cobweb
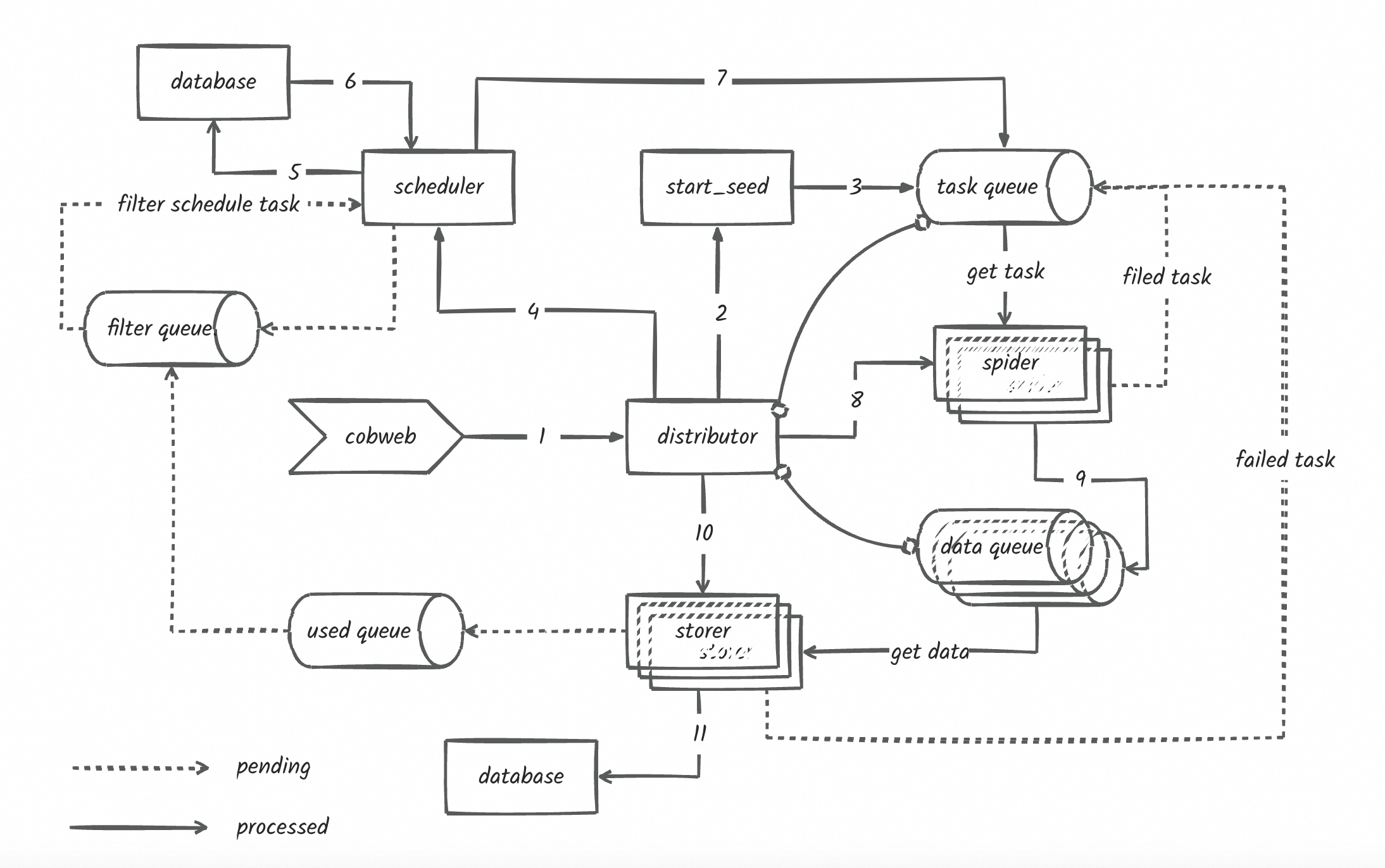
cobweb是一个基于python的分布式爬虫调度框架,目前支持分布式爬虫,单机爬虫,支持自定义数据库,支持自定义数据存储,支持自定义数据处理等操作。
cobweb主要由3个模块和一个配置文件组成:Launcher启动器、Crawler采集器、Pipeline存储和setting配置文件。
- Launcher启动器:用于启动爬虫任务,控制爬虫任务的执行流程,以及数据存储和数据处理。
框架提供两种启动器模式:LauncherAir、LauncherPro,分别对应单机爬虫模式和分布式调度模式。
- Crawler采集器:用于控制采集流程、数据下载和数据处理。
框架提供了基础的采集器,用于控制采集流程、数据下载和数据处理,用户也可在创建任务时自定义请求、下载和解析方法,具体看使用方法介绍。
- Pipeline存储:用于存储采集到的数据,支持自定义数据存储和数据处理。框架提供了Console和Loghub两种存储方式,用户也可继承Pipeline抽象类自定义存储方式。
- setting配置文件:用于配置采集器、存储器、队列长度、采集线程数等参数,框架提供了默认配置,用户也可自定义配置。
安装
pip3 install --upgrade cobweb-launcher
使用方法介绍
1. 任务创建
from cobweb import Launcher
app = Launcher(task="test", project="test")
app.SEEDS = [{
"url": "https://www.baidu.com"
}]
...
app.start()
2. 自定义配置文件参数
- 通过自定义setting文件,配置文件导入字符串方式
默认配置文件:import cobweb.setting
不推荐!!!目前有bug,随缘使用...
例如:同级目录下自定义创建了setting.py文件。
from cobweb import Launcher
app = Launcher(
task="test",
project="test",
setting="import setting"
)
...
app.start()
from cobweb import Launcher
app = Launcher(
task="test",
project="test",
REDIS_CONFIG = {
"host": ...,
"password":...,
"port": ...,
"db": ...
}
)
...
app.start()
3. 自定义请求
@app.request使用装饰器封装自定义请求方法,作用于发生请求前的操作,返回Request对象或继承于BaseItem对象,用于控制请求参数。
from typing import Union
from cobweb import Launcher
from cobweb.base import Seed, Request, BaseItem
app = Launcher(
task="test",
project="test"
)
...
@app.request
def request(seed: Seed) -> Union[Request, BaseItem]:
proxies = {"http": ..., "https": ...}
yield Request(seed.url, seed, ..., proxies=proxies, timeout=15)
...
app.start()
默认请求方法
def request(seed: Seed) -> Union[Request, BaseItem]:
yield Request(seed.url, seed, timeout=5)
4. 自定义下载
@app.download使用装饰器封装自定义下载方法,作用于发生请求时的操作,返回Response对象或继承于BaseItem对象,用于控制请求参数。
from typing import Union
from cobweb import Launcher
from cobweb.base import Request, Response, BaseItem
app = Launcher(
task="test",
project="test"
)
...
@app.download
def download(item: Request) -> Union[BaseItem, Response]:
...
response = ...
...
yield Response(item.seed, response, ...)
...
app.start()
默认下载方法
def download(item: Request) -> Union[Seed, BaseItem, Response, str]:
response = item.download()
yield Response(item.seed, response, **item.to_dict)
5. 自定义解析
自定义解析需要由一个存储数据类和解析方法组成。存储数据类继承于BaseItem的对象,规定存储表名及字段,
解析方法返回继承于BaseItem的对象,yield返回进行控制数据存储流程。
from typing import Union
from cobweb import Launcher
from cobweb.base import Seed, Response, BaseItem
class TestItem(BaseItem):
__TABLE__ = "test_data"
__FIELDS__ = "field1, field2, field3"
app = Launcher(
task="test",
project="test"
)
...
@app.parse
def parse(item: Response) -> Union[Seed, BaseItem]:
...
yield TestItem(item.seed, field1=..., field2=..., field3=...)
...
app.start()
默认解析方法
def parse(item: Request) -> Union[Seed, BaseItem]:
upload_item = item.to_dict
upload_item["text"] = item.response.text
yield ConsoleItem(item.seed, data=json.dumps(upload_item, ensure_ascii=False))
todo
未更新流程图!!!