[defaults]
notfound = internal/404
# format section indicates the extensions found using /x/y/z paths. 'ext' is the default. others are named by their roots. the formats and accepts sections should agree, excepting where accepts is 'cdocs'
[formats]
ext = xml
internal = gif,png,jpeg
# filenames section lets you change the names of the tokens and labels files, set the name anchor char (hashmark), and the on the fly concatenation char (plus)
[filenames]
tokens = tokens.json
labels = labels.json
hashmark = #
plus = +
Cdocs has several ways of getting content:
-
get_doc: docs at paths like /x/y/z with the physical file being at [root]/x/y/z.[ext]. This is the "default" doc for the path.
The resulting text will be treated as a jinja template. The template will receive a dict created from all the [tokens].json files from the doc's directory up to the first level below root, and from the same starting point under the internal tree. The tokens dict will also have all the labels from the labels.json files found by crawling up the directory trees from the same point. Labels are added to the tokens dict with keys like label__[label_key].
Templates can use plural, cap and article to transform words. These functions come from the Inflect library. Let's say there is a a token in the JSON found by aggregating tokens.json files that is named elephant and is equal to the string "elephant". Examples: {{plural(elephant)}} would result in "elephants". {{cap(elephant)}} would result in "Elephant". And {{article(elephant)}} would resut in "an elephant".
Docs can be incorporated in other docs using jinja expressions like: {{ get_doc('/app/home/teams/todos/assignee#edit_assignee') }}.
This functionality is essentially the same as the more specific get_compose_doc method, below.
Paths may not have periods in them.
You may use '+' (or the config value at [filenames][plus]) to concat docs from the same path on the fly. For e.g.
/x/y/z#name+new_name+edit_name would return the doc at /x/y/z/name.xml + /x/y/z/new_name.xml + /x/y/z/edit_name.xml, with a space char joining them. If you configure a JSON root and request /x/y/z+pdq the resulting JSON dict will be the union of /x/y/z.json and /x/y/z/pdq.json.
-
get_doc: docs at paths like /x/y/z#name found as [root]/x/y/z/name.[ext]. These docs are processed in the same way as the default doc. The name separator can be configured to be a different character by adding a [hashmark] value to the config ini file under [filenames].
-
get_concat_doc: docs as concats of files for paths like /x/y/z found as [root]/x/y/z/page.concat where page.concat is a list of simple doc names to be concatenated. Simple doc names are the same as docs named by the #name path suffix. The files to be concatenated may be anywhere in the document tree. As noted above, JSON docs that are concatted will result in a single JSON dict structure that is the union of the JSON in the individual docs.
-
get_compose_doc: docs as jinja files at paths like /x/y/z/page.html that compose pages where docs are pulled in using jinja expressions like:
{{ get_doc('/app/home/teams/todos/assignee#edit_assignee') }}.
get_compose_doc requires the compose template be .xml, .html or .md. A compose doc could be referenced by a concat file, or vice versa, but the reference will only include the file contents; it will not be transformed.
-
get_labels: labels as json dicts for paths like /x/y/z found as [root]/x/y/z/labels.json. Labels are transformed in the same way as docs, except that the keys of the json dict are individual templates. A label can pull in a doc in the same way that a doc is embedded in a compose doc. Labels that pull in docs are tricky because the docs pulled in may or may not correctly handle any label replacements used with tokens.json, depending on any circular references.
-
list_docs: returns a list of simple names of docs below the docpath. This method will return [/x/y/z/a.xml, /x/y/z/b.xml] (actually ['a.xml','b.xml'] for /x/y/z but it won't include /x/y/z.xml (or, actually, the simple name 'z.xml').
Each of these retrieval methods is matched by a similarly named "..._from_roots" version that takes a List of root names. See the MultiContextDocs abstract base class.
Creating a Cdocs endpoint using Flask might look something like:
app = Flask(__name__)
api = Api(app)
@app.route('/cdocs/<path:cdocspath>')
def cdocs(cdocspath:str):
cdocs = Cdocs(PATH)
return cdocs.get_doc(cdocspath)
Flask won't have access to an anchor appended to a URL by a hashmark. (E.g. http://a.com/x/y/z#name). To work around that you can add a [filenames][hashmark] setting to the config.ini with a different character. E.g.:
[filenames]
hashmark = *
The same endpoint using all of a set of docs directory trees configured in config.ini might look like:
app = Flask(__name__)
api = Api(app)
@app.route('/cdocs/<path:cdocspath>')
def cdocs(cdocspath:str):
metadata = ContextMetaData()
context = Context(metadata)
return context.get_doc(cdocspath)
An endpoint implementation might want to search certain trees based on the locale of the request, a version name, a product name, an author, etc.
An SPA might use the endpoint to pull docs or labels for context sensitive help, UI labels, internationalization, etc. by converting its router's current route to docpath. A route like /teams/124/projects/15/todos might be converted to /teams/projects/todos to get UI labels and tooltips using something like:
getDocpathFromRoute(route) {
let parts = route.split("/")
var path = ""
for (let i = 0; i <parts.length; i++) {
if (isNaN(Number(parts[i]))) {
path += "/" + parts[i]
}
}
return path
}
TODO:
- Configure a transformer for default and #name docs. (And concat and compose?) E.g. to automatically transform xml > md, md > html, etc.
- Think about if concat and compose docs should be transformed before being included in the other type. e.g. if /x/y/z/concat.txt included /x/compose.html then compose.html would be rendered before being concatenated.



