
Research
2025 Report: Destructive Malware in Open Source Packages
Destructive malware is rising across open source registries, using delays and kill switches to wipe code, break builds, and disrupt CI/CD.
By Kush Pandya - Dec 24, 2025
txtai
Advanced tools
All-in-one open-source AI framework for semantic search, LLM orchestration and language model workflows
![]()
All-in-one AI framework



![]()

txtai is an all-in-one AI framework for semantic search, LLM orchestration and language model workflows.

The key component of txtai is an embeddings database, which is a union of vector indexes (sparse and dense), graph networks and relational databases.
This foundation enables vector search and/or serves as a powerful knowledge source for large language model (LLM) applications.
Build autonomous agents, retrieval augmented generation (RAG) processes, multi-model workflows and more.
Summary of txtai features:
txtai is built with Python 3.10+, Hugging Face Transformers, Sentence Transformers and FastAPI. txtai is open-source under an Apache 2.0 license.
[!NOTE]
NeuML is the company behind txtai and we provide AI consulting services around our stack. Schedule a meeting or send a message to learn more.
We're also building an easy and secure way to run hosted txtai applications with txtai.cloud.

New vector databases, LLM frameworks and everything in between are sprouting up daily. Why build with txtai?
# Get started in a couple lines
import txtai
embeddings = txtai.Embeddings()
embeddings.index(["Correct", "Not what we hoped"])
embeddings.search("positive", 1)
#[(0, 0.29862046241760254)]
# app.yml
embeddings:
path: sentence-transformers/all-MiniLM-L6-v2
CONFIG=app.yml uvicorn "txtai.api:app"
curl -X GET "http://localhost:8000/search?query=positive"
The following sections introduce common txtai use cases. A comprehensive set of over 70 example notebooks and applications are also available.
Build semantic/similarity/vector/neural search applications.

Traditional search systems use keywords to find data. Semantic search has an understanding of natural language and identifies results that have the same meaning, not necessarily the same keywords.

Get started with the following examples.
| Notebook | Description | |
|---|---|---|
| Introducing txtai ▶️ | Overview of the functionality provided by txtai | |
| Similarity search with images | Embed images and text into the same space for search | |
| Build a QA database | Question matching with semantic search | |
| Semantic Graphs | Explore topics, data connectivity and run network analysis |
Autonomous agents, retrieval augmented generation (RAG), chat with your data, pipelines and workflows that interface with large language models (LLMs).
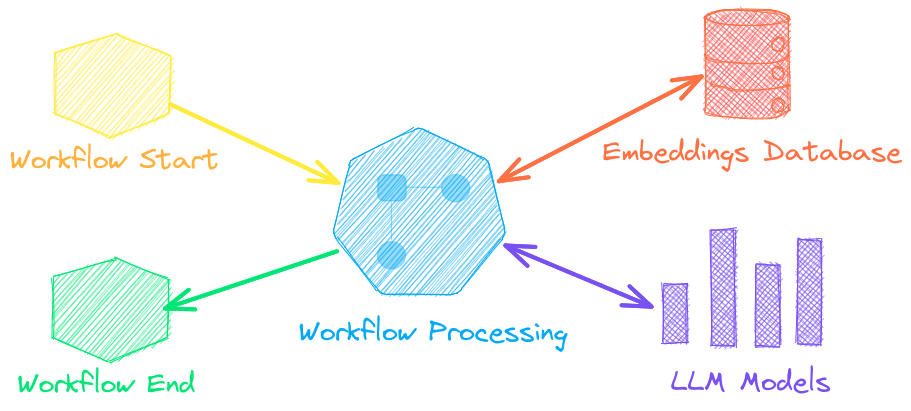
See below to learn more.
| Notebook | Description | |
|---|---|---|
| Prompt templates and task chains | Build model prompts and connect tasks together with workflows | |
| Integrate LLM frameworks | Integrate llama.cpp, LiteLLM and custom generation frameworks | |
| Build knowledge graphs with LLMs | Build knowledge graphs with LLM-driven entity extraction | |
| Parsing the stars with txtai | Explore an astronomical knowledge graph of known stars, planets, galaxies |
Agents connect embeddings, pipelines, workflows and other agents together to autonomously solve complex problems.
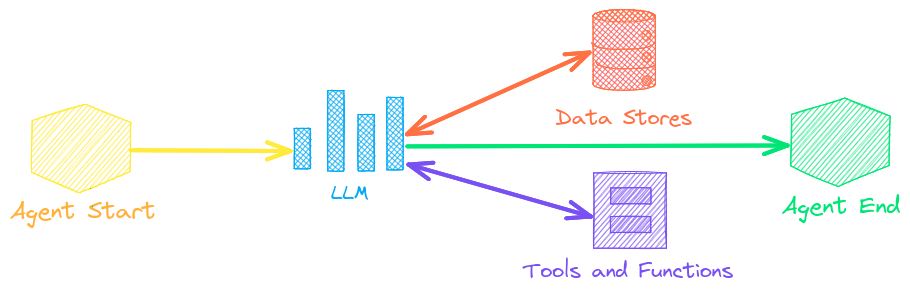
txtai agents are built on top of the smolagents framework. This supports all LLMs txtai supports (Hugging Face, llama.cpp, OpenAI / Claude / AWS Bedrock via LiteLLM).
Check out this Agent Quickstart Example. Additional examples are listed below.
| Notebook | Description | |
|---|---|---|
| Analyzing Hugging Face Posts with Graphs and Agents | Explore a rich dataset with Graph Analysis and Agents | |
| Granting autonomy to agents | Agents that iteratively solve problems as they see fit | |
| Analyzing LinkedIn Company Posts with Graphs and Agents | Exploring how to improve social media engagement with AI |
Retrieval augmented generation (RAG) reduces the risk of LLM hallucinations by constraining the output with a knowledge base as context. RAG is commonly used to "chat with your data".

Check out this RAG Quickstart Example. Additional examples are listed below.
| Notebook | Description | |
|---|---|---|
| Build RAG pipelines with txtai | Guide on retrieval augmented generation including how to create citations | |
| RAG is more than Vector Search | Context retrieval via Web, SQL and other sources | |
| GraphRAG with Wikipedia and GPT OSS | Deep graph search powered RAG | |
| Speech to Speech RAG ▶️ | Full cycle speech to speech workflow with RAG |
Language model workflows, also known as semantic workflows, connect language models together to build intelligent applications.

While LLMs are powerful, there are plenty of smaller, more specialized models that work better and faster for specific tasks. This includes models for extractive question-answering, automatic summarization, text-to-speech, transcription and translation.
Check out this Workflow Quickstart Example. Additional examples are listed below.
| Notebook | Description | |
|---|---|---|
| Run pipeline workflows ▶️ | Simple yet powerful constructs to efficiently process data | |
| Building abstractive text summaries | Run abstractive text summarization | |
| Transcribe audio to text | Convert audio files to text | |
| Translate text between languages | Streamline machine translation and language detection |

The easiest way to install is via pip and PyPI
pip install txtai
Python 3.10+ is supported. Using a Python virtual environment is recommended.
See the detailed install instructions for more information covering optional dependencies, environment specific prerequisites, installing from source, conda support and how to run with containers.
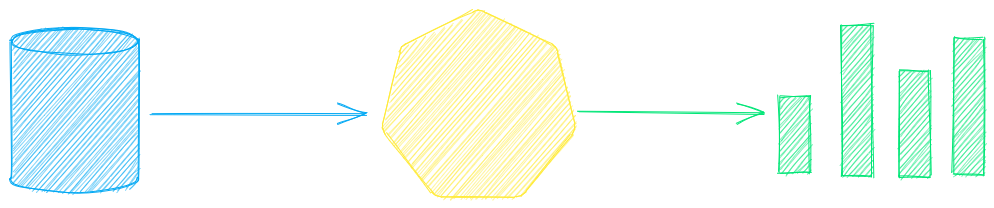
See the table below for the current recommended models. These models all allow commercial use and offer a blend of speed and performance.
Models can be loaded as either a path from the Hugging Face Hub or a local directory. Model paths are optional, defaults are loaded when not specified. For tasks with no recommended model, txtai uses the default models as shown in the Hugging Face Tasks guide.
See the following links to learn more.
The following applications are powered by txtai.
| Application | Description |
|---|---|
| rag | Retrieval Augmented Generation (RAG) application |
| ragdata | Build knowledge bases for RAG |
| paperai | AI for medical and scientific papers |
| annotateai | Automatically annotate papers with LLMs |
In addition to this list, there are also many other open-source projects, published research and closed proprietary/commercial projects that have built on txtai in production.

Full documentation on txtai including configuration settings for embeddings, pipelines, workflows, API and a FAQ with common questions/issues is available.
For those who would like to contribute to txtai, please see this guide.
FAQs
All-in-one open-source AI framework for semantic search, LLM orchestration and language model workflows
We found that txtai demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
Destructive malware is rising across open source registries, using delays and kill switches to wipe code, break builds, and disrupt CI/CD.

Security News
Socket CTO Ahmad Nassri shares practical AI coding techniques, tools, and team workflows, plus what still feels noisy and why shipping remains human-led.

Research
/Security News
A five-month operation turned 27 npm packages into durable hosting for browser-run lures that mimic document-sharing portals and Microsoft sign-in, targeting 25 organizations across manufacturing, industrial automation, plastics, and healthcare for credential theft.