
Security News
MCP Steering Committee Launches Official MCP Registry in Preview
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
By Sarah Gooding - Sep 09, 2025
accessibility-checker
Advanced tools
An automated testing tools for accessibility testing using Puppeteer, Selenium, or Zombie
accessibility-checker is a NodeJS module that allows you to do the following:
The NodeJS module is a component of the IBM Equal Access Toolkit. The Toolkit provides the tools and guidance to create experiences that are delightful for people of all abilities. The guidance is organized by phase, such as Plan, Design, Develop, and Verify, and explains how to integrate the automated testing tools into the Verify phase. The Toolkit is a major part of the accessibility information and applications at ibm.com/able.
Note that we have seen some non-standard CSS parsing with Zombie, so be aware of inconsistencies as a result.
This module provides some basic command-line utilities that will allow scanning files, directories, and URLs:
npx achecker the full path of the .txt file to start the scan (e.g., npx achecker path/to/your/file.txt)npx acheckerThe following is how to perform an accessibility scan within your test cases and verify the scan results:
const aChecker = require("accessibility-checker");
try {
// Perform the accessibility scan using the aChecker.getCompliance API
aChecker.getCompliance(testDataFileContent, testLabel).then((results) => {
const report = results.report;
// Call the aChecker.assertCompliance API which is used to compare the results with the baseline object if we can find one that
// matches the same label which was provided.
const returnCode = aChecker.assertCompliance(report);
// In the case that the violationData is not defined then trigger an error right away.
expect(returnCode).toBe(0, "Scanning " + testLabel + " failed.");
});
} catch (err) {
console.error(err);
} finally {
// close the engine
await aChecker.close();
};
Note that it's critical to close the engine, otherwise, output files for the report may not be generated properly. If you execute batch scans, the engine should be closed after all the scans are completed for better performance. The following is a sample usage scenario:
async batchScan(rptInputFiles) {
let failures = [];
try {
for (let f of rptInputFiles) {
let result;
let isFile = false;
try {
isFile = fs.lstatSync(f).isFile();
f = path.resolve(f);
} catch (e) {}
if (isFile) {
result = await aChecker.getCompliance("file://"+f, f.replace(/^file:\/\//,"").replace(/[:?&=]/g,"_"));
} else {
result = await aChecker.getCompliance(f, f.replace(/^(https?:|file:)\/\//,"").replace(/[:?&=]/g,"_"));
}
if (result) {
if (aChecker.assertCompliance(result.report) === 0) {
console.log("Passed:", f);
} else {
failures.push({
file: f,
report: result.report
});
console.log("Failed:", f);
}
} else {
console.log("Error:", f);
}
}
if (failures.length > 0) {
console.log("Failing scan details:");
for (const fail of failures) {
console.log(aChecker.stringifyResults(fail.report));
}
}
} catch (e) {
console.error(e);
} finally {
await aChecker.close();
}
}
Refer to Examples for sample usage scenarios.
Grab a boilerplate
Install accessibility-checker:
$ npm install --save-dev accessibility-checker
Use the command-line version:
$ npm install -g accessibility-checker
$ achecker
Install the accessibility-checker module:
$ npm install --save-dev accessibility-checker
accessibility-checkerA default configuration is defined which uses the latest archive, IBM_Accessibility policy, and some default settings. If you would like to override any of these values,
create an accessibility-checker configuration file.
Configuring accessibility-checker plugin involves constructing a .achecker.yml file in the project root, which will contain all the configuration
options for accessibility-checker. Following is the structure of the .achecker.yml file:
# optional - Specify the rule archive
# Default: latest
# Run `npx achecker archives` for a list of valid ruleArchive ids and policy ids.
# If "latest", will use the latest rule release
# If "versioned" (supported in 3.1.61+), will use the latest rule release at
# the time this version of the tool was released
ruleArchive: latest
# optional - Specify one or many policies to scan.
# i.e. For one policy use policies: IBM_Accessibility
# i.e. Multiple policies: IBM_Accessibility, WCAG_2_1
# Run `npx achecker archives` for a list of valid ruleArchive ids and policy ids
policies:
- IBM_Accessibility
# optional - Specify one or many violation levels on which to fail the test
# i.e. If specified violation then the testcase will only fail if
# a violation is found during the scan.
# i.e. failLevels: violation
# i.e. failLevels: violation,potential violation or refer to below as a list
# Default: violation, potentialviolation
failLevels:
- violation
- potentialviolation
# optional - Specify one or many violation levels that should be reported
# i.e. If specified violation then in the report it would only contain
# results which are level of violation.
# i.e. reportLevels: violation
# Valid values: violation, potentialviolation, recommendation, potentialrecommendation, manual
# Default: violation, potentialviolation
reportLevels:
- violation
- potentialviolation
- recommendation
- potentialrecommendation
- manual
# Optional - In which formats should the results be output
# Valid values: json, csv, xlsx, html, disable
# Default: json
outputFormat:
- json
# Optional - Specify labels that you would like associated to your scan
#
# i.e.
# label: Firefox,master,V12,Linux
# label:
# - Firefox
# - master
# - V12
# - Linux
# Default: N/A
label:
- master
# optional - Where the scan results should be saved.
# Default: results
outputFolder: results
# Optional - Should the timestamp be included in the filename of the reports?
# Default: true
outputFilenameTimestamp: true
# optional - Where the baseline results should be loaded from
# Default: baselines
baselineFolder: test/baselines
# optional - Where the tool can read/write cached files (ace-node.js / archive.json)
# Default: `${os.tmpdir()}/accessibility-checker/`
cacheFolder: /tmp/accessibility-checker
# (optional) If the checker instantiates Puppeteer (using the command-line version)
# These are additional arguments to pass to Puppeteer
puppeteerArgs:
- --no-sandbox
- --disable-setuid-sandbox
A similar aceconfig.js file can also be used:
module.exports = {
ruleArchive: "latest",
policies: ["IBM_Accessibility"],
failLevels: ["violation", "potentialviolation"],
reportLevels: [
"violation",
"potentialviolation",
"recommendation",
"potentialrecommendation",
"manual",
"pass",
],
outputFormat: ["json"],
outputFilenameTimestamp: true,
label: [process.env.TRAVIS_BRANCH],
outputFolder: "results",
baselineFolder: "test/baselines",
cacheFolder: "/tmp/accessibility-checker",
puppeteerArgs: [ "--no-sandbox", "--disable-setuid-sandbox" ]
};
content, label : string)Execute accessibility scan on provided content. content can be in the following form:
Note: When using Selenium WebDriver the aChecker.getCompliance API will only take Selenium (WebDriver) instance. When using Puppeteer, aChecker.getCompliance expects the Page object.
Using a callback mechanism (callback) to extract the results and perform assertion using accessibility-checker APIs.
content - (String | HTMLElement | HTMLDocument | Selenium WebDriver) content to be scanned for accessibility violations.label - (String) unique label to identify this accessibility scan from others. Using "/" in the label allows for directory hierarchy when results are saved.{
// reference to a webdriver object if Selenium WebDriver was used for the scan
webdriver: undefined,
// reference to a puppeteer object if Puppeteer was used for the scan
// Puppeteer is used for string, URL, and file scans
puppeteer: undefined,
report: {
scanID: "18504e0c-fcaa-4a78-a07c-4f96e433f3e7",
toolID: "accessibility-checker-v3.0.0",
// Label passed to getCompliance
label: "MyTestLabel",
// Number of rules executed
numExecuted: 137,
nls: {
// Mapping of result.ruleId, result.reasonId to get a tokenized string for the result. Message args are result.messageArgs
"WCAG20_Html_HasLang": {
"Pass_0": "Page language detected as {0}"
},
// ...
},
summary: {
URL: "https://www.ibm.com",
counts: {
violation: 1,
potentialviolation: 0,
recommendation: 0,
potentialrecommendation: 0,
manual: 0,
pass: 136,
ignored: 0
},
scanTime: 29,
ruleArchive: "September 2019 Deployment (2019SeptDeploy)",
policies: [
"IBM_Accessibility"
],
reportLevels: [
"violation",
"potentialviolation",
"recommendation",
"potentialrecommendation",
"manual"
],
startScan: 1470103006149
},
results: [
{
// Which rule triggered?
"ruleId": "WCAG20_Html_HasLang",
// In what way did the rule trigger?
"reasonId": "Pass_0",
"value": [
// Is this rule based on a VIOLATION, RECOMMENDATION or INFORMATION
"VIOLATION",
// PASS, FAIL, POTENTIAL, or MANUAL
"PASS"
],
"path": {
// xpath
"dom": "/html[1]",
// path of ARIA roles
"aria": "/document[1]"
},
"ruleTime": 0,
// Generated message
"message": "Page language detected as en",
// Arguments to the message
"messageArgs": [
"en"
],
"apiArgs": [],
// Bounding box of the element
"bounds": {
"left": 0,
"top": 0,
"height": 143,
"width": 800
},
// HTML snippet of the element
"snippet": "<html lang=\"en\">",
// What category is this rule?
"category": "Accessibility",
// Was this issue ignored due to a baseline?
"ignored": false,
// Summary of the value: violation, potentialviolation, recommendation, potentialrecommendation, manual, pass
"level": "pass"
},
// ...
]
}
}
report)Perform assertion on the scan results. Will perform one of the following assertions based on the condition that is met:
In the case a baseline file is provided and available in memory for these scan results, a compare of baseline to report will be made. In this case if report matches the baseline, it returns 0, otherwise returns 1. For this case, assertion is only run on the xpath and ruleId.
In the case no baseline file is provided for this particular scan, assertion will be made based on the provided failLevels. In this case, it returns 2 if there are failures based on failLevels. (violation level matches at least one provided in the failLevels object)
report - (Object) results for which assertion needs to be run. See above for report format.
0 in the case actualResults matches the baseline or no violations fall into the failLevels1 in the case actualResults don't match baseline2 in the case that there is a failure based on failLevels.-1 in the case that an exception has occurred during scanning and the results reflected that.label)Retrieve the diff results based on label in the case API aChecker.assertCompliance(...) returns 1, when actualResults DON'T match baseline.
label - (String) label for which to get the diff results for. (should match the one provided for aChecker.getCompliance(...))Returns a diff object, where left hand side (lhs) is actualResults and right hand side (rhs) is baseline. Refer to deep-diff documentation for the format of the diff object, and how to interpret the object.
Returns undefined if there are no differences.
label)Retrieve the baseline result object based on the label provided.
label - (String) label for which to get the baseline for. (should match the one provided for aChecker.getCompliance(...))Returns object which will follow the same structure as the results object outlined in aChecker.getCompliance
and aChecker.assertCompliance APIs.
Returns undefined in the case baseline is not found for the label provided.
actual, expected, clean)Compare provided actual and expected objects and get the differences if there are any.
actual - (Object) actual results which need to be compared.
Refer to aChecker.assertCompliance APIs for details on properties include.expected - (Object) expected results to compare to.
Refer to aChecker.assertCompliance APIs for details on properties include.clean - (boolean) clean the actual and expected results by converting the objects to match with a basic compliance
compare of only xpath and ruleIDReturns a diff object, where left hand side (lhs) is actualResults and right hand side (rhs) is baseline. Refer to deep-diff documentation for the format of the diff object, and how to interpret the object.
Returns undefined if there are no differences.
report)Retrieve the readable stringified representation of the scan results.
report - (Object) results which need to be stringified.
Refer to aChecker.assertCompliance APIs for details on properties to includeReturns String representation of the scan results which can be logged to the console.
Retrieve the configuration object used by accessibility-checker. See aceconfig.js / .achecker.yml above for details
Close Puppeteer pages and other resources that may be used by accessibility-checker.
This is a subtype of Error defined by the accessibility-checker plugin. It is considered a programming error.
labelNotProvided is thrown from aChecker.getCompliance(...) method call when a label is not provided to
function call for the scan that is to be performed. Note: A label must always be provided when calling
aChecker.getCompliance(...) function.
This is a subtype of Error defined by the accessibility-checker plugin. It is considered a programming error.
labelNotUnique is thrown from aChecker.getCompliance(...) method call when a unique label is not provided to
function call for the scan that is to be performed. Note: Across all accessibility scans the label provided
must always be unique.
This is a subtype of Error defined by the accessibility-checker plugin. It is considered a programming error.
RuleArchiveInvalid is thrown from [aChecker.getCompliance(...)] during verification of rule archive in the configuration file.
The error occurs when the provided ruleArchive value in the configuration file is invalid.
This is a subtype of Error defined by the accessibility-checker plugin. It is considered a programming error.
ValidPoliciesMissing is thrown from [aChecker.getCompliance(...)] method call when no valid policies are in the configuration file.
Note: The valid policies will vary depending on the selected ruleArchive.
If you see TypeError: ace.Checker is not a constructor:
--runInBand in Jest framework.If your site has a Content Security Policy, the engine script may be
prevented from loading. In the browser console, you'll see something like:
VM43:24 Refused to load the script ‘https://cdn.jsdelivr.net/npm/accessibility-checker-engine@3.1.42/ace.js’ because it violates the following Content Security Policy directive:
If you would prefer not to add cdn.jsdelivr.net to the CSP, you can add able.ibm.com instead via your config file (e.g., ruleServer: "https://able.ibm.com/rules")
If you think you've found a bug, have questions or suggestions, open a GitHub Issue, tagged with node-accessibility-checker.
If you are an IBM employee, feel free to ask questions in the IBM internal Slack channel #accessibility-at-ibm.
This package uses IBM Telemetry to collect de-identified and anonymized metrics data. By installing this package as a dependency you are agreeing to telemetry collection. To opt out, see Opting out of IBM Telemetry data collection. For more information on the data being collected, please see the IBM Telemetry documentation.
![]()
FAQs
An automated testing tools for accessibility testing using Puppeteer, Selenium, or Zombie
The npm package accessibility-checker receives a total of 11,735 weekly downloads. As such, accessibility-checker popularity was classified as popular.
We found that accessibility-checker demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 3 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
Product
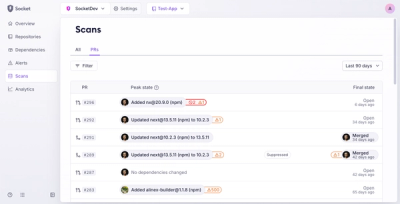
Socket’s new Pull Request Stories give security teams clear visibility into dependency risks and outcomes across scanned pull requests.
Research
/Security News
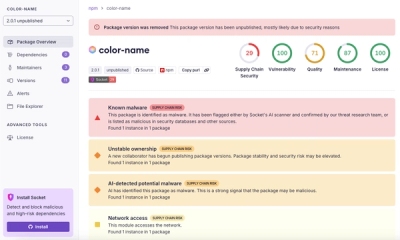
npm author Qix’s account was compromised, with malicious versions of popular packages like chalk-template, color-convert, and strip-ansi published.