PMAW: Pushshift Multithread API Wrapper





Contents
Description
PMAW is a wrapper for the Pushshift API which uses multithreading to retrieve Reddit comments and submissions. General usage is through the PushshiftAPI class which provides methods for interacting with different Pushshift endpoints, please view the Pushshift Docs for more details on the endpoints and accepted parameters. Parameters are provided through keyword arguments when calling the method, some methods will have required parameters. When using a method PMAW will complete all the required API calls to complete the query before returning a Response generator object.
The following three methods are currently supported:
- Searching Comments:
search_comments
- Search Submissions:
search_submissions
- Search Submission Comment IDs:
search_submission_comment_ids
Getting Started
Why Multithread?
When building large datasets from Reddit submission and comment data it can require thousands of API calls to the Pushshift API. The time it takes for your code to complete pulling all this data is limited by both your network latency and the response time of the Pushshift server, which can vary throughout the day.
Current API libraries such as PRAW and PSAW currently run requests sequentially, which can cause thousands of API calls to take many hours to complete. Since API requests are I/O-bound they can benefit from being run asynchronously using multiple threads. Implementing intelligent rate limiting can ensure that we minimize the number of rejected requests, and the time it takes to complete.
Installation
PMAW currently supports Python 3.5 or later. To install it via pip, run:
$ pip install pmaw
General Usage
from pmaw import PushshiftAPI
api = PushshiftAPI()
View the optional parameters for PushshiftAPI here.
Features
Multithreading
The number of threads to use during multithreading is set with the num_workers parameter. This is optional and defaults to 10, however, you should provide a value as this may not be appropriate for your machine. Increasing the number of threads you use allows you to make more concurrent requests to Pushshift, however, the returns are diminishing as requests are constrained by the rate-limit. The optimal number of threads for requests is between 10 and 20 depending on the current response time of the Pushshift server.
When selecting the number of threads you can follow one of the two methodologies:
- Number of processors on the machine, multiplied by 5
- Minimum value of 32 and the number of processors plus 4
If you are unsure how many processors you have use: os.cpu_count().
Rate Limiting
Multiple different options are available for rate-limiting your Pushshift API requests, and are defined by two different types, rate-averaging and exponential backoff. If you're unsure on which to use, refer to the benchmark comparison.
Rate-Averaging
PMAW by default rate limits using rate-averaging so that the concurrent API requests to the Pushshift server are limited to your provided rate.
Providing a rate_limit value is optional, this defaults to 60 requests per minute which is the recommended value for interacting with the Pushshift API. Increasing this value above 60 will increase the number of rejected requests and will increase the burden on the Pushshift server. A maximum recommended value is 100 requests per minute.
Additionally, the rate-limiting behaviour can be constrained by the max_sleep parameter which allows you to select a maximum period of time to sleep between requests.
Exponential Backoff
Exponential backoff can be used by setting the limit_type to backoff. Four flavours of backoff are available based on the usage of jitter: None, full, equal, and decorr - decorrelated.
Exponential backoff is calculated by multiplying the base_backoff by 2 to the power of the number of failed batches. This allows batches to be spaced out, reducing the resulting rate-limit when requests start to be rejected. However, the threads will still be requesting at nearly the same time, increasing the overall number of required API requests. The exponential backoff sleep values are capped by the max_sleep parameter.
Introducing an element of randomness called jitter allows us to reduce the competition between threads and distribute the API requests across the window, reducing the number of rejected requests.
full jitter selects the length of sleep for a request by randomly sampling from a normal distribution for values between 0 and the capped exponential backoff value.equal jitter selects the length of sleep for a request by adding half the capped exponential backoff value to a random sample from a normal distribution between 0 and half the capped exponential backoff value.decorr - decorrelated jitter is similar to full jitter but increases the maximum jitter based on the last random value, selecting the length of sleep by the minimum value between max_sleep and a random sample between the base_backoff and the last sleep value multiplied by 3.
Caching
Memory Safety
Memory safety allows us to reduce the amount of RAM used when requesting data, and can be enabled by setting mem_safe=True on a search method. This feature should be used if a large amount of data is being requested or if the machine in use has a limited amount of RAM.
When enabled, PMAW caches the responses retrieved every 20 batches (approx 20,000 responses with 10 workers) by default, this can be changed by passing a different value for file_checkpoint when instantiating the PushshiftAPI object.
When the search is complete, a Response generator object is returned, when iterating through the responses using this generator, responses from the cache will be loaded in 1 cache file at a time.
Safe Exiting
Safe exiting will ensure that if a search method is interrupted that any unfinished requests and current responses are cached before exiting. If the search method successfully completes, all the responses are also cached. This can be enabled by setting safe_exit=True on a search method.
Re-running a search method with the exact same parameters that you have ran before will load previous responses and any unfinished requests from the cache, allowing it to resume if all the required responses have not yet been retrieved. If there are no unfinished requests, the responses from the cache are returned.
A before value is required to load previous responses / requests when using non-id based search, as before is set to the current time when the search method is called, which would result in a different set of parameters then when you last ran the search despite all other parameters being the same.
Similarly to the memory safety feature, a Response generator object is returned. When iterating through the responses using this generator, responses from the cache will be loaded in 1 cache file at a time.
PRAW Enrichment
Enrich results with the most recent metadata from Reddit by passing a PRAW Reddit instance when instantiating the PushshiftAPI. Results not found on Reddit will not be enriched or returned.
If you don’t already have a client ID and client secret, follow Reddit’s First Steps Guide to create them. A user agent is a unique identifier that helps Reddit determine the source of network requests. To use Reddit’s API, you need a unique and descriptive user agent.
Custom Filtering
A user-defined function can be provided using the filter_fn parameter for either the search_submissions or search_comments method. This function will be used to filter results before they are saved by passing each item to the function and filtering it out if a False value is returned, saving the value if True is returned. The limit parameter does not take into account any results that are filtered out.
Unsupported Parameters
order='asc' is unsupported as it can have unexpected resultsuntil and since only support epoch time (float or int)aggs are unsupported, as PMAW is intended to be used for collecting large numbers of submissions or comments. Use PSAW for aggregation requests.
Feature Requests
- For feature requests please open an issue with the
feature request label, this will allow features to be better prioritized for future releases
Parameters
Objects
PushshiftAPI
num_workers (int, optional): Number of workers to use for multithreading, defaults to 10.max_sleep (int, optional): Maximum rate-limit sleep time (in seconds) between requests, defaults to 60s.rate_limit (int, optional): Target number of requests per minute for rate-averaging, defaults to 60 requests per minute.base_backoff (float, optional): Base delay in seconds for exponential backoff, defaults to 0.5sbatch_size (int, optional): Size of batches for multithreading, defaults to number of workers.shards_down_behavior (str, optional): Specifies how PMAW will respond if some shards are down during a query. Options are 'warn' to only emit a warning, 'stop' to throw a RuntimeError, or None to take no action. Defaults to 'warn'.limit_type (str, optional): Type of rate limiting to use, options are 'average' for rate averaging, 'backoff' for exponential backoff. Defaults to 'average'.jitter (str, optional): Jitter to use with backoff, options are None, 'full', 'equal', 'decorr'. Defaults to None.checkpoint (int, optional): Size of interval in batches to print a checkpoint with stats, defaults to 10file_checkpoint (int, optional): Size of interval in batches to cache responses when using mem_safe, defaults to 20praw (praw.Reddit, optional): Used to enrich the Pushshift items retrieved with metadata directly from Reddit
Response
Response is a generator object which will return the responses once when iterated over.
len(Response) will return the number of responses that were retrieved from Pushshiftload_cache(key, cache_dir=None) returns an instance of Response with the responses loaded with the provided key
search_submissions and search_comments
max_ids_per_request (int, optional): Maximum number of ids to use in a single request, defaults to 500, maximum 500.max_results_per_request (int, optional): Maximum number of items to return in a single non-id based request, defaults to 100, maximum 100.mem_safe (boolean, optional): If True, stores responses in cache during operation, defaults to Falsesearch_window (int, optional): Size in days for search window for submissions / comments in non-id based search, defaults to 365safe_exit (boolean, optional): If True, will safely exit if interrupted by storing current responses and requests in the cache. Will also load previous requests / responses if found in cache, defaults to Falsecache_dir (str, optional) - An absolute or relative folder path to cache responses in when mem_safe or safe_exit is enabledfilter_fn (function, optional) - A function used for custom filtering the results before saving them. Accepts a single comment or submission parameter and returns False to filter out the item, otherwise returns True.
Keyword Arguments
- Unlike the Pushshift API, the
until and since keyword arguments must be in epoch time limit is the number of submissions/comments to return. If set to None or if the set limit is higher than the number of available submissions/comments for the provided parameters then limit will be set to the amount available.- Other accepted parameters are covered in the Pushshift documentation for submissions and comments.
ids is a required parameter and should be an array of submission ids, a single id can be passed as a stringmax_ids_per_request (int, optional): Maximum number of ids to use in a single request, defaults to 500, maximum 500.mem_safe (boolean, optional): If True, stores responses in cache during operation, defaults to Falsesafe_exit (boolean, optional): If True, will safely exit if interrupted by storing current responses and requests in the cache. Will also load previous requests / responses if found in cache, defaults to Falsecache_dir (str, optional) - An absolute or relative folder path to cache responses in when mem_safe or safe_exit is enabled
Keyword Arguments
- Other accepted parameters are covered in the Pushshift documentation
Examples
The following examples are for pmaw version >= 1.0.0.
from pmaw import PushshiftAPI
api = PushshiftAPI()
comments = api.search_comments(subreddit="science", limit=1000)
comment_list = [comment for comment in comments]
from pmaw import PushshiftAPI
api = PushshiftAPI()
comment_ids = ['gjacwx5','gjad2l6','gjadatw','gjadc7w','gjadcwh',
'gjadgd7','gjadlbc','gjadnoc','gjadog1','gjadphb']
comments = api.search_comments(ids=comment_ids)
comment_list = [comment for comment in comments]
You can supply a single comment by passing the id as a string or an array with a length of 1 to ids
Detailed Example
from pmaw import PushshiftAPI
api = PushshiftAPI()
post_ids = ['kxi2w8','kxi2g1','kxhzrl','kxhyh6','kxhwh0',
'kxhv53','kxhm7b','kxhm3s','kxhg37','kxhak9']
comment_ids = api.search_submission_comment_ids(ids=post_ids)
comment_id_list = [c_id for c_id in comment_ids]
You can supply a single submission by passing the id as a string or an array with a length of 1 to ids
Detailed Example
Submissions
Search Submissions
from pmaw import PushshiftAPI
api = PushshiftAPI()
posts = api.search_submissions(subreddit="science", limit=1000)
post_list = [post for post in posts]
Search Submissions by IDs
from pmaw import PushshiftAPI
api = PushshiftAPI()
post_ids = ['kxi2w8','kxi2g1','kxhzrl','kxhyh6','kxhwh0',
'kxhv53','kxhm7b','kxhm3s','kxhg37','kxhak9']
posts = api.search_submissions(ids=post_ids)
post_list = [post for post in posts]
You can supply a single submission by passing the id as a string or an array with a length of 1 to ids
Detailed Example
Advanced Examples
PRAW
import praw
from pmaw import PushshiftAPI
reddit = praw.Reddit(
client_id='YOUR_CLIENT_ID',
client_secret='YOUR_CLIENT_SECRET',
user_agent=f'python: PMAW request enrichment (by u/YOUR_USERNAME)'
)
api_praw = PushshiftAPI(praw=reddit)
comments = api_praw.search_comments(q="quantum", subreddit="science", limit=100, until=1629990795)
Custom Filter
The user defined function must accept a single item (comment / submission) and return either True or False, returning False will filter out the item passed to it.
from pmaw import PushshiftAPI
api = PushshiftAPI()
def fxn(item):
return item['score'] > 2
posts = api.search_submissions(ids=post_ids, filter_fn=fxn)
Caching Examples
Memory Safety
If you are pulling large amounts of data or have a limited amount of RAM, using the memory safety feature will help you avoid an out of memory error from being thrown during data retrieval.
from pmaw import PushshiftAPI
api = PushshiftAPI()
posts = api.search_submissions(subreddit="science", limit=700000, mem_safe=True)
print(f'{len(posts)} posts retrieved from Pushshift')
A Response generator object will be returned, and you can load all the responses, including those that have been cached by iterating over the entire generator.
post_list = [post for post in posts]
With default settings, responses are cached every 20 batches (approx 20,000 responses with 10 workers), however, with limited memory you can decrease this further.
api = PushshiftAPI(file_checkpoint=10)
Safe Exiting
If you expect that your query may be interrupted while its running, setting safe_exit=True will cache responses and unfinished requests before exiting when an interrupt signal is received. Re-running a search method with the exact same parameters that you have ran before will load previous responses and any unfinished requests from the cache, allowing it to resume if all the required responses have not yet been retrieved.
from pmaw import PushshiftAPI
api = PushshiftAPI()
posts = api.search_submissions(subreddit="science", limit=700000, until=1613234822, safe_exit=True)
print(f'{len(posts)} posts retrieved from Pushshift')
A until value is required to load previous responses / requests when using non-id search, as until is set to the current time when the search method is called, which would result in a different set of parameters then when you last ran the search despite all other parameters being the same.
Loading Cache with Key
The Response class has a staticmethod load_cache that allows you to pass a key value and cache_dir to load responses from the cache into an instance of Response.
from pmaw import Response
cache_key = 'a904e22ea572a8c0109b7bc5330528e4'
cache_dir = './cache'
resp = Response.load_cache(cache_key, cache_dir)
Benchmarks
Benchmark Notebook
PMAW and PSAW Comparison
Completion Time
A benchmark comparison was performed to determined the completion time for different size requests, ranging from 1 to 390,000 requested posts. This will allow us to determine which Pushshift wrappers and rate-limiting methods are best for different request sizes.
Default parameters were used for each PMAW rate-limit configuration as well as the default PSAW configuration, which does not provide multiple rate-limit implementations.
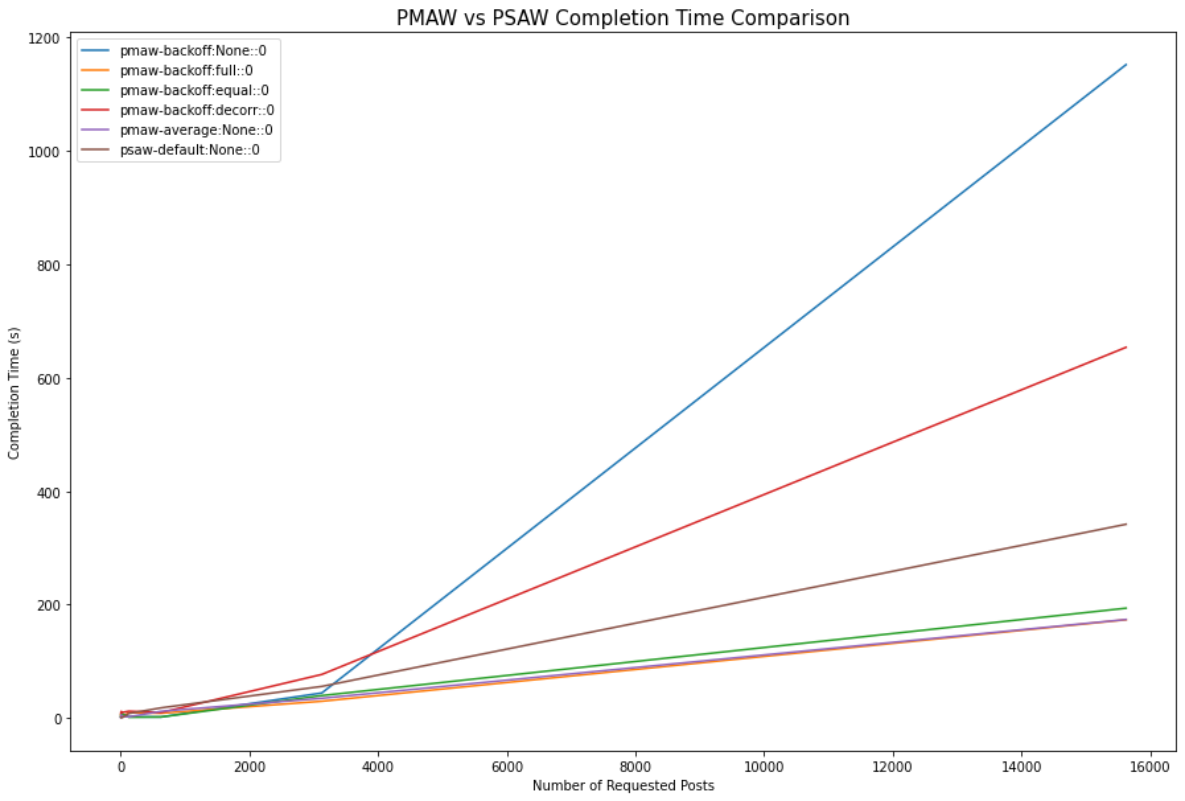
For the first benchmark test we compare the completion times for all possible PMAW rate-limiting configurations with PSAW for up to 16,000 requested posts. We can see that the three most performant rate-limiting settings for PMAW are rate-averaging, and exponential backoff with full or equal jitter.
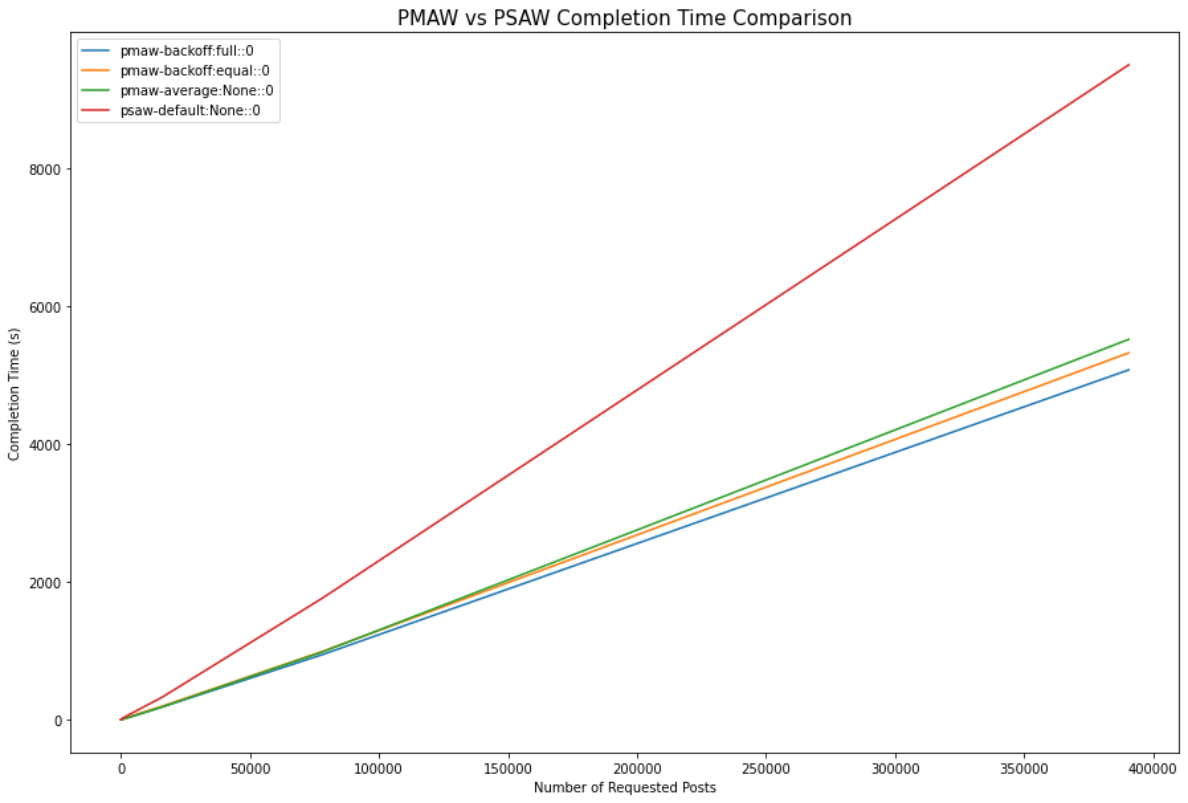
We ran this second benchmark increasing up to 390,000 requested posts, excluding the least performant PMAW rate-limiting configurations. From this benchmark, we can see that PMAW was on average 1.79x faster than PSAW at 390,625 posts retrieved. The total completion time for 390,625 posts with PSAW was 2h38m, while the average completion time was 1h28m for PMAW.
Number of Requests
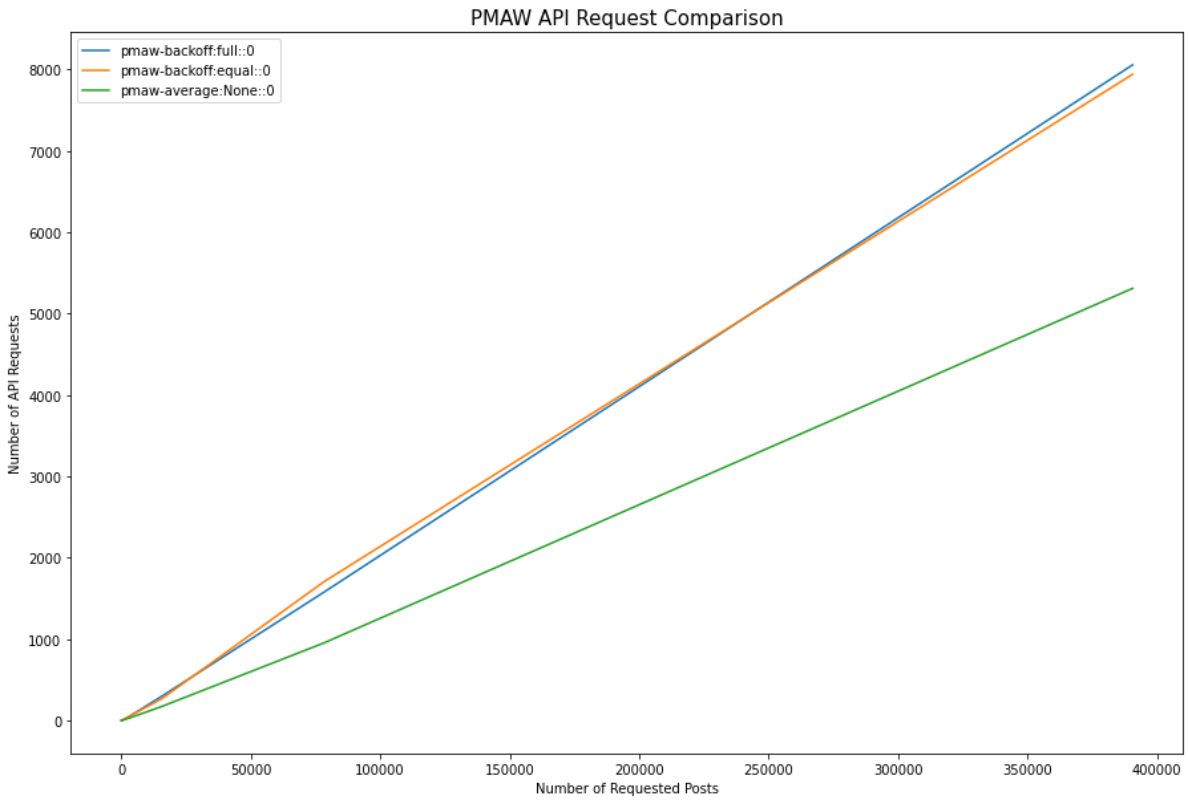
We also compare the number of required requests for each of the three PMAW rate-limit configurations. From this comparison, we can see that for 390,625 requested posts rate-averaging made 33.60% less API requests than exponential backoff.
Memory Safety (Cache)
A benchmark test was performed for the memory safety feature (mem_safe=True) to see the impact of caching responses has on the completion time, memory use, and max memory use while running requests for different limits.
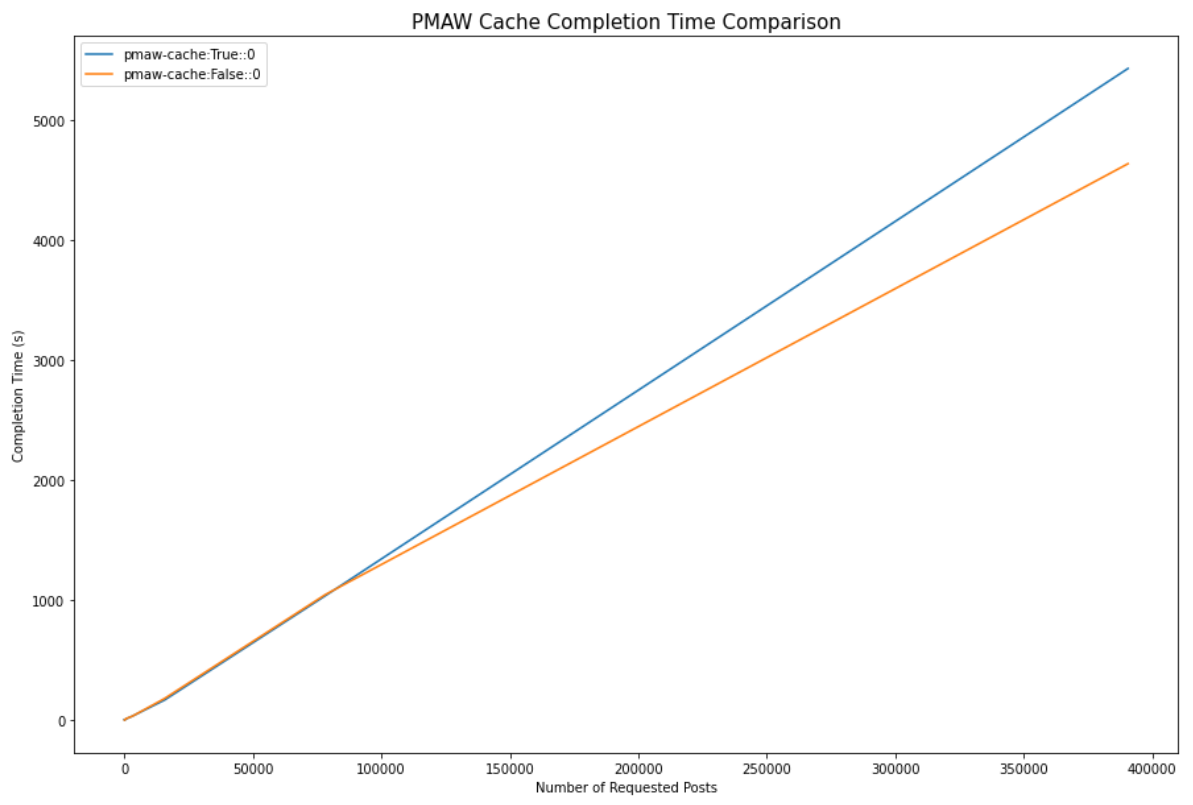
We can see that when memory safety was enabled, the completion time for 390,000 posts was 17.11% slower than when this feature was disabled and responses were not being cached, finishing in 1h30m instead of 1h17m.
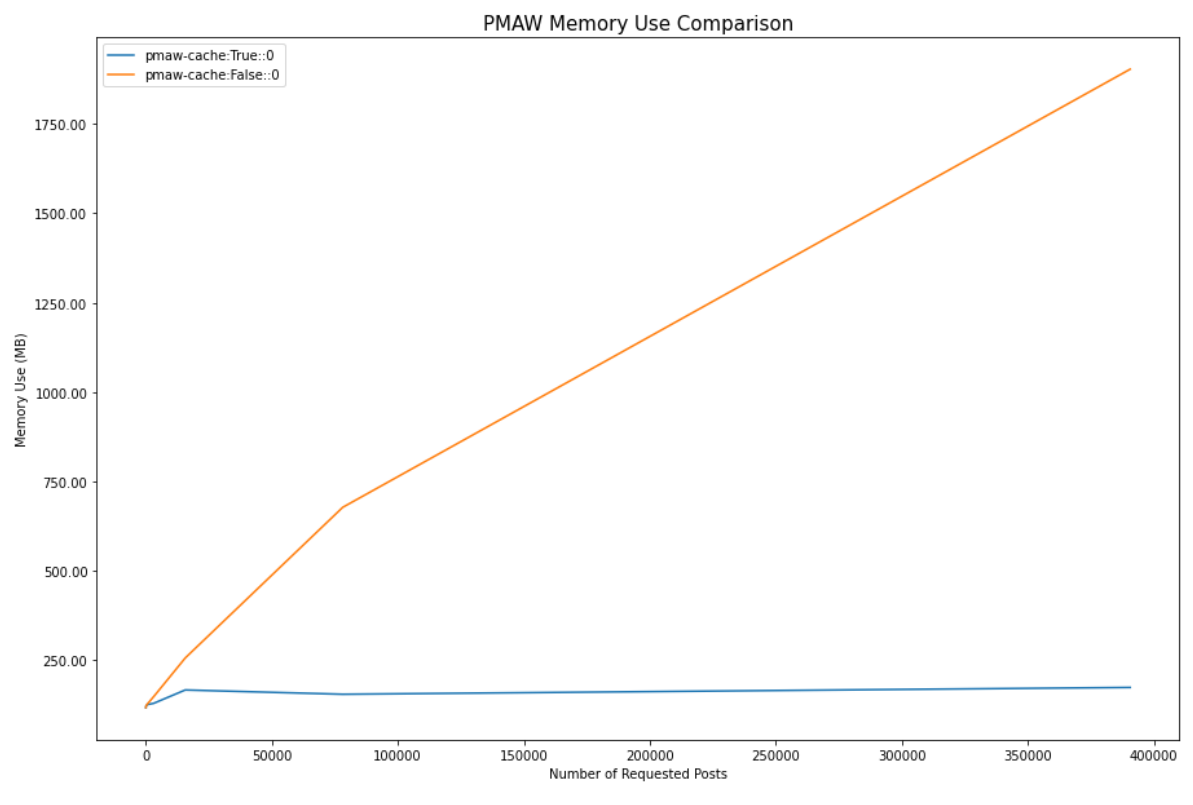
When memory safety is enabled responses start being cached after 20 checkpoints (default file_checkpoint=20), equivalent to approximately 20,000 responses, causing the memory use to level out around 170MB of memory. Enabling memory safety allows us to use 90.97% less memory is used than when it is disabled, with the non-cached responses using 1.9GB of memory when 390,000 posts were retrieved. It's clear to see that we could easily trigger an out of memory error if we were to retrieve millions of submissions with memory safety disabled.
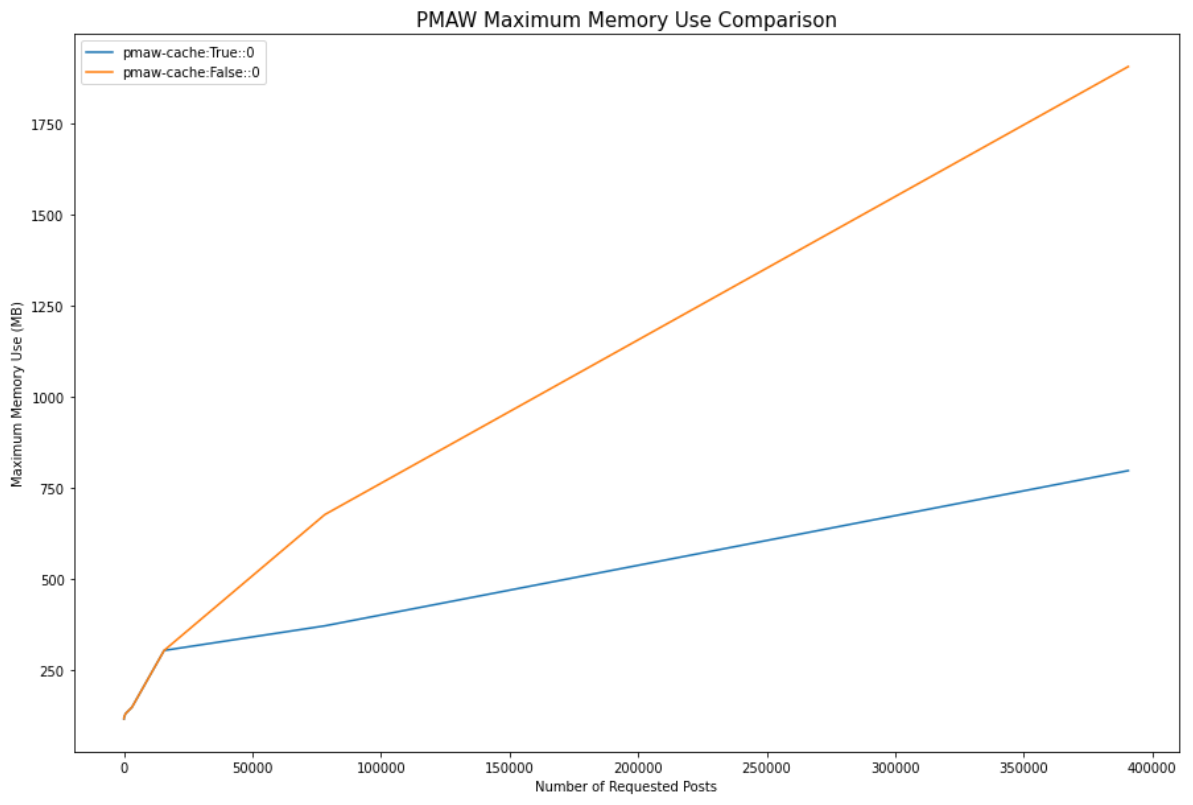
We compare the maximum memory use during data retrieval as well. Once again, around the 20,000 response mark, the two methods diverge as responses begin to be added to the cache. For 390,000 posts, the maximum memory use when memory safety was enabled was 58.2% less than when it was disabled (797MB vs 1.9GB).
Deprecated Examples
These examples are for pmaw version <=0.1.3.
comments = api.search_comments(subreddit="science", limit=1000)
comment_ids = ['gjacwx5','gjad2l6','gjadatw','gjadc7w','gjadcwh',
'gjadgd7','gjadlbc','gjadnoc','gjadog1','gjadphb']
comments_arr = api.search_comments(ids=comment_ids)
post_ids = ['kxi2w8','kxi2g1','kxhzrl','kxhyh6','kxhwh0',
'kxhv53','kxhm7b','kxhm3s','kxhg37','kxhak9']
comment_id_dict = api.search_submission_comment_ids(ids=post_ids)
Submissions
Search Submissions
submissions = api.search_submissions(subreddit="science", limit=1000)
Search Submissions by IDs
post_ids = ['kxi2w8','kxi2g1','kxhzrl','kxhyh6','kxhwh0',
'kxhv53','kxhm7b','kxhm3s','kxhg37','kxhak9']
posts_arr = api.search_submissions(ids=post_ids)
License
PMAW is released under the MIT License. See the
LICENSE file for more
details.



