
Konduktor is a source available Run:AI alternative built on Kubernetes. Konduktor uses existing open source tools to build a platform that makes it easy for ML Researchers to submit batch jobs and for administrative/infra teams to easily manage GPU clusters.
How it works
Konduktor uses a combination of open source projects. Where tools exist with MIT, Apache, or another compatible open license, we want to use and even contribute to that tool. Where we see gaps in tooling, we build it and open source ourselves.
Architecture
Konduktor can be self-hosted and run on any certified Kubernetes distribution or managed by us. Contact us at founders@trainy.ai if you are just interested in the managed version. We're focused on tooling for clusters with NVIDIA cards for now but in the future we may expand to our scope to support other accelerators.
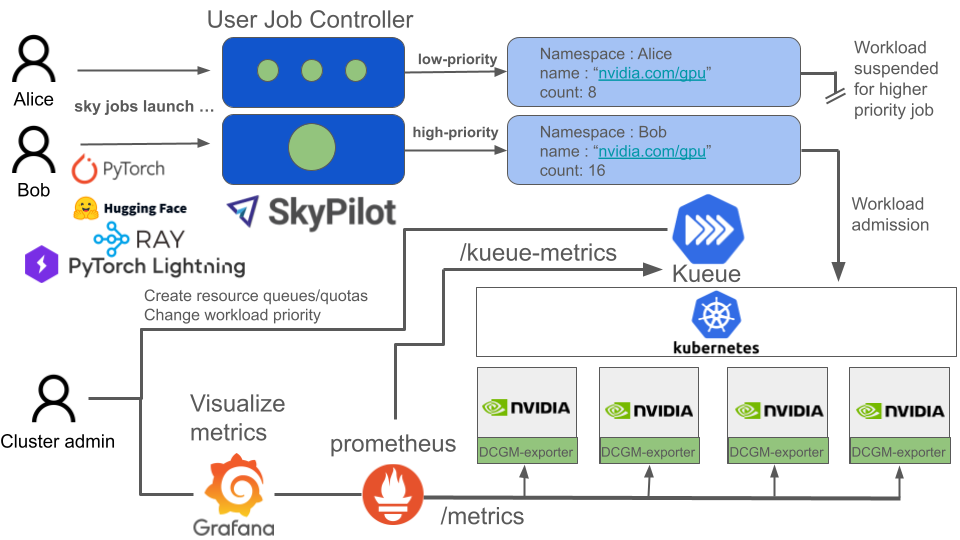
For ML researchers
- Skypilot - user friendly batch job framework, where users only need to specify the resource requirements of their job and a script to launch that makes simple to scale work across multiple nodes. Works with most ML application frameworks. Examples
num_nodes: 100
resources:
accelerators: H100:8
cloud: kubernetes
labels:
kueue.x-k8s.io/queue-name: user-queue
kueue.x-k8s.io/priority-class: low-priority
setup: |
pip install torch torchvision
run: |
torchrun \
--nproc_per_node 8 \
--rdzv_id=1 --rdzv_endpoint=$master_addr:1234 \
--rdzv_backend=c10d --nnodes $num_nodes \
torch_ddp_benchmark.py --distributed-backend nccl
For cluster administrators
- DCGM Exporter, GPU operator, Network Operator - For installing NVIDIA driver, container runtime, and exporting node health metrics.
- Kueue - centralized creation of job queues, gang-scheduling, and resource quotas and sharing across projects.
- Prometheus - For publishing metrics about node health and workload queues.
- OpenTelemetry - For pushing logs from each node
- Grafana, Loki - Visualizations for metrics/logging solution.
Contributor Guide
Format your code with
poetry install --with dev
bash format.sh



