TreeProfiler Overview
TreeProfiler is a command line tool designed to automate the annotation of large phylogenetic trees using a wide array of data sources. It also facilitates the visual exploration of these annotations as phylogenetic profiles, making it a powerful resource for researchers working with complex biological data.
Key Features:
- Automated Annotation that integrates diverse metadata into phylogenetic trees, and summarizes annotation in internal nodes, including:
- Categorical/Numerical metadata in TSV/CSV format
- Taxonomic Annotation of NCBI/GTDB taxonomy database
- Functional Annotation from eggnog-mapper output
- Domain annotation from pfam/smart
- Multiple Sequence Alignment annotation
- Visual Exploration that allows for the detailed examination of annotated trees, aiding in the interpretation and presentation of data.
- Analytic Methods for computing analysis from leaf nodes:
- Ancestral Character Reconstruction
- Phylogenetic Signal Delta Statistic]
- Lineage Specificity Analysis
The official documentation of TreeProfiler is in https://dengzq1234.github.io/TreeProfiler/ where provides detailed instructions with examples.
If you have any doubts, please drop a line in issue or contact https://x.com/deng_ziqi
Full manuscript of TreeProfiler is in https://doi.org/10.1101/2023.09.21.558621
If you use TreeProfiler, please cite:
Ziqi Deng, Ana Hernández-Plaza, Jaime Huerta-Cepas.
"TreeProfiler: A command-line tool for computing and visualizing phylogenetic profiles against large trees"
bioRxiv (2023) doi: 10.1101/2023.09.21.558621
Table of Contents
Introduction
TreeProfiler is command-line tool for profiling metadata table into phylogenetic tree with descriptive analysis and output visualization
Installation
Dependencies
TreeProfiler requires
- Python version >= 3.9
- ETE Toolkit v4
- biopython
- selenium
- scipy
- matplotlib
- numba
- pastml (custom)
Quick install via pip
# Install ETE Toolkit v4
pip install --force-reinstall https://github.com/etetoolkit/ete/archive/ete4.zip
# Install TreeProfiler dependencies
pip install biopython selenium scipy matplotlib numba
# Install custom pastml package for ete4
pip install "git+https://github.com/dengzq1234/pastml.git@pastml2ete4"
# Install TreeProfiler tool via pip
pip install TreeProfiler
# or installing main repo
pip install https://github.com/compgenomicslab/TreeProfiler/archive/main.zip
# or development mode for latestest update
pip install git+https://github.com/compgenomicslab/TreeProfiler@dev-repo
Quick Start with examples dataset
TreeProfiler provide various example dataset for testing in examples/ or https://github.com/compgenomicslab/TreeProfiler/tree/main/examples,
each directory consists a demo script *_demo.sh for quick starting different functions in TreeProfiler which alreadyh as annotate-plot pipeline of example data. User can fast explore different example tree with different visualizations. Here is the demonstration:
# execute demo script of example1
cd examples/basic_example1/
sh ./example1_demo.sh
Annotate example tree with two metadata tables
start parsing...
Time for parse_csv to run: 0.001968860626220703
Time for load_metadata_to_tree to run: 0.0003094673156738281
Time for merge annotations to run: 0.05160331726074219
Time for annotate_taxa to run: 4.76837158203125e-07
Visualize properties categorical data random_type in rectangle_layout, numerical data sample1, sample2 in heatmap_layout and barplot_layout.
Current trees in memory: 0
Added tree example with id 0.
* Serving Flask app 'ete4.smartview.gui.server' (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
As the session starts in local server http://127.0.0.1:5000, annotated tree and selected properties are visualized at the interactive session.
 Here is detailed introduction of interactive session of visualization(here)
Here is detailed introduction of interactive session of visualization(here)
Check other tutorial scripts
# display demo script of each example
./examples/basic_example1/example1_demo.sh
./examples/automatic_query/highlight_demo.sh
./examples/automatic_query/collapse_demo.sh
./examples/automatic_query/prune_demo.sh
./examples/basic_example2/example2_demo.sh
./examples/taxonomy_example/ncbi/ncbi_demo.sh
./examples/taxonomy_example/gtdb/gtdb_demo.sh
./examples/pratical_example/progenome3/progenome_demo.sh
./examples/pratical_example/gtdb_r202/gtdbv202full_demo.sh
./examples/pratical_example/gtdb_r202/gtdbv202lite_demo.sh
./examples/pratical_example/emapper/emapper_demo.sh
Manual installation
Install ETE v4
Quick way
pip install https://github.com/etetoolkit/ete/archive/ete4.zip
For local development
To install ETE in a local directory to help with the development, you can:
- Clone this repository (git clone https://github.com/etetoolkit/ete.git)
- Install dependecies
- If you are using conda:
conda install -c conda-forge cython bottle brotli numpy pyqt - Otherwise, you can install them with
pip install <dependencies> - Build and install ete4 from the repository's root directory:
pip install -e .
(In Linux there may be some cases where the gcc library must be installed, which can be done with conda install -c conda-forge gcc_linux-64)
Install TreeProfiler
Install dependencies
# install BioPython, selenium, scipy via conda
conda install -c conda-forge biopython selenium scipy matplotlib
# or pip
pip install biopython selenium scipy matplotlib
Install TreeProfiler
# install TreeProfiler
git clone https://github.com/compgenomicslab/TreeProfiler
cd TreeProfiler/
python setup.py install
Or
# install directly
pip install https://github.com/dengzq1234/TreeProfiler/archive/refs/tags/v1.1.0.tar.gz
Input files
TreeProfiler takes following file types as input
| Input | Filetype |
|---|
| Tree | newick, ete |
| Metadata | tar.gz, tsv |
- ete format is a novel format developed to solve the situation we encounter in the previous step, annotated tree can be recover easily with all the annotated data without changing the data type. Besides, the ete format optimized the tree file size after mapped with its associated data. Hence it's very handy for programers in their own script. At this moment we can only view the ete format in treeprofiler, but we will make the ete format more universal to other phylogenetic software.
- Metadata input could be single or multiple files, either tar.gz compressed file(s) which contains multiple .tsv or plain .tsv file(s).
Basic Usage
TreeProfiler has two main subcommand:
The first one annotate is used to annotate your input tree and corresponding metadata, TreeProfiler will map all the metadata into corresponding tree node. In this step, annotated tree will be generated in newick and ete format
treeprofiler annotate --tree tree.nw --input-type newick --metadata metadata.tsv --outdir ./
The second subcommand plot is used to visualize tree with associated metadata. By default, treeprofiler will launch an interactive session at localhost for user to explore input tree.
treeprofiler plot --tree tree_annotated.nw --input-type newick
or
treeprofiler plot --tree tree_annotated.ete --input-type ete
Using TreeProfiler
In this Tutorial we will use TreeProfiler and demostrate basic usage with data in examples/
tree examples/
examples/
├── automatic_query
│ ├── basic_example1_metadata1.tsv
│ ├── basic_example1.nw
│ ├── collapse_demo.sh
│ ├── highlight_demo.sh
│ └── prune_demo.sh
├── basic_example1
│ ├── basic_example1_metadata1.tsv
│ ├── basic_example1_metadata2.tsv
│ ├── basic_example1.nw
│ └── example1_demo.sh
├── basic_example2
│ ├── diauxic.array
│ ├── diauxic.nw
│ ├── example2_demo.sh
│ ├── FluA_H3_AA.fas
│ ├── MCC_FluA_H3_Genotype.txt
│ └── MCC_FluA_H3.nw
├── pratical_example
│ ├── emapper
│ │ ├── 7955.ENSDARP00000116736.aln.faa
│ │ ├── 7955.ENSDARP00000116736.nw
│ │ ├── 7955.out.emapper.annotations
│ │ ├── 7955.out.emapper.pfam
│ │ ├── 7955.out.emapper.smart.out
│ │ ├── emapper_demo.sh
│ │ ├── nifH.faa.aln
│ │ ├── nifH.nw
│ │ ├── nifH.out.emapper.annotations
│ │ └── nifH.out.emapper.pfam
│ ├── gtdb_r202
│ │ ├── ar122_metadata_r202_lite.tar.gz
│ │ ├── bac120_metadata_r202_lite.tar.gz
│ │ ├── gtdbv202full_demo.sh
│ │ ├── gtdbv202lite_demo.sh
│ │ ├── gtdbv202.nw
│ │ ├── merge_gtdbtree.py
│ │ └── progenome3.tar.gz
│ └── progenome3
│ ├── progenome3.nw
│ ├── progenome3.tsv
│ └── progenome_demo.sh
└── taxonomy_example
├── gtdb
│ ├── gtdb_demo.sh
│ ├── gtdb_example1.nw
│ └── gtdb_example1.tsv
└── ncbi
├── ncbi_demo.sh
├── ncbi_example.nw
└── ncbi_example.tsv
Parsing Input tree
Tree format
TreeProfiler accpept input tree in .nw or .ete by putting --input-type {newick,ete} flag to identify. By default, TreeProfiler will automatically detech the format of tree. The difference between .nw and .ete:
-
newick format is more universal and be able to used in different other phylogenetic software although associated data of tree nodes will be considered as plain text.
-
ete format is a novel format developed to solve the situation we encounter in the previous step, annotated tree can be recover easily with all the annotated data without changing the data type. Besides, the ete format optimized the tree file size after mapped with its associated data. Hence it's very handy for programers in their own script. At this moment we can only view the ete format in treeprofiler, but we will make the ete format more universal to other phylogenetic software. Hence using ete format in plot subcommand is highly reccomended
Tree parser
TreeProfiler provides argument --internal {name,support} to specify newick tree when it include values in internal node. [default: name]
| newick | leaves | internal_node value | internal_parser |
|---|
| (A:0.5, B:0.5)Internal_C:0.5; | A, B | Internal_C | name |
| (A:0.5, B:0.5)0.99:0.5; | A, B | 0.99 | support |
annotate, Annotate metadata into tree
TreeProfiler annotate subcommand is the step that annotate input metadata to target tree. As a result, itwill generate the following output file:
<input_tree> + _annotated.nw, newick format with annotated tree<input_tree> + _annotated.ete, ete format with annotated tree<input_tree> + _annotated_prop2type.txt, config file where store the datatype of each annotated properties<input_tree> + _annotated.tsv, metadata in tab-separated values format with annotated and summarized internal nodes information.
In the following sub session we will describe the usage of following arguments in annotate step for metadata:
| Argument | Description |
|---|
-d, --metadata METADATA [METADATA ...] | <metadata.csv> .csv, .tsv filename |
-sep, --metadata-sep METADATA_SEP | Column separator of metadata table [default: \t] |
--data-matrix DATA_MATRIX [DATA_MATRIX ...] | <datamatrix.csv> .csv, .tsv. Numerical matrix data metadata table as array to tree, please do not provide column headers in this file, filename will become the property name in the tree. |
--no-headers | Metadata table doesn't contain columns name, namespace col+index will be assigned as the key of property such as col1. |
--duplicate | Treeprofiler will aggregate duplicated metadata to a list as a property if metadata contains duplicated row. |
Basic Metadata in TSV/CSV Format
TreeProfiler allows users to input metadata in tsv/csv file by setting --metadata <filename.tsv|.csv> and -s <seperator>. By default, the first column of metadata should be names of target tree leaves and metadata should contain column names for each column of metadata.
TreeProfiler allows user to annotate more than one metadata inputs to tree such as --metadata table1.tsv table2.tsv.
Check metadata
cd examples/basic_example0/
tree ./
./
├── boolean.tsv
├── categorical_duplicated.tsv
├── categorical.tsv
├── data.array
├── demo1.tree
├── numerical.tsv
└── show_tree_props.py
# check metadata structure
head categorical.tsv
name,categorical1
Taxa_0,A
Taxa_1,B
Taxa_2,B
Taxa_3,C
Run annotate subcommand
## annotate tree with more than one metadata tsv, seperated by `,`
# set the correct filename and seperator
treeprofiler annotate \
-t demo1.tree \
--metadata categorical.tsv \
-sep , \
-o .
After annotation, treeprofiler will generate annotated tree
ls demo1*
demo1_annotated.ete demo1_annotated.nw demo1_annotated.tsv demo1_prop2type.txt demo1.tree
Now we can check annotated tree
# show tree's properties
python show_tree_props.py demo1_annotated.nw
Target tree internal node Root contains the following properties:
{'categorical1_counter': 'A--1||B--2||C--2', 'name': 'Root'}
Target tree leaf node Taxa_0 contains the following propertiies:
{'name': 'Taxa_0', 'dist': 0.190563, 'categorical1': 'A'}
Metadata TSV/CSV as a Numerical Data Matrix
treeprofiler can handle the whole tsv/csv file as one property and annotate it to related leaves, by using --data-matrix <filename.tsv|.csv> It must be numerical data matrix and without headers. Once annotated the property of data-matrix will be named by the filename (see example below)
The difference between --data-matrix and --metadata is that the former sees the whole metadata file as a node property and stores the rows as an array in leaf nodes, and the latter sees each column from metadata as each single property of leaf nodes.
Using data array file data.array from the previous example
# annotated data.array file to tree
treeprofiler annotate \
-t demo1.tree \
--data-matrix data.array \
-sep , \
-o .
# data.array is stored as one property in tree node and value is stored as array
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{
'data.array_avg': '1.0244|-0.667|-1.7740000000000002|-0.8620000000000001|-0.6552',
'data.array_max': '3.671|1.937|4.362|1.585|2.746',
'data.array_min': '-2.591|-2.356|-4.825|-3.326|-2.479',
'data.array_std': '2.3121192529798287|1.5156064132880938|3.524138873540599|1.9937640783202009|1.906460531980665',
'data.array_sum': '5.122|-3.335|-8.870000000000001|-4.3100000000000005|-3.276',
'name': 'Root'
}
target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_0',
'dist': 0.190563,
'data.array': '-2.591|1.937|-3.898|0.447|-1.349'
}
Metadata Without Column Names
If metadata doesn’t have headers, by setting --no-headers to set the metadata properly, therefore treeprofiler will name each column by col+<column number> as the property key in each leaf node, such as col1, col2, etc.
example
# data.array doesn't have headers for each column
head data.array
Taxa_0,-2.591,1.937,-3.898,0.447,-1.349
Taxa_1,3.366,-1.871,4.362,1.585,-2.479
Taxa_2,0,-0.098,0,-3.326,2.746
Taxa_3,3.671,-0.947,-4.509,-3.131,-2.194
# need to add --no-headers flag to tell treeprofiler
treeprofiler annotate \
-t demo1.tree \
--metadata data.array \
-sep , \
--no-headers \
-o .
# check properties
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{'col1_avg': '1.92825',
'col1_max': '3.671',
'col1_min': '0.0',
'col1_std': '3.463526916666666',
'col1_sum': '7.713',
'col2_avg': '-1.318',
...}
target tree leaf node Taxa_0 contains the following propertiies:
{'name': 'Taxa_0',
'dist': 0.190563,
'col1': '-2.591',
'col2': '1.937',
'col3': '-3.898',
'col4': '0.447',
'col5': '-1.349'}
Missing Value Detection
Metadata column which fullfills one of the following criterias will be consider as missing value:
- Entirely symbolic characters. Such as
+, -, ~, ., etc. - The exact strings
none, None, null, Null, or NaN. - An empty string (zero characters).
Missing value will replaced by string 'NaN' in the corresponding property.
Unmapped Tree Leaf Property Detection
If Metadata doesn't cover input tree leaf, tree leaf will be unannotated.
Handling Duplicated Leaf Names in Metadata
In general, treeprofiler expects each row of metadata corresponding to one leaf, such as
head categorical.tsv
#name,categorical1
Taxa_0,A
Taxa_1,B
Taxa_2,B
Taxa_3,C
Taxa_4,C
Although treeprofiler can handle metadata with rows with duplicated leafnames such as
head categorical_duplicated.tsv
#name,categorical1
Taxa_0,A
Taxa_0,B
Taxa_2,B
Taxa_2,C
Taxa_3,C
Taxa_3,A
Taxa_4,C
In order to do so, users need to add --duplicate , by doing so, metadata from the same leaf will be aggregate into the same column. Such as the Taxa_0 from the above table, at the end value A and B will be both annotated to property categorical1(see above demo). If not, treeprofielr will take one the first row of metadata that appear as the metadata for related leaf!
example
treeprofiler annotate \
-t demo1.tree \
-d categorical_duplicated.tsv \
-sep , \
--duplicate \
-o .
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{'categorical1_counter': 'A--2||B--2||C--3', 'name': 'Root'}
target tree leaf node Taxa_0 contains the following propertiies:
{'name': 'Taxa_0', 'dist': 0.190563, 'categorical1': 'A|B'}
Specifying Data Types for Metadata Columns
Although TreeProfiler can automatically detect datatype of each column, users still can determine the datatype using the following arguments using:
| Argument | Description |
|---|
--text-prop TEXT_PROP [TEXT_PROP ...] | names of columns which need to be read as categorical data |
--multiple-text-prop MULTIPLE_TEXT_PROP [MULTIPLE_TEXT_PROP ...] | names of columns which need to be read as categorical data containing more than one value and separated by , such as GO:0000003,GO:0000902,GO:0000904,GO:0003006 |
--num-prop NUM_PROP [NUM_PROP ...] | names of columns which need to be read as numerical data |
--bool-prop BOOL_PROP [BOOL_PROP ...] | names of columns which need to be read as boolean data |
--text-prop-idx TEXT_PROP_IDX [TEXT_PROP_IDX ...] | 1 2 3 or [1-5] index of columns which need to be read as categorical data |
--num-prop-idx NUM_PROP_IDX [NUM_PROP_IDX ...] | 1 2 3 or [1-5] index columns which need to be read as numerical data |
--bool-prop-idx BOOL_PROP_IDX [BOOL_PROP_IDX ...] | 1 2 3 or [1-5] index columns which need to be read as boolean data |
Annotate Metadata to Internal Nodes
At the above example, we only mapped metadata to leaf nodes, in this example, we will also profile internal nodes annotation and analysis of their children nodes. Argument that in related to summary methods are:
| Argument | Applied datatype | Description | Summarized properties Internal node |
|---|
--num-stat {all,sum,avg,max,min,std,none} | numerical data matrix | Descriptive Statistic (average, sum, max, min, standard deviation) | <prop name>_avg
<prop name>_sum
<prop name>_max
<prop name>_min
<prop name>_std |
--counter-stat {raw,relative,none} | str
boolean
list | Raw/Relative Counter | <prop name>_counter |
--num-stat {all,sum,avg,max,min,std,none} | float
int | Descriptive Statistic (average, sum, max, min, standard deviation) | <prop name>_avg
<prop name>_sum
<prop name>_max
<prop name>_min
<prop name>_std |
--column-summary-method COLUMN_SUMMARY_METHOD [COLUMN_SUMMARY_METHOD ...] | all | Specify summary method for individual columns in the format ColumnName=Method, such as --column-summary-method sample1=none sample2=avg random_type=relative alignment=none | |
TreeProfiler can infer automatically the datatype of each column in your metadata, including
list (seperate by , )string (categorcial data)numerical(numerical data, float or integer)booleans
Internal node will summurize children nodes information according to their datatypes.
demo tree
╭╴A
╴root╶┤
│ ╭╴B
╰╴D╶┤
╰╴C
demo metadata
| #name | text_property | multiple_text_property | numerical_property | bool_property |
|---|
| A | vowel | a,b,c | 10 | True |
| B | consonant | b,c,d | 4 | False |
| C | consonant | c,d,e | 9 | True |
Treeprofiler will infer the datatypes of above metadata and adpot different summary method:
| - | text_property | multiple_text_property | numerical_property | bool_property |
|---|
| datatype | string | list | float | bool |
| method | counter | counter | average,sum,max,min,standard deviation | counter |
boolean and text properties (categorical data) of leaf nodes will be summarized as counters in internal nodes, currently users can choose using raw (default), relative or none for counter. Users can use --counter-stat {raw,relative,none} to choose the counter, it will automatically apply to all categorical properties.
After annotation, internal nodes will be summarized. If property was summarize with counter, in internal node will be named as <property_name>_counter
Users can choose either counter is raw or relative count by using --counter-stat
| internal_node properties | statistic method |
|---|
<prop name>_counter | raw(default), relative |
| internal_node | text_property_counter | multiple_text_property_counter | bool_property_counter |
|---|
| D | consonant--2 | b--1||c--2||d--2||e--1 | True--1||False--1 |
| root | vowel--1||consonant--2 | a--2||b--2||c--3||d--2||e--1 | True--2||False--1 |
Example
# raw counter (default)
treeprofiler annotate \
-t demo1.tree \
--metadata categorical.tsv \
-sep , \
--counter-stat raw \
-o ./
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{
'categorical1_counter': 'A--1||B--2||C--2',
'name': 'Root'
}
target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_0',
'dist': 0.190563,
'categorical1': 'A'
}
#relative counter to calculate the percentage
treeprofiler annotate \
-t demo1.tree \
--metadata categorical.tsv \
-sep , \
--counter-stat relative \
-o ./
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{
'categorical1_counter': 'A--0.20||B--0.40||C--0.40',
'name': 'Root'
}
target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_0',
'dist': 0.190563,
'categorical1': 'A'
}
#set to none
treeprofiler annotate \
-t demo1.tree \
--metadata categorical.tsv \
-sep , \
--counter-stat none \
-o ./
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{'name': 'Root'}
target tree leaf node Taxa_0 contains the following propertiies:
{'name': 'Taxa_0', 'dist': 0.190563, 'categorical1': 'A'}
By default, numerical feature will be calculated all the descriptive statistic, but users can choose specific one to be calculated by using --num-stat {all, sum, avg, max, min, std, none}. all (default) means it will conduct all the statistic. none means annotation will only conduct in leaf nodes.
If property was numerical data, in internal node will be named as
| internal_node properties | statistic method |
|---|
<prop name>_avg | average |
<prop name>_sum | sum |
<prop name>_max | maximum |
<prop name>_min | minimum |
<prop name>_std | standard deviation |
Noticed that --num-stat will also work on --data-matrix data.
In our demo, it would be:
| internal_node | numerical_property_avg | numerical_property_sum | numerical_property_max | numerical_property_max | numerical_property_max |
|---|
| D | 6.5 | 13 | 9 | 4 | 2.5 |
| root | 7.67 | 23 | 10 | 4 | 2.32 |
Example:
# conduct all statistic (by default)
treeprofiler annotate \
-t demo1.tree \
--metadata numerical.tsv \
-sep , \
--num-stat all \
-o ./
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{
'name': 'Root',
'random_column1_avg': '0.5384554640742852',
'random_column1_max': '0.7817176831389784',
'random_column1_min': '0.3276816717486982',
'random_column1_std': '0.028430041000376213',
'random_column1_sum': '2.692277320371426',
....
}
target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_0',
'dist': 0.190563,
'random_column1': '0.45303222603186877',
'random_column2': '1.9801547427961053',
'random_column3': '43.0'}
# conduct only average
treeprofiler annotate \
-t demo1.tree \
--metadata numerical.tsv \
-sep , \
--num-stat avg \
-o ./
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{
'name': 'Root',
'random_column1_avg': '0.5384554640742852',
'random_column2_avg': '0.12655333321138568',
'random_column3_avg': '52.2'
}
target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_0',
'dist': 0.190563,
'random_column1': '0.45303222603186877',
'random_column2': '1.9801547427961053',
'random_column3': '43.0'}
# conduct none statistic
treeprofiler annotate \
-t demo1.tree \
--metadata numerical.tsv \
-sep , \
--num-stat none \
-o ./
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{'name': 'Root'}
target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_0',
'dist': 0.190563,
'random_column1': '0.45303222603186877',
'random_column2': '1.9801547427961053',
'random_column3': '43.0'
}
# data matrix is also effected by --num-stat setting
# only average
treeprofiler annotate \
-t demo1.tree \
--data-matrix data.array \
-sep , \
--num-stat avg \
-o ./
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{
'data.array_avg': '1.0244|-0.667|-1.7740000000000002|-0.8620000000000001|-0.6552',
'name': 'Root'
}
target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_0',
'dist': 0.190563,
'data.array': '-2.591|1.937|-3.898|0.447|-1.349'
}
Customizing Summary Methods for Different Columns
Using --column-summary-method can specify the summary method of each properties, simply add <property name>=<summary method> . For categorical data, options are raw,relative,none; for numerical data, options are all, sum, avg, max, min, std, none .
such as --column-summary-method sample1=none sample2=avg random_type=relative alignment=none
Noted that --data-matrix can be effected by --column-summary-method setting, in this case filename of the data matrix is property name, such as--data-matrix file.tsv --column-summary-method file.tsv=avg
example:
here we use three different metadata: categorical tsv, numerical tsv and data matrix
# cusomtize different summary methods for different column/property
treeprofiler annotate \
-t demo1.tree \
--metadata categorical.tsv numerical.tsv \
--data-matrix data.array \
-sep , \
--column-summary-method \
categorical1=relative \
random_column1=all \
random_column2=none \
random_column3=sum \
data.array=avg \
-o ./
python show_tree_props.py demo1_annotated.nw
target tree internal node Root contains the following properties:
{
'name': 'Root',
'categorical1_counter': 'A--0.20||B--0.40||C--0.40',
'random_column1_avg': '0.5384554640742852',
'random_column1_max': '0.7817176831389784',
'random_column1_min': '0.3276816717486982',
'random_column1_std': '0.028430041000376213',
'random_column1_sum': '2.692277320371426',
'random_column3_sum': '261.0',
'data.array_avg': '1.0244|-0.667|-1.7740000000000002|-0.8620000000000001|-0.6552'
}
target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_0',
'dist': 0.190563,
'categorical1': 'A',
'random_column1': '0.45303222603186877',
'random_column2': '1.9801547427961053',
'random_column3': '43.0',
'data.array': '-2.591|1.937|-3.898|0.447|-1.349'
}
Taxonomic annotation
If input metadada containcs taxon data, TreeProfiler allows users to process taxonomic annotation with either GTDB or NCBI database.
| Argument | Description |
|---|
--taxon-column TAXON_COLUMN | Choose the column in metadata which represents taxon for activating the taxonomic annotation. Default is the first column, which should be the column of leaf_name. |
--taxadb {NCBI,GTDB,customdb} | NCBI or GTDB, choose the Taxonomic Database for annotation. |
--taxon-delimiter TAXON_DELIMITER | Delimiter of taxa columns. [default: None]· |
--taxa-field TAXA_FIELD | Field of taxa name after delimiter. [default: 0] |
--taxa-dump TAXA_DUMP | Path to taxonomic database dump file for a specific version, such as GTDB taxadump (https://github.com/etetoolkit/ete-data/raw/main/gtdb_taxonomy/gtdblatest/gtdb_latest_dump.tar.gz) or NCBI taxadump (https://ftp.ncbi.nlm.nih.gov/pub/taxonomy/taxdump.tar.gz). |
--gtdb-version {95,202,207,214,220} | GTDB version for taxonomic annotation, such as 220. If it is not provided, the latest version will be used. |
--ignore-unclassified | Ignore unclassified taxa in taxonomic annotation. |
In this part we will demostrate the usage of taxonomic annotation in examples of examples/taxonomy_example
cd examples/taxonomy_example
ls ./
demo3.tree demo4.tree gtdb202dump.tar.gz missing_gtdb_v202.tree ncbi.tree
demo3.tsv demo4.tsv gtdb_v202.tree missing_ncbi.tree show_tree_props.py
Using Different Taxonomic Databases from GTDB/NCBI
To start taxonomic annotation, using --taxon-column and --taxadb to locate where is the taxon and which taxonomic databases to be used. If taxon is leaf name, then using --taxon-column name , otherwise --taxon-column <prop_name> which refers to the column in the metadata.
# check example tree
cat ncbi.tree
((9606, 9598), 10090);
# run taxonomic annotation and locate taxon column in leaf name
treeprofiler annotate \
-t ncbi.tree \
--taxon-column name \
--taxadb ncbi \
-o ./
# check annotation results
python show_tree_props.py ncbi_annotated.nw
Target tree internal node Root contains the following properties:
{
'common_name': '',
'evoltype': 'S',
'lca': 'no rank-cellular organisms|superkingdom-Eukaryota|clade-Eumetazoa|phylum-Chordata|superclass-Sarcopterygii|kingdom-Metazoa|class-Mammalia|subphylum-Craniata|superorder-Euarchontoglires',
'lineage': '1|131567|2759|33154|33208|6072|33213|33511|7711|89593|7742|7776|117570|117571|8287|1338369|32523|32524|40674|32525|9347|1437010|314146',
'name': 'Root',
'named_lineage': 'root|Eukaryota|Eumetazoa|Chordata|Vertebrata|Gnathostomata|Sarcopterygii|Eutheria|Tetrapoda|Amniota|Theria|Opisthokonta|Metazoa|Bilateria|Deuterostomia|Mammalia|Craniata|Teleostomi|Euteleostomi|cellular organisms|Euarchontoglires|Dipnotetrapodomorpha|Boreoeutheria', 'rank': 'superorder',
'sci_name': 'Euarchontoglires',
'species': '10090|9606|9598',
'taxid': '314146'
}
Target tree leaf node Taxa_0 contains the following propertiies:
{
'name': '9606',
'dist': 1.0,
'common_name':
'Homo sapiens',
'lca': 'no rank-cellular organisms|superkingdom-Eukaryota|clade-Eumetazoa|phylum-Chordata|superclass-Sarcopterygii|order-Primates|parvorder-Catarrhini|family-Hominidae|genus-Homo|species-Homo sapiens|kingdom-Metazoa|class-Mammalia|subphylum-Craniata|subfamily-Homininae|superorder-Euarchontoglires|infraorder-Simiiformes|superfamily-Hominoidea|suborder-Haplorrhini',
'lineage': '1|131567|2759|33154|33208|6072|33213|33511|7711|89593|7742|7776|117570|117571|8287|1338369|32523|32524|40674|32525|9347|1437010|314146|9443|376913|314293|9526|314295|9604|207598|9605|9606',
'named_lineage': 'root|Eukaryota|Eumetazoa|Chordata|Vertebrata|Gnathostomata|Sarcopterygii|Eutheria|Primates|Catarrhini|Hominidae|Homo|Homo sapiens|Tetrapoda|Amniota|Theria|Opisthokonta|Metazoa|Bilateria|Deuterostomia|Mammalia|Craniata|Teleostomi|Euteleostomi|cellular organisms|Homininae|Euarchontoglires|Simiiformes|Hominoidea|Haplorrhini|Dipnotetrapodomorpha|Boreoeutheria',
'rank': 'species',
'sci_name': 'Homo sapiens',
'species': '9606',
'taxid': '9606'
}
For gtdb taxa, users can choose --gtdb-version {95,202,207,214,220} to select certain version, if not, latest gtdb db will be used.
# check example tree
cat gtdb_v202.tree
(GB_GCA_011358815.1:1,(RS_GCF_000019605.1:1,(RS_GCF_003948265.1:1,GB_GCA_003344655.1:1):0.5):0.5);
# default using latest version, in this case on tree from version 202, it should go empty
treeprofiler annotate \
-t gtdb_v202.tree \
--taxon-column name \
--taxadb gtdb \
-o ./
python show_tree_props.py gtdb_v202_annotated.nw
Target tree internal node Root contains the following properties:
{
'common_name': '',
'evoltype': 'S',
'lca': '', 'lineage': '',
'name': 'Root',
'named_lineage': '',
'rank': 'Unknown',
'sci_name': 'None',
'species': 'RS_GCF_000019605.1|RS_GCF_003948265.1|GB_GCA_011358815.1|GB_GCA_003344655.1',
'taxid': 'None'
}
Target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'GB_GCA_011358815.1',
'dist': 1.0,
'common_name': '',
'named_lineage': '',
'rank': 'Unknown',
'sci_name': '',
'species': 'GB_GCA_011358815.1',
'taxid': 'GB_GCA_011358815.1'
}
#annotate tree using the proper version of GTDB
treeprofiler annotate \
-t gtdb_v202.tree \
--taxon-column name \
--taxadb gtdb \
--gtdb-version 202 \
-o ./
# now it's correctly annotated
python show_tree_props.py gtdb_v202_annotated.nw
Target tree internal node Root contains the following properties:
{
'common_name': '',
'evoltype': 'S',
'lca': 'superkingdom-d__Archaea|phylum-p__Thermoproteota|class-c__Korarchaeia|order-o__Korarchaeales|family-f__Korarchaeaceae|genus-g__Korarchaeum',
'lineage': '1|2|79|2172|2173|2174|2175', 'name': 'Root',
'named_lineage': 'root|d__Archaea|p__Thermoproteota|c__Korarchaeia|o__Korarchaeales|f__Korarchaeaceae|g__Korarchaeum',
'rank': 'genus', 'sci_name': 'g__Korarchaeum',
'species': 'RS_GCF_003948265.1|GB_GCA_011358815.1|RS_GCF_000019605.1|GB_GCA_003344655.1',
'taxid': 'g__Korarchaeum'
}
Target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'GB_GCA_011358815.1',
'dist': 1.0,
'common_name': '',
'lca': 'superkingdom-d__Archaea|phylum-p__Thermoproteota|class-c__Korarchaeia|order-o__Korarchaeales|family-f__Korarchaeaceae|genus-g__Korarchaeum|species-s__Korarchaeum cryptofilum|subspecies-s__Korarchaeum cryptofilum',
'named_lineage': 'root|d__Archaea|p__Thermoproteota|c__Korarchaeia|o__Korarchaeales|f__Korarchaeaceae|g__Korarchaeum|s__Korarchaeum cryptofilum|GB_GCA_011358815.1',
'rank': 'subspecies',
'sci_name': 's__Korarchaeum cryptofilum',
'species': 'GB_GCA_011358815.1',
'taxid': 'GB_GCA_011358815.1'
}
Identifying Taxon Names in Different Metadata Fields/Columns
When Taxon properties are embeded in different column or field in metadata, treeprofiler provides --taxon-column, --taxon-delimiter and --taxa-field to identify taxon term in order to process taxonomic annotation sucessfully. Here is summary of different cases with corresponding setting.
| metadata | taxon to be identified | command line setting |
|---|
#leafname col1
9598 wt | 9598 | default |
#leafname col1
7739.XP_002609184.1 wt | 7739 | --taxon-column <default> --taxon-delimiter . --taxa-field 0 |
#leafname ncbi_id
leaf_A 7739 | 7739 | --taxon-column ncbi_id --taxon-delimiter <default> --taxa-field <default> |
#leafname ncbi_id
leaf_A 7739.XP_002609184.1 | 7739 | --taxon-column ncbi_id --taxon-delimiter . --taxa-field 0 |
#leafname col1
RS_GCF_001560035.1 wt | RS_GCF_001560035.1 | default |
#leafname gtdb_id
leaf_A d__Archaea;p__Asgardarchaeota;c__Heimdallarchaeia;o__UBA460;f__Kariarchaeaceae;g__LC-2;s__LC-2 sp001940725 | s__LC-2 sp001940725 | --taxon-column gtdb_id --taxon-delimiter ; --taxa-field -1 |
examples:
# check example tree and metadata
cat demo3.tree
(Taxa_2:0.471596,((Taxa_0:0.767844,Taxa_1:0.792161)0.313833:0.684109,Taxa_3:0.805286):0.188666);
cat demo3.tsv
#name gtdb_taxid
Taxa_0 GB_GCA_011358815.1@sample1
Taxa_1 RS_GCF_000019605.1@sample2
Taxa_2 RS_GCF_003948265.1@sample3
Taxa_3 GB_GCA_003344655.1@sample4
# therefore, locate taxa id correctly
treeprofiler annotate \
-t demo3.tree \
-d demo3.tsv \
--taxon-column gtdb_taxid \
--taxadb gtdb \
--gtdb-version 202 \
--taxon-delimiter @ \
--taxa-field 0 \
-o ./
python show_tree_props.py demo3_annotated.nw
Target tree internal node Root contains the following properties:
{
'common_name': '',
'evoltype': 'S',
'lca': 'superkingdom-d__Archaea|phylum-p__Thermoproteota|class-c__Korarchaeia|order-o__Korarchaeales|family-f__Korarchaeaceae|genus-g__Korarchaeum',
'name': 'Root',
'named_lineage': 'root|d__Archaea|p__Thermoproteota|c__Korarchaeia|o__Korarchaeales|f__Korarchaeaceae|g__Korarchaeum',
'rank': 'genus',
'sci_name': 'g__Korarchaeum',
'species': 'Taxa_3|Taxa_0|Taxa_1|Taxa_2',
'taxid': 'g__Korarchaeum'
}
Target tree leaf node contains the following propertiies:
{
'name': 'Taxa_2',
'dist': 0.471596,
'common_name': '',
'gtdb_taxid': 'RS_GCF_003948265.1',
'lca': 'superkingdom-d__Archaea|phylum-p__Thermoproteota|class-c__Korarchaeia|order-o__Korarchaeales|family-f__Korarchaeaceae|genus-g__Korarchaeum|species-s__Korarchaeum cryptofilum|subspecies-s__Korarchaeum cryptofilum',
'named_lineage': 'root|d__Archaea|p__Thermoproteota|c__Korarchaeia|o__Korarchaeales|f__Korarchaeaceae|g__Korarchaeum|s__Korarchaeum cryptofilum|RS_GCF_003948265.1',
'rank': 'subspecies',
'sci_name': 's__Korarchaeum cryptofilum',
'species': 'Taxa_2',
'taxid': 'RS_GCF_003948265.1'
}
Ignoring Unclassified Taxonomic Annotations
Taxonomic annotation will annotate the internal nodes based on the taxa of leaf nodes, but if leaf node has unknown taxonomic information, the internal nodes will return unknown annotation. Using --ignore-unclassified to ignore the unknown annotation from leaves
# check tree with unknown taxa
(Taxa_1:1,(RS_GCF_000019605.1:1,(Taxa_2:1,GB_GCA_003344655.1:1):0.5):0.5);
# normal way to annotate tree will cause unknown annotation
treeprofiler annotate \
-t missing_gtdb_v202.tree \
--taxon-column name \
--taxadb gtdb \
--gtdb-version 202 \
-o ./
python show_tree_props.py missing_gtdb_v202_annotated.nw
Target tree internal node Root contains the following properties:
{
'common_name': '',
'evoltype': 'S',
'lca': '',
'name': 'Root',
'named_lineage': '',
'rank': 'Unknown',
'sci_name': 'None',
'species': 'Taxa_2|GB_GCA_003344655.1|RS_GCF_000019605.1|Taxa_1',
'taxid': 'None'
}
Target tree leaf node contains the following propertiies:
{
'name': 'Taxa_1',
'dist': 1.0,
'common_name': '',
'named_lineage': '',
'rank': 'Unknown',
'sci_name': '',
'species': 'Taxa_1',
'taxid': 'Taxa_1'
}
# now adding --ignore-unclassified
treeprofiler annotate \
-t missing_gtdb_v202.tree \
--taxon-column name \
--taxadb gtdb \
--gtdb-version 202 \
--ignore-unclassified \
-o ./
python show_tree_props.py missing_gtdb_v202_annotated.nw
Target tree internal node Root contains the following properties:
{
'common_name': '',
'evoltype': 'S',
'lca': 'superkingdom-d__Archaea|phylum-p__Thermoproteota|class-c__Korarchaeia|order-o__Korarchaeales|family-f__Korarchaeaceae|genus-g__Korarchaeum',
'name': 'Root',
'named_lineage': 'root|d__Archaea|p__Thermoproteota|c__Korarchaeia|o__Korarchaeales|f__Korarchaeaceae|g__Korarchaeum',
'rank': 'genus',
'sci_name': 'g__Korarchaeum',
'species': 'Taxa_1|RS_GCF_000019605.1|GB_GCA_003344655.1|Taxa_2',
'taxid': 'g__Korarchaeum'
}
Target tree leaf node contains the following propertiies:
{
'name': 'Taxa_1',
'dist': 1.0,
'common_name': '',
'named_lineage': '',
'rank': 'Unknown',
'sci_name': '',
'species': 'Taxa_1',
'taxid': 'Taxa_1'
}
Functional Annotation
we use example in examples/pratical_example/emapper
Annotating Multiple Sequence Alignments
treeprofiler will can anntotate msa to tree and automatically calculate the consesus sequence in the internal node (fixed threshold 0.7), alignment will stored in nodes with property name alignment. Using --column-summary-method alignment=none can switch off the function for calculating consensus sequence for internal nodes.
# annotate alignment
treeprofiler annotate --tree nifH.nw --alignment nifH.faa.aln
# mute consensus sequence
treeprofiler annotate \
--tree nifH.nw \
--alignment nifH.faa.aln \
--column-summary-method alignment=none \
-o ./
Annotating EggNOG-Mapper Output and Domain information
EggNOG-mapper, is a tool for fast functional annotation of novel sequences. It uses precomputed orthologous groups and phylogenies from the eggNOG database (http://eggnog5.embl.de) to transfer functional information from fine-grained orthologs only.
| Argument | Description |
|---|
--emapper-annotations EMAPPER_ANNOTATIONS | Attach eggNOG-mapper output out.emapper.annotations |
--emapper-pfam EMAPPER_PFAM | Attach eggNOG-mapper pfam output out.emapper.pfams |
--emapper-smart EMAPPER_SMART | Attach eggNOG-mapper smart output out.emapper.smart |
--alignment ALIGNMENT | Sequence alignment, .fasta format |
It generates three kind of ouput file,
- Raw standard output,
*.out.emapper.annotations, that contains functional annotations and prthology predictions, for example:
## Mon Feb 27 09:05:50 2023
## emapper-2.1.9
## /data/shared/home/emapper/miniconda3/envs/eggnog-mapper-2.1/bin/emapper.py --cpu 20 --mp_start_method forkserver --data_dir /dev/shm/ -o out --output_dir /emapper_web_jobs/emapper_jobs/user_data/MM_knn6rw6j --temp_dir /emapper_web_jobs/emapper_jobs/user_data/MM_knn6rw6j --override -m diamond --dmnd_ignore_warnings --dmnd_algo ctg -i /emapper_web_jobs/emapper_jobs/user_data/MM_knn6rw6j/queries.fasta --evalue 0.001 --score 60 --pident 40 --query_cover 20 --subject_cover 20 --itype proteins --tax_scope auto --target_orthologs all --go_evidence non-electronic --pfam_realign denovo --num_servers 2 --report_orthologs --decorate_gff yes --excel
##
#query seed_ortholog evalue score eggNOG_OGs max_annot_lvl COG_category Description Preferred_name GOs EC KEGG_ko KEGG_Pathway KEGG_Module KEGG_Reaction KEGG_rclass BRITE KEGG_TC CAZy BiGG_Reaction PFAMs
....
## 272 queries scanned
## Total time (seconds): 45.73449420928955
## Rate: 5.95 q/s
- Pfam domain annotations,
*.out.emapper.pfam, for example:
## Mon Feb 27 09:05:52 2023
## emapper-2.1.9
## /data/shared/home/emapper/miniconda3/envs/eggnog-mapper-2.1/bin/emapper.py --cpu 20 --mp_start_method forkserver --data_dir /dev/shm/ -o out --output_dir /emapper_web_jobs/emapper_jobs/user_data/MM_knn6rw6j --temp_dir /emapper_web_jobs/emapper_jobs/user_data/MM_knn6rw6j --override -m diamond --dmnd_ignore_warnings --dmnd_algo ctg -i /emapper_web_jobs/emapper_jobs/user_data/MM_knn6rw6j/queries.fasta --evalue 0.001 --score 60 --pident 40 --query_cover 20 --subject_cover 20 --itype proteins --tax_scope auto --target_orthologs all --go_evidence non-electronic --pfam_realign denovo --num_servers 2 --report_orthologs --decorate_gff yes --excel
##
# query_name hit evalue sum_score query_length hmmfrom hmmto seqfrom seqto query_coverage
...
## 272 queries scanned
## Total time (seconds): 28.74908423423767
## Rate: 9.46 q/s
- SMART domain annotation,
*.out.emapper.smart.out, for example:
10020.ENSDORP00000023664 MAGE_N 10 63 220000.115599899
10020.ENSDORP00000023664 PTN 44 128 683.160049964146
10020.ENSDORP00000023664 Ephrin_rec_like 73 117 248282.169266432
10020.ENSDORP00000023664 PreSET 87 186 494.036044144428
....
TreeProfiler allows users annotate EggNOG-mapper standard output to target tree with following arguments
--emapper-annotations, attach eggNOG-mapper output out.emapper.annotations.--emapper-pfam, attach eggNOG-mapper pfam output out.emapper.pfams.--emapper-smart, attach eggNOG-mapper smart output out.emapper.smart.
emapper annotation output and the summary method
Field datatype summary method
seed_ortholog str counter
evalue float descriptive stat
score float descriptive stat
eggNOG_OGs list counter
max_annot_lvl str counter
COG_category str counter
Description str counter
Preferred_name str counter
GOs list counter
EC str counter
KEGG_ko list counter
KEGG_Pathway list counter
KEGG_Module list counter
KEGG_Reaction list counter
KEGG_rclass list counter
BRITE list counter
KEGG_TC list counter
CAZy list counter
BiGG_Reaction list counter
PFAMs list counter
check EggNOG-mapper annotation example
Analytical Methods in TreeProfiler
we use examples in examples/analytic_example
Ancestral Character Reconstruction
| Argument | Description |
|---|
--acr-discrete-columns ACR_DISCRETE_COLUMNS [ACR_DISCRETE_COLUMNS ...] | names of columns to perform acr analysis for discrete traits |
--prediction-method {MPPA,MAP,JOINT,DOWNPASS,ACCTRAN,DELTRAN,COPY,ALL,ML,MP} | Prediction method for ACR discrete analysis. Options: MPPA, MAP, JOINT, DOWNPASS, ACCTRAN, DELTRAN, COPY, ALL, ML, MP. [Default: MPPA] |
--model {JC, F81, EFT, HKY, JTT} | Evolutionary model for ML methods in ACR discrete analysis. Options: JC, F81, EFT, HKY, JTT. [Default: F81] |
--threads THREADS | Number of threads to use for annotation. [Default: 4] ` |
example
ls
Albanian.tree.152tax.nwk metadata_tab.csv
# check metadata
head metadata_tab.csv
id Country
98CMAJ6932 Africa
98CMAJ6933 Africa
96CMAJ6134 Africa
00SEAY5240 WestEurope
97CDAF6240 Africa
97CDAF6238 Africa
# quick running using all default setting
treeprofiler annotate \
-t Albanian.tree.152tax_annotated.nw \
--internal-parser name \
--acr-discrete-columns Country \
-o ./
# check properties
python show_tree_props.py Albanian.tree.152tax_annotated.nw
Target tree internal node Root contains the following properties:
{
'name': 'ROOT',
'dist': 0.0,
'Country': 'Africa',
'Country_counter': 'Africa--50||Albania--31||EastEurope--10||Greece--39||WestEurope--22'
}
Target tree leaf node 97CDAF6238 contains the following propertiies:
{
'name': '97CDAF6238',
'dist': 0.08034,
'Country': 'Africa'
}
# check output files
head marginal_probabilities.character_Country.model_F81.tab
node Africa Albania EastEurope Greece WestEurope
ROOT 0.9462054466377042 0.0019142742715016286 0.011256165797407233 0.013434856612985015 0.027189256680401872
node_1 0.9497450729621073 0.00018867741670758483 0.00048818236055906636 0.001324183303131325 0.04825388395749479
node_2 0.9752818930521312 0.00048506476303705997 0.015213913144468159 0.0034043477773810613 0.0056147812629824085
node_3 0.9473989345272481 0.0002801019197914036 0.0005949760547048478 0.001965821926394849 0.04976016557186095
node_4 0.9384942099527859 0.0002164578877048098 0.00043984526187224396 0.00151915289715353 0.05933033400048369
00CZAY4286 0.0 0.0 1.0 0.0 0.0
node_5 0.9999517018762923 9.117741186968884e-07 3.0195194146220156e-05 6.458698485629717e-06 1.0732456957024559e-05
97CDAF6238 1.0 0.0 0.0 0.0 0.0
94CYAF6237 0.0 0.0 0.0 0.0 1.0
# check output files
head params.character_Country.method_MPPA.model_F81.tab
parameter value
pastml_version 1.9.42
character Country
log_likelihood -118.96060539505257
log_likelihood_restricted_JOINT -123.17363108674806
log_likelihood_restricted_MAP -123.3244296265415
log_likelihood_restricted_MPPA -120.52779174042388
num_scenarios 96
num_states_per_node_avg 1.023102310231023
num_unresolved_nodes 6
--acr-discrete-columns <PROP> allow users to calculate the ancestral character state construction via pastml package. Hence the internal node will be infered the state based on the children leaf node metadata. Users can choose the prediction method using --prediction-method <METHOD>. It will generate the output config file from PASTML package as
params.character_{prop}.method_{method}.model_{model}.tab which contains information of likelihood from different model/method.
MAXIMUM LIKELIHOOD (ML) METHODS
ML approaches are based on probabilistic models of character evolution along tree branches. From a theoretical standpoint, ML methods have some optimality guaranty [Zhang and Nei, 1997, Gascuel and Steel, 2014], at least in the absence of model violation. Noted that running this ML method will generate output file as marginal_probabilities.character_{prop}.model_{model}.tab which contain the calculated propabilities of each character in every internal nodes. Instead MP method won’t generate it because it doesn’t compute the marginal propabilities
We provide three ML methods: maximum a posteriori (MAP), Joint, and marginal posterior probabilities approximation (MPPA, recommended):
-
MAP (maximum a posteriori) computes the marginal posterior probabilities of every state for each of the tree nodes, based on the information from the whole tree, i.e. tip states and branch lengths (obtained via two tree traversals: bottom-up, and then top-down). MAP then chooses a state with the highest posterior probability for each node, independently from one node to another. This could induce globally inconsistent scenarios (typically: two very close nodes with incompatible predictions).
-
JOINT
While MAP chooses predicted states based on all possible scenarios, Joint method [Pupko et al., 2000] reconstructs the states of the scenario with the highest likelihood.
-
MPPA(default),
MAP and Joint methods choose one state per node and do not reflect the fact that with real data and large trees, billions of scenarios may have similar posterior probabilities. Based on the marginal posterior probabilities, MPPA (marginal posterior probabilities approximation) chooses for every node a subset of likely states that minimizes the prediction error measured by the Brier score. It therefore sometimes keeps multiple state predictions per node but only when they have similar and high probabilities. Note however that the states not kept by MPPA might still be significant despite being less probable -- to check marginal probabilities of each state on a node consult the output marginal probabilities file (can be downloaded via the button below each compressed visualisation).
-
ML
all the ML methods for ML
Character evolution models (only in ML methods)
We provide some models of character evolution that differ in the way the equilibrium frequencies of states are calculated: JC, F81 (recommended), and EFT (estimate-from-tips, not recommended). Using --prediction-method <model> to set up.
-
JC
With JC model [Jukes and Cantor, 1969] all frequencies, and therefore rates of changes from state i to state j (i ≠ j) are equal.
-
F81 (recommended)
With F81 model [Felsenstein, 1981], the rate of changes from i to j (i ≠ j) is proportional to the equilibrium frequency of j. The equilibrium frequencies are optimised.
-
EFT
With EFT (estimate-from-tips) model, the equilibrium frequencies are calculated based on the tip state proportions, the rate of changes from i to j (i ≠ j) is proportional to the equilibrium frequency of j.
MAXIMUM PARSIMONY (MP) METHODS
MP methods aim to minimize the number of state changes in the tree. They are very quick but not very accurate, e.g. they do not take into account branch lengths. We provide three MP methods: DOWNPASS, ACCTRAN, and DELTRAN.
-
DOWNPASS
DOWNPASS [Maddison and Maddison, 2003] performs two tree traversals: bottom-up and top-down, at the end of which it calculates the most parsimonious states of ancestral nodes based on the information from the whole tree. However some of the nodes might be not completely resolved due to multiple parsimonious solutions.
-
DELTRAN
DELTRAN (delayed transformation) [Swofford and Maddison, 1987] reduces the number of node state ambiguities by making the changes as close to the tips as possible, hence prioritizing parallel mutations.
-
ACCTRAN
ACCTRAN (accelerated transformation) [Farris, 1970] reduces the number of node state ambiguities by forcing the state changes to be performed as close to the root as possible, and therefore prioritises the reverse mutations.
-
MP
all the MP methods for MP
examples:
# using different model
treeprofiler annotate \
-t Albanian.tree.152tax.nwk \
--internal-parser name \
--metadata metadata_tab.csv \
--acr-discrete-columns Country \
--prediction-method MPPA \
--model JC \
--threads 6 \
-o ./
python show_tree_props.py Albanian.tree.152tax_annotated.nw
Target tree internal node Root contains the following properties:
{
'name': 'ROOT',
'dist': 0.0,
'Country': 'Africa',
'Country_counter': 'Africa--50||Albania--31||EastEurope--10||Greece--39||WestEurope--22'
}
Target tree leaf node Taxa_0 contains the following propertiies:
{
'name': '97CDAF6238',
'dist': 0.08034,
'Country': 'Africa'
}
# using MP methods (no calculation of ancestral propababilities)
treeprofiler annotate \
-t Albanian.tree.152tax.nwk \
--internal-parser name \
--metadata metadata_tab.csv \
--acr-discrete-columns Country \
--prediction-method DOWNPASS \
--threads 6 \
-o ./
python show_tree_props.py Albanian.tree.152tax_annotated.nw
Target tree internal node Root contains the following properties:
{
'name': 'ROOT',
'dist': 0.0,
'Country': 'Africa',
'Country_counter': 'Africa--50||Albania--31||EastEurope--10||Greece--39||WestEurope--22'
}
Target tree leaf node Taxa_0 contains the following propertiies:
{
'name': '97CDAF6238',
'dist': 0.08034,
'Country': 'Africa'
}
Phylogenetic Signal Delta Statistic
Running signal delta statistic required running Ancestral Character Reconstruction using MPPA or MP methods in order to have the ancestral character propabilities. Calculated delta statistic metric and p_value of given trait will be stored in root node as properties.
| Argument | Description |
|---|
--delta-stats | Calculate delta statistic for discrete traits in ACR analysis, ONLY for MPPA or MAP prediction method. [Default: False] |
--ent-type {LSE,SE,GINI} | Entropy method to measure the degree of phylogenetic signal between discrete trait and phylogeny. Options: LSE, SE, GINI. [Default: SE] for Shannon Entropy, other options are GINI for Gini impurity and LSE for Linear Shannon Entropy. |
--iteration ITERATION | Number of iterations for delta statistic calculation. [Default: 10000] |
--lambda0 LAMBDA0 | Rate parameter of the delta statistic calculation. [Default: 0.1] |
--se SE | Standard deviation of the delta statistic calculation. [Default: 0.5] |
--thin THIN | Keep only each xth iterate. [Default: 10] |
--burn BURN | Burned-in iterates. [Default: 100] |
Delta statistic Examples
treeprofiler annotate \
-t Albanian.tree.152tax.nwk \
--internal-parser name \
--metadata metadata_tab.csv \
# acr to obtain propabilities
--acr-discrete-columns Country \
--prediction-method MPPA \
--model F81 \
# delta statistic
--delta-stats \
--ent-type SE \
--iteration 10000 \
--lambda0 0.1 \
--se 0.5 \
--thin 10 \
--burn 100 \
-o ./
# delta metric and p_val stored in root node
python show_tree_props.py Albanian.tree.152tax_annotated.nw
Target tree internal node Root contains the following properties:
{
'name': 'ROOT',
'dist': 0.0,
'Country': 'Africa',
'Country_counter': 'Africa--50||Albania--31||EastEurope--10||Greece--39||WestEurope--22',
'Country_delta': '19.52340888828994',
'Country_pval': '0.0'
}
Target tree leaf node Taxa_0 contains the following propertiies:
{
'name': '97CDAF6238',
'dist': 0.08034,
'Country': 'Africa'
}
Lineage Specificity Analysis
Using --ls-columns <prop_name> to start the lineage specificity analysis, the given trait need to be boolean value such as True; False; yes; no; t; f; 1; 0; which fit the criteria in treeprofiler annotate. Calculated results will be stored in each internal nodes with suffix of _prec , _sens and _f1.
| Argument | Description |
|---|
--ls-columns LS_COLUMNS [LS_COLUMNS ...] | names of properties to perform lineage specificity analysis. |
--prec-cutoff PREC_CUTOFF | Precision cutoff for lineage specificity analysis. [Default: 0.95] |
--sens-cutoff SENS_CUTOFF | Sensitivity threshold for lineage specificity analysis. [Default: 0.95] |
Examples:
# in the example we loose the cutoff to 0.5
treeprofiler annotate \
-t demo2.tree \
-d demo2_ls.tsv \
--ls-columns profile1 \
--prec-cutoff 0.5 \
--sens-cutoff 0.5 \
-o ./
# check properties
python show_tree_props.py demo2_annotated.nw
Target tree internal node Root contains the following properties:
{
'name': 'Root',
'profile1_counter': 'False--33||True--7',
'profile1_f1': '0.2978723404255319',
'profile1_prec': '0.175',
'profile1_sens': '1.0'
}
Target tree leaf node Taxa_0 contains the following propertiies:
{
'name': 'Taxa_3',
'dist': 0.315846,
'profile1': 'False'
}
Output Formats for Annotated Trees
TreeProfiler annotate subcommand will generate the following output file
<input_tree> + _annotated.nw, newick format with annotated tree<input_tree> + _annotated.ete, ete format with annotated tree<input_tree> + _annotated_prop2type.txt, config file where store the datatype of each annotated properties<input_tree> + _annotated.tsv, metadata in tab-separated values format with annotated and summarized internal nodes information.
In the following plot step, users can use either .nw or .ete by putting --input-type [newick, ete] flag to identify. The difference between .nw and .ete format is
-
newick file is more universal and be able to used in different other phylogenetic software although associated data of tree nodes will be considered as plain text, so if you use newick format, alongside with the prop2type config file which was generated before by adding --prop2type <prop2type_file>
-
ete format is a novel format developed to solve the situation we encounter in the previous step, annotated tree can be recover easily with all the annotated data without changing the data type. Besides, the ete format optimized the tree file size after mapped with its associated data. Hence it's very handy for programers in their own script. At this moment we can only view the ete format in treeprofiler, but we will make the ete format more universal to other phylogenetic software. Hence using ete format in plot subcommand is highly reccomended
plot, Plot annotated tree with layouts
TreeProfiler provides a several of layout options for visualize features in metadata along with tree, depends on their datatype
Interactive visualization interface
TreeProfiler uses the new visualization framework implemented in ETE 4.0, which allows for the interactive exploration of huge phylogenies based on a context-based adaptive zooming strategy.

Overview of the TreeProfiler visualization interface. (A) The control panel allows users to customize visualization layout and features, and to perform text-based searches. (B) An annotated example tree, from examples/basic_example1/ after annotate, is launched with a command plot. Support values (red) and branch distance (grey) are displayed on top of branches. The properties of one of the nodes are shown on the top. The minimap (bottom right) facilitates navigation. (C) The node editor panel provides access to node-specific actions, such as creating subtrees, collapsing, pruning, rooting and more. (D) Visualized properties by order are, categorical data random_type in rectangle-layout, numerical data sample1, sample2, sample3 in heatmap-layout and sample4, sample5 in barplot-layout, categorical data random-type in profiling-layout shown as presence-absence matrix. Layouts are shown with the order as input argument order from the command line. Names of properties are shown as titles on the top of each layout. (E) Legends each layout is shown on the top right corner with the same order as the layouts.
Basic options of visualizing layouts
Selected properties of tree will be visualized at the aligned panel alongside with the tree, here is some basic parameters for layouts.
--column-width column width of each property in layout. [default: 20].--barplot-width width of total scale of barplot layout.[default: 200]--padding-x customize horizontal column padding distance of each
layout.[default: 1]--padding-y customize vertical padding distance of each layout.[default: 0]
Layouts for categorical data
Users can add the following flag to activate layouts for categorical data
--colorbranch-layout COLORBRANCH_LAYOUT
<prop1,prop2> names of properties where branches will be colored based on
different values.
--label-layout LABEL_LAYOUT
<prop1,prop2> names of properties where values will be displayed on the
aligned panel.
--rectangle-layout rectangle_layout
<prop1,prop2> names of properties where values will be label as rectangular
color block on the aligned panel.
--profiling-layout PROFILING_LAYOUT
<prop1,prop2> names of properties which need to be convert to presence-
absence profiling matrix of each value.
--categorical-matrix-layout CATEGORICAL_MATRIX_LAYOUT
<col1,col2> names, column index which need to be plot as categorical_matrix_layout for categorical columns.
example
## target column "random_type" in examples/basic_example1/basic_example1_metadata1.tsv
# List random_type feature as text in aligned panel using label_layout
treeprofiler plot --tree examples/basic_example1/basic_example1_annotated.ete --label-layout random_type
# Label random_type feature on branch with different colors in aligned panel using --colorbranch-layout
treeprofiler plot --tree examples/basic_example1/basic_example1_annotated.ete --colorbranch-layout random_type
# Label random_type feature with retangular block in aligned panel using --rectangle-layout
treeprofiler plot --tree examples/basic_example1/basic_example1_annotated.ete --rectangle-layout random_type
# Convert random_type feature into presence-absence profiling matrix using --profiling-layout
treeprofiler plot --tree examples/basic_example1/basic_example1_annotated.ete --profiling-layout random_type
# Label all feature with retangular block in aligned panel using --categorical-matrix-layout
treeprofiler plot --tree examples/basic_example2/MCC_FluA_H3_annotated.ete --categorical-matrix-layout PB2 PB1 PA HA NP NA M NS

label-layout displays the corresponding value of selected property
of each leaf and categorized with colors.

colorbranch-layout categorize values of selected property by coloring the leaf nodes.

rectangle-layout categorizes values of selected property by displaying rectangular color block alongside the corresponing leaf node.

profiling-layout convert categorical data of the selected property to presence-absence matrix.

categorical-matrix-layout convert multiple categorical properties into categorical matrix, each value will be represent in different color. In this example we use MCC_FluA_H3.tree, time-scaled phylogenetic tree of H3 influenza viruses inferred by BEAST using molecular clock model and MCC_FluA_H3_Genotype.txt, Genotype table of the H3 influenza viruses(Yu, Guangchuang et al. (2017)). 8 gene segments PB2,PB1,PA,HA,NP,NA,M,NS as properties, and virus strain trig, pdm and HuH3N2 are categorized with different colors in the matrix.
Layouts for boolean data
Users can add the following flag to activate layouts for Boolean data
---binary-layout BINARYLAYOUT
<col1,col2> names, column index or index range of columns which need to be plot as binary_layout, label shown only positive value
--revbinary-layout REVBINARYLAYOUT
<col1,col2> names, column index or index range of columns which need to be plot as revbinary_layout, label shown only negative value
## target column "bool_type", "bool_type2" in examples/basic_example1/basic_example1_metadata1.tsv
# List postive bool_type feature in aligned panel using binary_layout
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
---binary-layout bool_type
# List negative bool_type feature in aligned panel using binary_layout
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--revbinary-layout bool_type2

binary_layout displays postive value as colored block and negative value as grey block

binary_layout displays negative value as colored block and postive value as grey block
*Boolean data can be also visualized by categorical layouts, such as
# multiple columns seperated by ','
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--rectangle-layout bool_type
Layouts for Numerical data
Users can add the following flag to activate layouts for Numerical data
--heatmap-layout HEATMAP_LAYOUT
<prop1,prop2> names of numerical properties which need to be read as heatmap_layout.
--barplot-layout BARPLOT_LAYOUT
<prop1,prop2> names of numericalproperties which need to be read as barplot_layouts.
--numerical-matrix-layout NUMERICAL_MATRIX_LAYOUT
<prop1,prop2> names which need to be plot as numerical_matrix_layout for numerical values.
## target column 'sample[1-5]' feature in examples/basic_example1/basic_example1_metadata1.tsv
# visualize sample1 feature in Barplot
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--barplot-layout sample1,sample2,sample3,sample4,sample5
# visualize sample1-sample5 in Heatmap
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--heatmap-layout sample1,sample2,sample3,sample4,sample5
# visualize col1-col7 in diauxic_annotated.nw with numerical profiling
treeprofiler plot \
--tree examples/basic_example2/diauxic_annotated.ete \
--numerical-matrix-layout col1,col2,col3,col4,col5,col6,col7

barplot-layout display numerical data to barplot with scale, users can change the length of scale by using argument --barplot-width [default: 200]

heatmap-layout display numerical data to heatmap, which will automatically scale the minimum and maximum value from white to red.
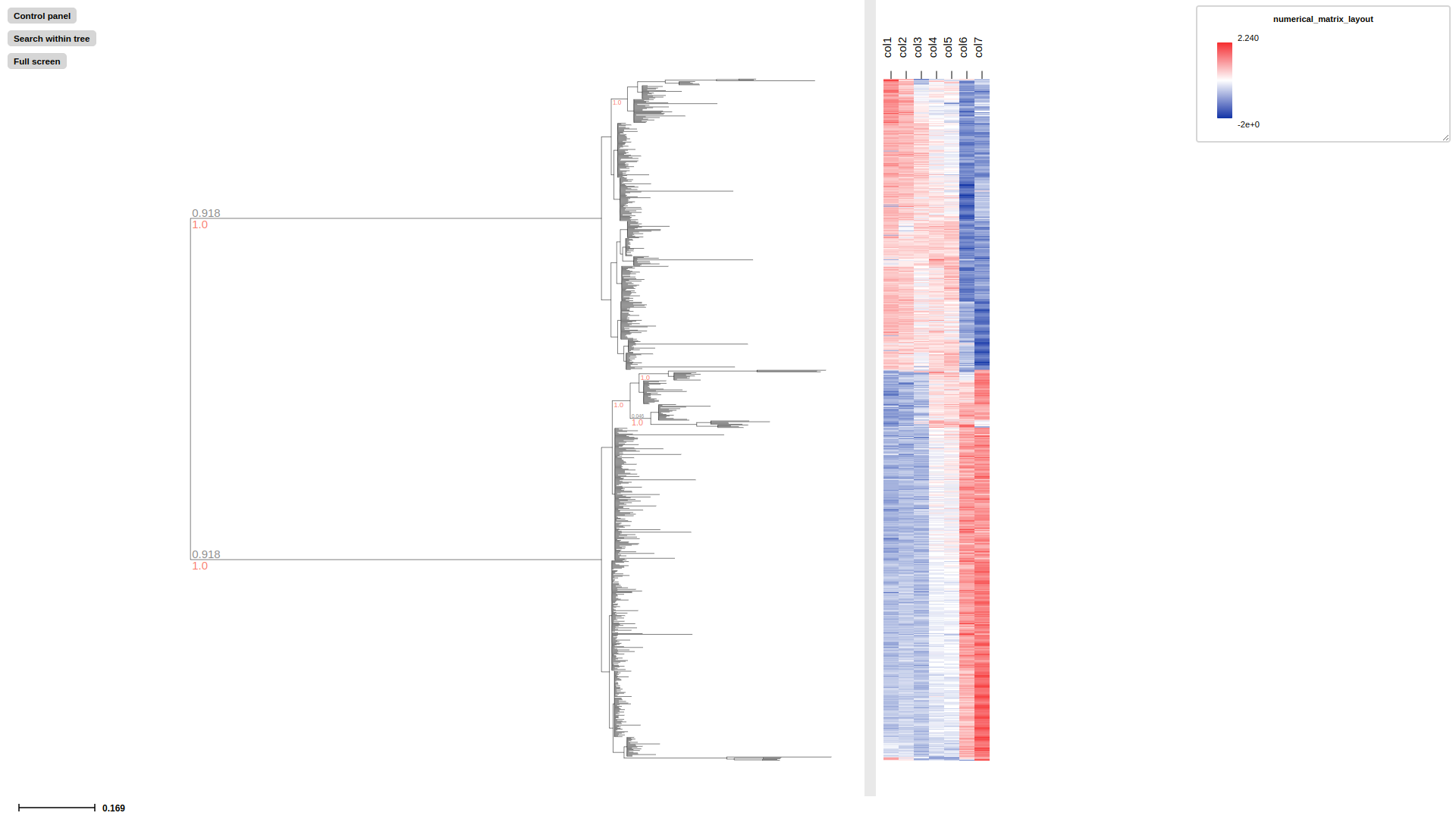
numerical-profiling-layout display multiple numerical data column to numerical data trix, which will automatically scale the minimum and maximum value from blue to red. Comparing to heatmap-layout, numerical-profiling-layout can afford more data columns with faster memory.
Layouts for list data
here we use example in examples/basic_example1/basic_example1_metadata2.tsv
# column `list_data` contain multiple elements value which can be process as list data in treeprofiler
head examples/basic_example1/basic_example1_metadata2.tsv
#name abs_data list_data
Phy003I7ZJ_CHICK 97 w,t,t
Phy0054BO3_MELGA 16 r,q,s
Phy00508FR_NIPNI 87 z,f,p
Phy004O1E0_APTFO 6 z,t,b
Phy004PA1B_ANAPL 72 z,r,p
## annotate tree first
treeprofiler annotate \
--tree examples/basic_example1/basic_example1.nw \
--input-type newick \
--metadata examples/basic_example1/basic_example1_metadata2.tsv \
-o examples/basic_example1/
Column list_data contain multiple elements value which can be process as list data in treeprofiler. Users can visualize list information using --multi-profiling-layout, which will . In this case, we highly reccomend users using ete using --input-type in order to resume datatype list in annotated tree.
# visualize using multi_profiling_layout
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--input-type ete \
--multi-profiling-layout list_data
Layouts for multiple sequence alignment
In order to visualize multiple sequence alignment alongside with the tree, first we need to annotate alignment using --alignment in annotate. Then activate alignment layout by adding --alignment-layout
# annotate
treeprofiler annotate \
--tree examples/basic_example2/MCC_FluA_H3.nw \
--input-type newick \
--alignment ./examples/basic_example2/FluA_H3_AA.fas \
--outdir examples/basic_example2/
# visualize
treeprofiler plot \
--tree examples/basic_example2/MCC_FluA_H3_annotated.ete \
--alignment-layout

alignment-layout displays multiple sequence alignments with a tree. Whole MSA sequences were visualized with a tree in rectangular layout. Sacle of sequence with position roadmark located at the top.
Layouts for eggnog-mapper pfam annotations
if metadata is pfam annotations from eggnog-mapper, using --emapper-pfam to annotate domain information in target tree and MUST be with the alignment using --alignment to attach corresponding file.
Once tree is annotated, using --domain-layout to visualize it.
treeprofiler annotate \
--tree examples/pratical_example/emapper/7955.ENSDARP00000116736.nw \
--input-type newick \
--emapper-pfam examples/pratical_example/emapper/7955.out.emapper.pfam \
--alignment examples/pratical_example/emapper/7955.ENSDARP00000116736.aln.faa \
-o examples/pratical_example/emapper/
treeprofiler plot \
--tree examples/pratical_example/emapper/7955.ENSDARP00000116736_annotated.ete \
--domain-layout

domain-layout displays domain annotation with a tree. It requires sequence infomration --alignment in annotate step from MSA sequences to locate domain start and end position.
Layouts for eggnog-mapper smart annotations
if metadata is smart annotations from eggnog-mapper, using --emapper-smart to annotate domain information in target tree and must be with the alignment using --alignment to attach corresponding file.
Once tree is annotated, using --domain-layout to visualize it.
treeprofiler annotate \
--tree examples/pratical_example/emapper/7955.ENSDARP00000116736.nw \
--input-type newick \
--emapper-smart examples/pratical_example/emapper/7955.out.emapper.smart.out \
--alignment examples/pratical_example/emapper/7955.ENSDARP00000116736.aln.faa \
-o examples/pratical_example/emapper/
treeprofiler plot \
--tree examples/pratical_example/emapper/7955.ENSDARP00000116736_annotated.ete \
--domain-layout
Layouts for eggnog-mapper annotations
If metadata is output from eggnog-mapper, using --emapper-annotations automatically parse all information as metadata. Program will parse data of all the columns from emapper output. Once tree is annotated, using --emapper-layout to visualize tree with all the metadata
seed_ortholog evalue score eggNOG_OGs max_annot_lvl COG_category Description Preferred_name GOs EC KEGG_ko KEGG_Pathway KEGG_Module KEGG_Reaction KEGG_rclass BRITE KEGG_TC CAZy BiGG_Reaction PFAMs
treeprofiler annotate \
--tree examples/pratical_example/emapper/7955.ENSDARP00000116736.nw \
--input-type newick \
--emapper-annotations examples/pratical_example/emapper/7955.out.emapper.annotations \
-o examples/pratical_example/emapper/
treeprofiler plot \
--tree examples/pratical_example/emapper/7955.ENSDARP00000116736_annotated.ete \
--input-type ete \
--emapper-layout
Check eggnogmapper example
Visualizing annotated internal nodes
If internal nodes are annotated, TreeProfiler is also able to visualize annotated features automatically when layouts are activated
Internal nodes of categorical and boolean data
As internal nodes of categorical and boolean data are annotated as counter, for categorical data it generates a stacked bar of counter summary at the top of each internal node. And for boolean data, it generates a heatmap where represent positive(or negative) percentage of total data of each internal node.
Categorical data
Before collapsed
 After collapsed
After collapsed
 In this example, collapsed internal node shows a stacked bar which summarize categorical counter data of children nodes. 1/6 is red, 2/6 is blue and 3/6 is green.
In this example, collapsed internal node shows a stacked bar which summarize categorical counter data of children nodes. 1/6 is red, 2/6 is blue and 3/6 is green.
Boolean data
Before collapsed
 After collapsed
After collapsed
 In this example, collapsed internal node shows a heatmap which represent the gradient level of positive/total ratio.
In this example, collapsed internal node shows a heatmap which represent the gradient level of positive/total ratio.
Internal nodes of numerical data
Internal nodes of numerical data are process descriptive statistic analysis by default, hence when users collapse any branch, barplot_layout or heatmap_layout will demonstrate representative value, avg by default. representative value can be changed by using --internal-plot-measure
Numerical data
# select max instead of avg as internal node ploting representative
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--heatmap-layout sample1,sample2,sample3,sample4,sample5 \
--internal-plot-measure max
Before collapsed

After collapsed
avg as itnernal plot measure
 max as itnernal plot measure
max as itnernal plot measure

Layouts for Taxonomic data
If target tree was annotated with --taxon-column in previous annotate step successfully, now activate Taxonomic layout using --taxonclade-layout or --taxonrectangle-layout to visualize taxonomic classification. All rank levels will be generated separately and users can switch each of them on/off.
## Annotate
# GTDB
treeprofiler annotate \
--tree examples/taxonomy_example/gtdb/gtdb_example1.nw \
--metadata examples/taxonomy_example/gtdb/gtdb_example1.tsv \
--taxon-column name \
--taxon-column name \
--taxadb GTDB \
--outdir ./examples/taxonomy_example/gtdb/
# NCBI
treeprofiler annotate \
--tree examples/taxonomy_example/ncbi/spongilla_example.nw \
--metadata examples/taxonomy_example/ncbi/spongilla_example.tsv \
--taxon-column name \
--taxon-delimiter . \
--taxa-field 0 \
--taxadb NCBI \
--outdir ./examples/taxonomy_example/ncbi/
## Visualize
treeprofiler plot \
--tree ./examples/taxonomy_example/gtdb/gtdb_example1_annotated.nw \ --taxonrectangle-layout
treeprofiler plot \
--tree examples/taxonomy_example/ncbi/spongilla_example_annotated.nw \ --taxonclade-layout

taxonrectangle-layout shows taxonomic classification as rectangular block from root to leaf.

taxonclade-layout color associated clade of each category of each rank.
Conditional query in annotated tree
TreeProfiler allows users to perform conditional process based on different circumstances
-
Conditional pruning, conditional pruning works both annotate and plot subcommand
--pruned-by, prune the annotated tree by conditions, and remove the branches or clades which don't fit the condition.--rank-limit, prune the taxonomic annotated tree based on rank of classification.
-
Conditional collapsing, conditional collapsing works in plot subcommand, allow users to collapsed tree internal nodes to clade under customized conditions
--collapsed-by, collapse tree branches whose nodes if the conditions, mainly on internal nodes
-
Conditional highlight, conditional highlight works in plot subcommand, allow users to highlight tree nodes under customized conditions
--highlighted-by, select tree nodes which fit the conditions
Query Syntax
Basic Query
All the conditional query shared the same syntax, a standard query consists the following
--pruned-by|collapsed-by|highlighted-by "<left_value> <operator> <right_value>"
- left value, the property of leaf node or internal node
- operators
- right value, custom value for the condition
Example
## annotate tree
treeprofiler annotate \
--tree examples/basic_example1/basic_example1.nw \
--input-type newick \
--metadata examples/basic_example1/basic_example1_metadata1.tsv \
--bool-prop bool_type bool_type2 \
--counter-stat relative \
-o examples/basic_example1/
# Conditional pruning, prune leaf node whose name contain "FALPE"
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.nw \
--input-type newick \
--pruned-by "name contains FALPE"
Left panel is tree before prune, right panel is result after prune

# Conditional highlight
# select tree node whose name contains `FALPE` character
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.nw \
--input-type newick \
--highlighted-by "name contains FALPE"

# select tree node whose sample1 feature > 0.50, here we using ete format which can resume the datatype
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--input-type ete \
--highlighted-by "sample1 > 0.50" \
--heatmap-layout sample1
# if use tree in newick format, we need to attach the prop2type file which can resume the datatype
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.nw \
--input-type newick \
--prop2type examples/basic_example1/basic_example1_prop2type.txt \
--highlighted-by "sample1 > 0.50" \
--heatmap-layout sample1

Query in internal nodes
Query in internal nodes' properties is also available, in this case, left_value of query will be the internal node property, remember to add the proper suffixes such as _avg, _max,etc, for the numerical data or _counter for categorical and boolean data.
Example
# select tree internal node where sample1_avg feature < 0.50
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--input-type ete \
--heatmap-layout sample1 \
--collapsed-by "sample1_avg < 0.50"
 Syntax for internal node counter data
Syntax for internal node counter data
# collapse tree internal nodes, where `high` relative counter > 0.35 in random_type_counter property
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--input-type ete \
--rectangle-layout random_type \
--collapsed-by "random_type_counter:high > 0.35" \
--column-width 70

AND and OR conditions
The syntax for the AND condition and OR condition in TreeProfiler is:
AND condition will be under one argument, syntax seperated by ,, such as
# select tree node where sample1 feature > 0.50 AND sample2 < 0.2
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--input-type ete \
--heatmap-layout sample1 sample2 sample3 sample4 sample5 \
--highlighted-by "sample1>0.50,sample2<0.2"
 OR condition will be used more than one arguments
OR condition will be used more than one arguments
# select tree node where sample1 feature > 0.50 OR sample2 < 0.2
treeprofiler plot \
--tree examples/basic_example1/basic_example1_annotated.ete \
--input-type ete \
--heatmap-layout sample1 sample2 sample3 sample4 sample5 \
--highlighted-by "sample1>0.50" \
--highlighted-by "sample2<0.2"

conditional limit based on taxonomic level
Prune taxonomic annotated tree based on following taxonomic rank level,
kingdom, phylum, class, order, family, genus, species, subspecies
# Case in GTDB
# before pruning
treeprofiler plot \
--tree examples/taxonomy_example/gtdb/gtdb_example1_annotated.ete \
--input-type ete \
--taxonclade-layout
before rank limit

# prune tree in visualization, rank limit to family level
treeprofiler plot \
--tree examples/taxonomy_example/gtdb/gtdb_example1_annotated.ete \
--input-type ete \
--rank-limit class \
--taxonclade-layout
After rank_limit
 As you see, class branches of target gtdb tree are all pruned and only left the internal branches which rank as class.
As you see, class branches of target gtdb tree are all pruned and only left the internal branches which rank as class.
Demo1 Explore GTDB taxonomic tree with metadata and habitat information of progenome3
To illustrate the easiness and flexibility of TreeProfiler, we use it to annotate and visualize the version 202 of the GTDB prokaryotic phylogeny, which represents a species tree with 60,000 representative bacterial and archaeal species in here. GTDB provides the tree in plain newick format and massive datatable with various associated to such species. Apart from the metadata provided by the GTDB, here we also include annotations of genomes and species clusters to habitats from proGenomes3(Fullam et al. 2023).
Example can be found in directory ./examples/pratical/gtdb_r202/. We already prepared the gtdb v202 taxonomic tree gtdbv202.nw by merging Bacteria and Archaea trees, detailed steps are included in merge_gtdbtree.py. Based on the difference of computational capacity, complete steps and pipeline can be found in gtdbv202full_demo.sh and gtdbv202lite_demo.sh.
- A glance of habitat information of progenome3
cd examples/pratical/gtdb_r202/
zcat progenome3.tar.gz|head -n 4
progenome3.tsv0000664000175000017500000343216414447266674012351 0ustar dengdenggtdb_genome_representative aquatic_habitat host_associated soil_habitat
RS_GCF_004210275.1 f t f
GB_GCA_014116815.1
RS_GCF_000730245.1 f t f
- Download metadata of archaea and bacteria from gtdb
wget https://data.gtdb.ecogenomic.org/releases/release202/202.0/ar122_metadata_r202.tar.gz
wget https://data.gtdb.ecogenomic.org/releases/release202/202.0/bac120_metadata_r202.tar.gz
- GTDB metadata annotation
Considering the size of GTDB metadata and phylogeney, here we provide two pipelines for user to choose base on their computational resources.
- GTDB partial annotation (lightweight), which we will extract only a few of columns from metadata for annotation
# Extract genome_size, protein_count, gc_percentage, ncbi_assembly_level, ncbi_genome_category columns from GTDB metadata
tar -xf ar122_metadata_r202.tar.gz -O | cut -f1,14,89,13,46,56 > ar122_metadata_r202_lite.tsv
tar -xf bac120_metadata_r202.tar.gz -O | cut -f1,14,89,13,46,56 > bac120_metadata_r202_lite.tsv
# start annotation
treeprofiler annotate \
--tree gtdbv202.nw \
--input-type newick \
--metadata \
ar122_metadata_r202_lite.tsv bac120_metadata_r202_lite.tsv progenome3.tar.gz \
--taxon-column name \
--taxadb GTDB \
-o ./
- GTDB full annotation, which requires >6G disk space and >15G RAM memory.
# Annotate metadatas to taxonomic tree(this step may take a few minutes)
treeprofiler annotate \
--tree gtdbv202.nw \
--input-type newick \
--metadata \
ar122_metadata_r202.tar.gz bac120_metadata_r202.tar.gz progenome3.tar.gz \
--taxon-column name \
--taxadb GTDB \
-o ./
- Visualizing annotated GTDB tree with GTDB metadata, which are
treeprofiler plot \
--tree gtdbv202_annotated.ete \
--input-type ete \
--barplot-layout genome_size protein_count \
--heatmap-layout gc_percentage \
---binary-layout aquatic_habitat host_associated soil_habitat \
--rectangle-layout ncbi_assembly_level ncbi_genome_category \
--taxonclade-layout \
--column-width 70
 Here we show the GTDB v202 taxonomy tree (bacteria+archaea, 47894 leaves) in rectangular tree layout, with selected annotated properties which are displayed by order in aligned panel. Numerical data
Here we show the GTDB v202 taxonomy tree (bacteria+archaea, 47894 leaves) in rectangular tree layout, with selected annotated properties which are displayed by order in aligned panel. Numerical data genome_size and protein_count are visualized as barplot, gc_percentage is shown as heatmap. Habitat information of progenome3, aquatic_habitat, host_associated and soil_habitat are shown as binary layout. Two categorical data ncbi_assembly_level and ncbi_genome_category are visualized as rectangular layout. In order to improve memory effiency, tree has default collapse level (10) hence multiple leaf nodes are collapsed as default, if nodes are collapsed, aligned layouts represented corresponding values of each property of annotated internal nodes. In this level, taxonclade-layout of the highest classification kingdom is activated, which demonstrate bacteria in salmon, archaea in blue.
 Once zoom into smaller view in tree, collapse level reduces automatically (or manually) to 1, then leaf nodes are dynamically displayed and rendered. Therefore associated layouts are shown as represending values of annotated leaves.
Once zoom into smaller view in tree, collapse level reduces automatically (or manually) to 1, then leaf nodes are dynamically displayed and rendered. Therefore associated layouts are shown as represending values of annotated leaves. taxonclade-layout colored leaf nodes in specie rank level.
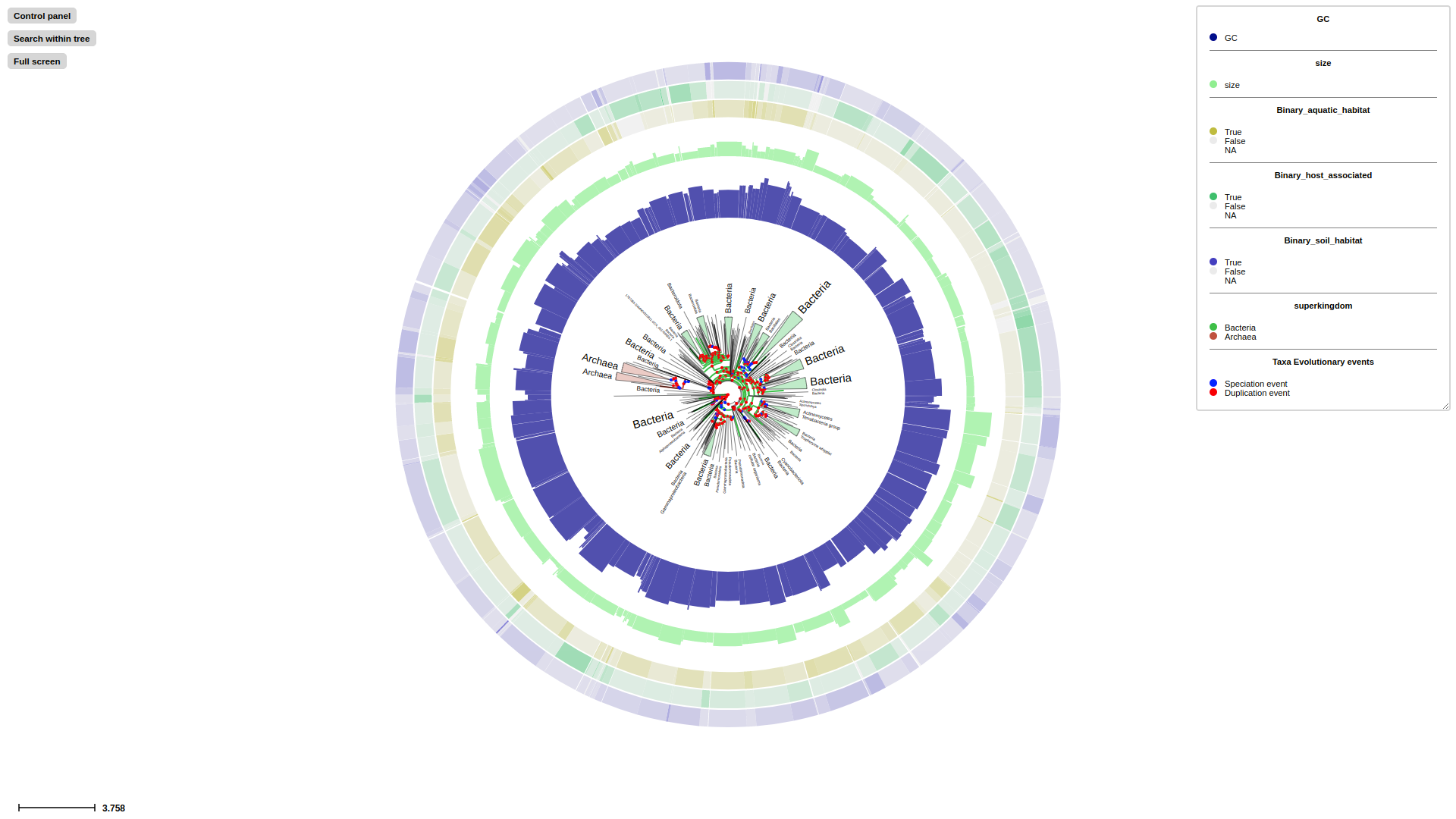 Annotated tree and layouts can be shown as circular tree layout.
Annotated tree and layouts can be shown as circular tree layout.
Demo2 Explore large NifH gene tree with functional and taxonomic information
Here we analyzed the nitrogenase iron protein NifH gene family across bacteria from EggNOG6 with EggNOG-mapper, a tool for functional annotation based on precomputed orthology assignments. TreeProfiler provides options which allows users to directly map EggNOG-mapper outputs including functional annotations and pfam/smart domain predictions. Hence are then able to map these functional annotations to their respective phylogenetic gene trees and them with the evolutionary history, tracing from leaf to root level.
Map emapper annotation, pfam annotation and taxonomic annotation to target tree
treeprofiler annotate \
--tree examples/pratical_example/emapper/nifH.tree \
--emapper-annotation examples/pratical_example/emapper/nifH.out.emapper.annotations \
--emapper-pfam examples/pratical_example/emapper/nifH.out.emapper.pfam \
--alignment examples/pratical_example/emapper/nifH.faa.aln \
--taxon-column name \
--taxadb NCBI \
--taxon-delimiter . \
--taxa-field 0 \
-o examples/pratical_example/emapper/
Visualize annotations of emapper, pfam domain and ncbi taxonomy
treeprofiler plot \
--tree examples/pratical_example/emapper/nifH_annotated.ete \
--input-type ete \
--emapper-layout \
--domain-layout \
--taxonclade-layout \
--column-width 70
visualization of categorical data seed_orthologs, max_annot_lvl, COG_category, Description, Preferred_name, and numerical data score

visualization of KEGG_Pathway profiling

visualization of KEGG_ko profiling

visualization of domain annotation




