MarkdownParser

MarkdownParser 是一个 Markdown 语法解析器,用于实现 markdown 文本到 html 文本的转换
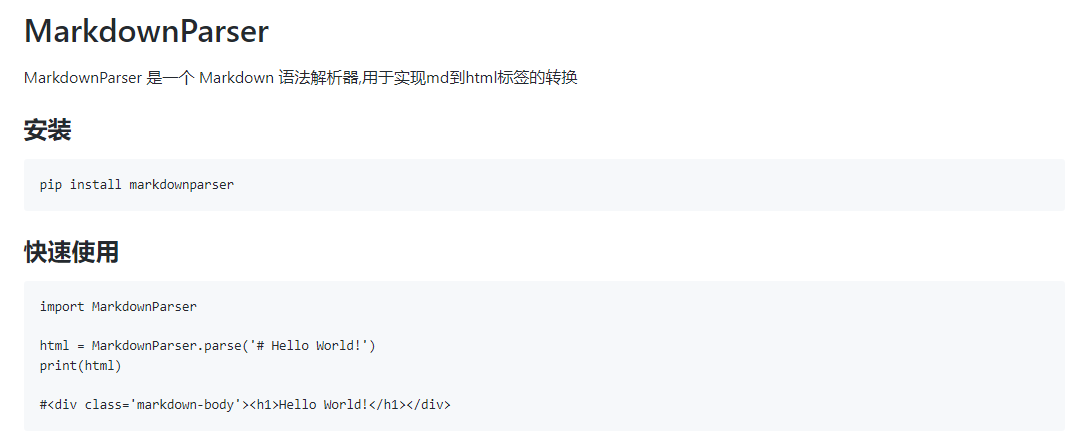
安装
pip install markdownparser
快速开始
import MarkdownParser
html = MarkdownParser.parse('# Hello World!')
print(html)
两个简单易用的接口函数
def parse(text: str, toc = False) -> str:
...
def parse_file(file_name: str, toc = False) -> str:
...
接口类 Markdown, Block
结果预览与 Markdown 功能测试
本仓库下提供了了一个快速验证转换结果的工具 generate.py, 跟一个文件名即可快速验证预览本库的转换结果是否正确
python generate.py <FILE_NAME>
运行会生成index.html, 使用浏览器打开生成的index.html即可与您预期的渲染结果对比
不支持
- 四个空格变为代码段
- [^1]的引用方式
- Setext 形式的标题
- 上标 / 下标 / 下划线
<details><summary></summary></details> 折叠块
HTML 结果说明
众所周知 Markdown 转换后的 html 文本还需要 css 美化, 本仓库下提供了一个 index.css 作为参考(Github Markdown 主题)
-
生成的结果会以 "markdown-body" 类名的一个 div 包裹
例如 <div class='markdown-body'>markdown内容</div>
-
代码段会根据语言为 pre 加入一个类名便于后期高亮,例如 class="language-cpp", 未定义语言则为 language-UNKNOWN
-
默认导出的HTML中层级任务列表会有显示问题,这是因为使用了ul+li+checkbox的方式,您需要添加以下css样式修正
.markdown-body > ul>li:has(input) {
padding-left: 0;
margin-bottom: 0;
}
.markdown-body ul>li:has(input)>ul {
list-style-type: none;
padding-left: 8px;
}
-
toc 参数用于标记跳转, 如果设置 toc=True 则会将所有标签(#)组成目录树, 除 "markdown-body" 外额外生成一个 <div class="header-navigator">...</div> 用于导航
辅助一些 js 相关的代码即可实现跳转, 具体可以参考 template.html
let links = document.querySelectorAll('div a[href^="#"]');
links.forEach(link => {
link.addEventListener('click', function(event) {
event.preventDefault();
let target = document.querySelector(this.getAttribute('href'));
target.scrollIntoView({ behavior: 'smooth' });
});
});
以及一些样式美化
.header-navigator {
position: fixed;
}
-
如果您想添加对Mermaid的支持, 您可参考mermaid plugin在您的html页面 <body> 末尾添加如下 <script>
<script type="module">
const codeBlocks = document.querySelectorAll('.language-mermaid');
codeBlocks.forEach(codeBlock => {
codeBlock.classList.remove('language-mermaid');
codeBlock.classList.add('mermaid');
});
import mermaid from 'https://cdn.jsdelivr.net/npm/mermaid@10/dist/mermaid.esm.min.mjs';
mermaid.initialize({ startOnLoad: true });
</script>
请注意, 由于本Markdown解析器的CodeBlock解析得到的类名为 language-mermaid, 而mermaid插件支持的类名格式为mermaid, 所以代码中手动修改了 language-mermaid 的类名
-
如果您想添加对Latex数学公式的支持, 可以在html页面 <body> 末尾添加如下 <script>
<script>
MathJax = {
tex: {
inlineMath: [['$', '$'], ['\\(', '\\)']]
}
};
</script>
<script id="MathJax-script" async
src="https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-chtml.js">
</script>
实现思路
Markdown解析器的代码实现
您可通过取消 core.py 注释来获取树的结构
def parse(self, text: str) -> str:
lines = self.preprocess_parser(text)
root = self.block_parser(lines)
tree = self.tree_parser(root)
return tree.toHTML()
参考



