jendeley
jendeley is a JSON-based PDF paper organizing software.
jendeley is JSON-based. You can see and edit your database easily.jendeley is working locally. Your important database is owned only by you. Not cloud.jendeley is browser based. You can run it anywhere node.js runs.
How to install
npm install @a_kawashiro/jendeley -g
How to scan your PDFs
This command emits the database to <YOUR PDFs DIR>/jendeley_db.json. When jendeley failed to scan some PDFs, it emit a shellscript edit_and_run.sh. Please read the next subsection and rename files using it.
jendeley scan --papers_dir <YOUR PDFs DIR>
When failed to scan your PDFs
jendeley is heavily dependent on Digital Object Identifier System(DOI) or ISBN to find title, authors and published year of PDFs. So jendeley try to find DOI of given PDFs in many ways. But sometimes all of them fails to find DOI. In that case, you can specify DOI of PDF manually using filename.
- To specify DOI, change the filename to include
[jendeley doi <DOI replaced all delimiters with underscore>]. For example, cyclone [jendeley doi 10_1145_512529_512563].pdf. - To specify ISBN, change the filename to include
[jendeley isbn <ISBN>]. For example, hoge [jendeley isbn 9781467330763].pdf.
Launch jendeley UI
jendeley launch --db <YOUR PDFs DIR>/jendeley_db.json
Then you can see a screen like this!
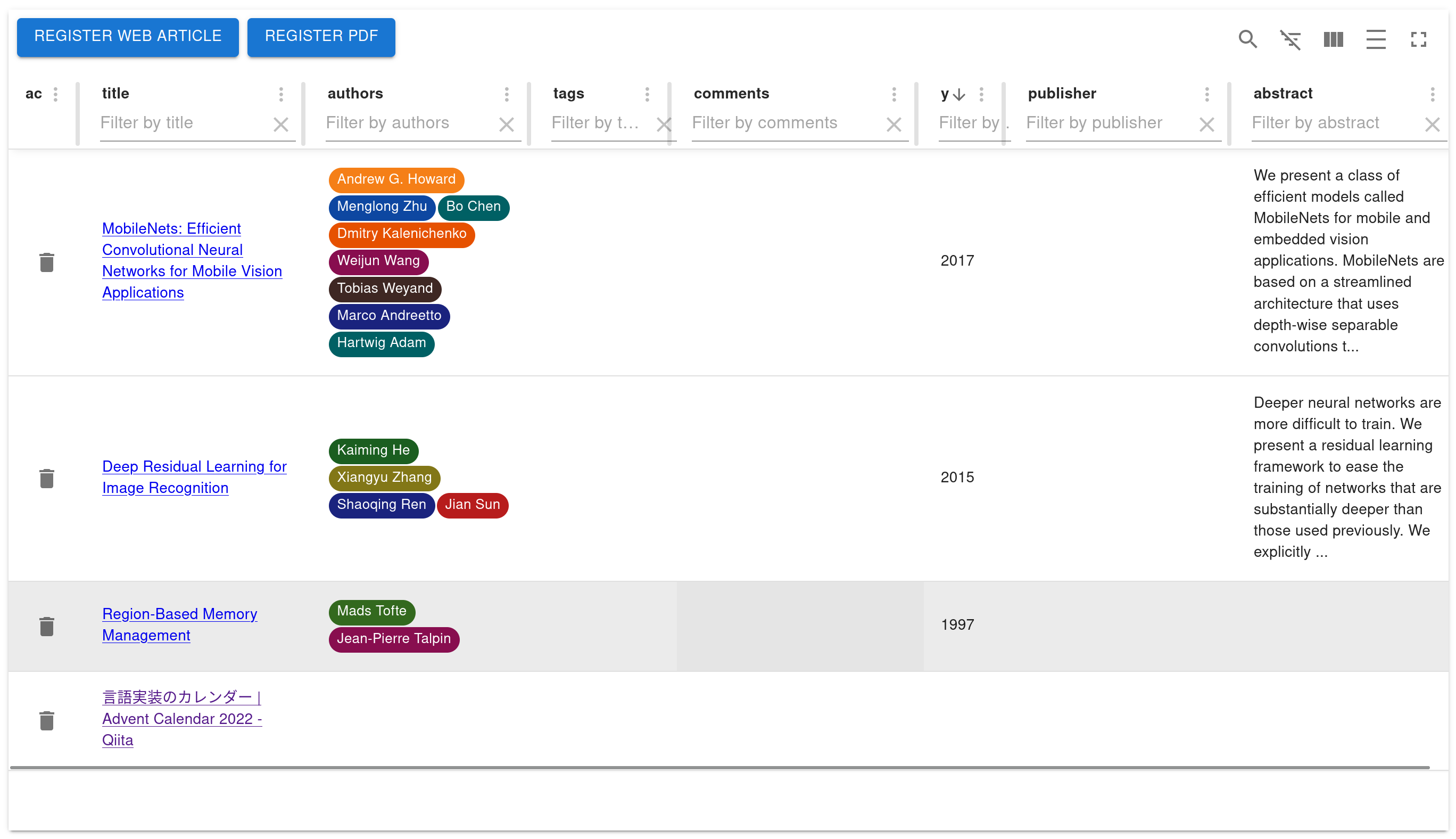
If you don't have any PDFs, please use Deep Residual Learning for Image Recognition.
If you want to launch jendeley automatically
When you are using Linux, you can launch jendeley automatically using systemd. Please make ~/.config/systemd/user/jendeley.service with the following contents, run systemctl --user enable jendeley && systemctl --user start jendeley and access http://localhost:5000. You can check log with journalctl --user -f -u jendeley.service.
[Unit]
Description=jendeley JSON based document organization software
[Service]
ExecStart=jendeley launch --db <FILL PATH TO THE YOUR DATABASE JSON FILE> --no_browser
[Install]
WantedBy=default.target
Check your database
Because jendeley is fully JSON-based, you can check the contents of the
database easily. For example, you can use jq command to list up all titles in
your database with the following command.
> cat test_pdfs/db.json | jq '.[].title'
"MobileNets: Efficient Convolutional Neural Networks for Mobile Vision\n Applications"
"Deep Residual Learning for Image Recognition"
"A quantum hydrodynamical description for scrambling and many-body chaos"



