pypi
GitHub


Newest version = 0.3.6: torch package needs to be installed seperately to make sure your system env matches;
NexuSync
NexuSync is a lightweight yet powerful library for building Retrieval-Augmented Generation (RAG) systems, built on top of LlamaIndex. It offers a simple and user-friendly interface for developers to configure and deploy RAG systems efficiently. Choose between using the Ollama LLM model for offline, privacy-focused applications or the OpenAI API for a hosted solution.
🚀 Features
- Lightweight Design: Simplify the integration and configuration of RAG systems without unnecessary complexity.
- User-Friendly Interface: Intuitive APIs and clear documentation make setup a breeze.
- Flexible Document Indexing: Automatically index documents from specified directories, keeping your knowledge base up-to-date.
- Efficient Querying: Use natural language to query your document collection and get relevant answers quickly.
- Conversational Interface: Engage in chat-like interactions for more intuitive information retrieval.
- Customizable Embedding Options: Choose between HuggingFace Embedding models or OpenAI's offerings.
- Incremental Updates: Easily update and insert new documents into the index or delete the index for removed documents.
- Automatic Deletion Handling: Documents removed from the filesystem are automatically removed from the index.
- Extensive File Format Support: Supports multiple file formats including
.csv, .docx, .epub, .hwp, .ipynb, .mbox, .md, .pdf, .png, .ppt, .pptm, .pptx, .json, and more.
🛠 Prerequisites
Install conda for WSL2 (Windows Subsystem for Linux 2):
- Open your WSL2 terminal
- Download the Miniconda installer:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh - Run the installer:
bash Miniconda3-latest-Linux-x86_64.sh - Follow the prompts to complete the installation
- Restart your terminal or run source ~/.bashrc
Install conda for Windows:
- Download the Miniconda installer for Windows from https://docs.conda.io/en/latest/miniconda.html
- Run the .exe file and follow the installation prompts
- Choose whether to add Conda to your PATH environment variable during installation
Install conda for Linux:
- Open a terminal
- Download the Miniconda installer
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh - Run the installer:
bash Miniconda3-latest-Linux-x86_64.sh
4.Follow the prompts to complete the installation - Restart your terminal or run
source ~/.bashrc
Install conda for macOS:
- Open a terminal
- Download the Miniconda installer
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-x86_64.sh - Run the installer:
bash Miniconda3-latest-MacOSX-x86_64.sh
4.Follow the prompts to complete the installation - Restart your terminal or run
source ~/.bash_profile
After installation on any platform, verify the installation by running:
conda --version
📦Installation
- Use conda to create env in your project folder:
conda create env --name <your_env_name> python=3.10
conda activate <your_env_name>
- Then, install NexuSync under your conda env, run the following command:
pip install nexusync
Or git clone https://github.com/Zakk-Yang/nexusync.git
- Install pytorch (https://pytorch.org/get-started/locally/):
- If you are using cuda, make sure your cuda version matches:
- For CUDA 11.8 (example, for windows and wsl2/linux)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 - For CUDA 12.1 (example, for windows and wsl2/linux)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 - For macOS
pip3 install torch torchvision torchaudio
🌟 Quick Start
Here's how you can get started with NexuSync:
-
Import NexuSync
from nexusync import NexuSync
-
Choose Your Model
Option A: Using OpenAI Model
OPENAI_MODEL_YN = True
EMBEDDING_MODEL = "text-embedding-3-large"
LANGUAGE_MODEL = "gpt-4o-mini"
TEMPERATURE = 0.4
CHROMA_DB_DIR = 'chroma_db'
INDEX_PERSIST_DIR = 'index_storage'
CHROMA_COLLECTION_NAME = 'my_collection'
INPUT_DIRS = ["../sample_docs"]
CHUNK_SIZE = 1024
CHUNK_OVERLAP = 20
RECURSIVE = True
Option B: Using Ollama Model
OPENAI_MODEL_YN = False
EMBEDDING_MODEL = "BAAI/bge-base-en-v1.5"
LANGUAGE_MODEL = 'llama3.2'
BASE_URL = "http://localhost:11434"
TEMPERATURE = 0.4
CHROMA_DB_DIR = 'chroma_db'
INDEX_PERSIST_DIR = 'index_storage'
CHROMA_COLLECTION_NAME = 'my_collection'
INPUT_DIRS = ["../sample_docs"]
CHUNK_SIZE = 1024
CHUNK_OVERLAP = 20
RECURSIVE = True
3. Initialize Vector DB
ns = NexuSync(input_dirs=INPUT_DIRS,
openai_model_yn=False,
embedding_model=EMBEDDING_MODEL,
language_model=LANGUAGE_MODEL,
base_url = BASE_URL,
temperature=TEMPERATURE,
chroma_db_dir = CHROMA_DB_DIR,
index_persist_dir = INDEX_PERSIST_DIR,
chroma_collection_name=CHROMA_COLLECTION_NAME,
chunk_overlap=CHUNK_OVERLAP,
chunk_size=CHUNK_SIZE,
recursive=RECURSIVE
)
4. Start Quering (quick quering with no memory)
query = "main result of the paper can llm generate novltive ideas"
text_qa_template = """
Context Information:
--------------------
{context_str}
--------------------
Query: {query_str}
Instructions:
1. Carefully read the context information and the query.
2. Think through the problem step by step.
3. Provide a concise and accurate answer based on the given context.
4. If the answer cannot be determined from the context, state "Based on the given information, I cannot provide a definitive answer."
5. If you need to make any assumptions, clearly state them.
6. If relevant, provide a brief explanation of your reasoning.
Answer: """
response = ns.start_query(text_qa_template = text_qa_template, query = query )
print(f"Query: {query}")
print(f"Response: {response['response']}")
print(f"Response: {response['metadata']}")
5. Engage in Stream Chat (token by token output, with Memory)
ns.initialize_stream_chat(
text_qa_template=text_qa_template,
chat_mode="context",
similarity_top_k=3
)
query = "main result of the paper can llm generate novltive ideas"
for item in ns.start_chat_stream(query):
if isinstance(item, str):
print(item, end='', flush=True)
else:
print("\n\nFull response:", item['response'])
print("Metadata:", item['metadata'])
break
6. Access Chat History (for stream chat)
chat_history = ns.chat_engine.get_chat_history()
print("Chat History:")
for entry in chat_history:
print(f"Human: {entry['query']}")
print(f"AI: {entry['response']}\n")
7. Incrementally Refresh Index
ns.refresh_index()
8. Rebuild Index From Scratch
from nexusync import rebuild_index
from nexusync import NexuSync
OPENAI_MODEL_YN = True
EMBEDDING_MODEL = "text-embedding-3-large"
LANGUAGE_MODEL = 'gpt-4o-mini'
TEMPERATURE = 0.4
CHROMA_DB_DIR = 'chroma_db'
INDEX_PERSIST_DIR = 'index_storage'
CHROMA_COLLECTION_NAME = 'my_collection'
INPUT_DIRS = ["../sample_docs"]
CHUNK_SIZE = 1024
CHUNK_OVERLAP = 20
RECURSIVE = True
rebuild_index(input_dirs=INPUT_DIRS,
openai_model_yn=OPENAI_MODEL_YN,
embedding_model=EMBEDDING_MODEL,
language_model=LANGUAGE_MODEL,
temperature=TEMPERATURE,
chroma_db_dir = CHROMA_DB_DIR,
index_persist_dir = INDEX_PERSIST_DIR,
chroma_collection_name=CHROMA_COLLECTION_NAME,
chunk_overlap=CHUNK_OVERLAP,
chunk_size=CHUNK_SIZE,
recursive=RECURSIVE
)
ns = NexuSync(input_dirs=INPUT_DIRS,
openai_model_yn=OPENAI_MODEL_YN,
embedding_model=EMBEDDING_MODEL,
language_model=LANGUAGE_MODEL,
temperature=TEMPERATURE,
chroma_db_dir = CHROMA_DB_DIR,
index_persist_dir = INDEX_PERSIST_DIR,
chroma_collection_name=CHROMA_COLLECTION_NAME,
chunk_overlap=CHUNK_OVERLAP,
chunk_size=CHUNK_SIZE,
recursive=RECURSIVE
)
query = "main result of the paper can llm generate novltive ideas"
text_qa_template = """
Context Information:
--------------------
{context_str}
--------------------
Query: {query_str}
Instructions:
1. Carefully read the context information and the query.
2. Think through the problem step by step.
3. Provide a concise and accurate answer based on the given context.
4. If the answer cannot be determined from the context, state "Based on the given information, I cannot provide a definitive answer."
5. If you need to make any assumptions, clearly state them.
6. If relevant, provide a brief explanation of your reasoning.
Answer: """
response = ns.start_query(text_qa_template = text_qa_template, query = query )
print(f"Query: {query}")
print(f"Response: {response['response']}")
print(f"Response: {response['metadata']}")
🎯 User Interface
- git clone or download this project:
git clone https://github.com/Zakk-Yang/nexusync.git
- Configure Backend
- Open back_end_api.py in your IDE.
- Adjust the parameters according to your requirements.
- Open the terminal and run
python back_end_api.py
Ensure that the parameters in back_end_api.py align with the settings in the side panel of the interface. If not, copy and paste your desired Embedding Model and Language Model in the side panel and click "Apply Settings".
- Start interacting with your data!
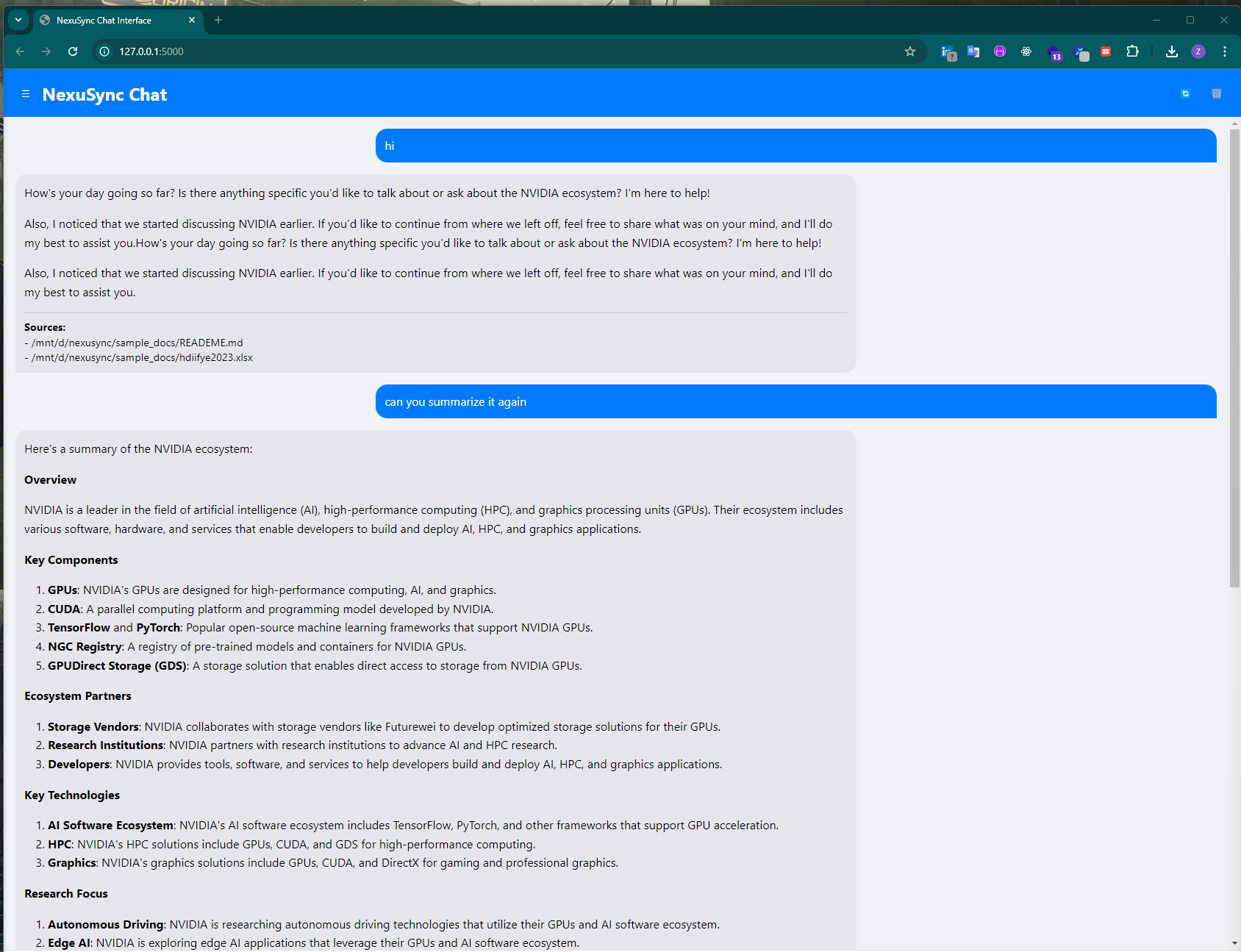
📚 Documentation & Examples
For more detailed usage examples, check out the demo notebooks.
📝 License
This project is licensed under the MIT License - see the LICENSE file for details.
📫 Contact
For questions or suggestions, feel free to open an issue or contact the maintainer:
Name: Zakk Yang
Email: zakkyang@hotmail.com
GitHub: Zakk-Yang
🌟 Support
If you find this project helpful, please give it a ⭐ on GitHub! Your support is appreciated.



