Why LitData?
Speeding up model training involves more than kernel tuning. Data loading frequently slows down training, because datasets are too large to fit on disk, consist of millions of small files, or stream slowly from the cloud.
LitData provides tools to preprocess and optimize datasets into a format that streams efficiently from any cloud or local source. It also includes a map operator for distributed data processing before optimization. This makes data pipelines faster, cloud-agnostic, and can improve training throughput by up to 20×.
Looking for GPUs?
Over 340,000 developers use Lightning Cloud - purpose-built for PyTorch and PyTorch Lightning.
Quick start
First, install LitData:
pip install litdata
Choose your workflow:
🚀 Speed up model training
🚀 Transform datasets
Advanced install
Install all the extras
pip install 'litdata[extras]'
Speed up model training
Stream datasets directly from cloud storage without local downloads. Choose the approach that fits your workflow:
Option 1: Start immediately with existing data ⚡⚡
Stream raw files directly from cloud storage - no pre-optimization needed.
from litdata import StreamingRawDataset
from torch.utils.data import DataLoader
dataset = StreamingRawDataset("s3://my-bucket/raw-data/")
dataloader = DataLoader(dataset, batch_size=32)
for batch in dataloader:
pass
Key benefits:
✅ Instant access: Start streaming immediately without preprocessing.
✅ Zero setup time: No data conversion or optimization required.
✅ Native format: Work with original file formats (images, text, etc.).
✅ Flexible processing: Apply transformations on-the-fly during streaming.
✅ Cloud-native: Stream directly from S3, GCS, or Azure storage.
Option 2: Optimize for maximum performance ⚡⚡⚡
Accelerate model training (20x faster) by optimizing datasets for streaming directly from cloud storage. Work with remote data without local downloads with features like loading data subsets, accessing individual samples, and resumable streaming.
Step 1: Optimize your data (one-time setup)
Transform raw data into optimized chunks for maximum streaming speed.
This step formats the dataset for fast loading by writing data in an efficient chunked binary format.
import numpy as np
from PIL import Image
import litdata as ld
def random_images(index):
fake_images = Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8))
fake_labels = np.random.randint(10)
data = {"index": index, "image": fake_images, "class": fake_labels}
return data
if __name__ == "__main__":
ld.optimize(
fn=random_images,
inputs=list(range(1000)),
output_dir="fast_data",
num_workers=4,
chunk_bytes="64MB"
)
Step 2: Put the data on the cloud
Upload the data to a Lightning Studio (backed by S3) or your own S3 bucket:
aws s3 cp --recursive fast_data s3://my-bucket/fast_data
Step 3: Stream the data during training
Load the data by replacing the PyTorch Dataset and DataLoader with the StreamingDataset and StreamingDataLoader.
import litdata as ld
dataset = ld.StreamingDataset('s3://my-bucket/fast_data', shuffle=True, drop_last=True)
def collate_fn(batch):
return {
"image": [sample["image"] for sample in batch],
"class": [sample["class"] for sample in batch],
}
dataloader = ld.StreamingDataLoader(dataset, collate_fn=collate_fn)
for sample in dataloader:
img, cls = sample["image"], sample["class"]
Key benefits:
✅ Accelerate training: Optimized datasets load 20x faster.
✅ Stream cloud datasets: Work with cloud data without downloading it.
✅ PyTorch-first: Works with PyTorch libraries like PyTorch Lightning, Lightning Fabric, Hugging Face.
✅ Easy collaboration: Share and access datasets in the cloud, streamlining team projects.
✅ Scale across GPUs: Streamed data automatically scales to all GPUs.
✅ Flexible storage: Use S3, GCS, Azure, or your own cloud account for data storage.
✅ Compression: Reduce your data footprint by using advanced compression algorithms.
✅ Run local or cloud: Run on your own machines or auto-scale to 1000s of cloud GPUs with Lightning Studios.
✅ Enterprise security: Self host or process data on your cloud account with Lightning Studios.
Transform datasets
Accelerate data processing tasks (data scraping, image resizing, embedding creation, distributed inference) by parallelizing (map) the work across many machines at once.
Here's an example that resizes and crops a large image dataset:
from PIL import Image
import litdata as ld
input_dir = "my_large_images"
output_dir = "my_resized_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
ld.map(
fn=resize_image,
inputs=inputs,
output_dir="output_dir",
)
Key benefits:
✅ Parallelize processing: Reduce processing time by transforming data across multiple machines simultaneously.
✅ Scale to large data: Increase the size of datasets you can efficiently handle.
✅ Flexible usecases: Resize images, create embeddings, scrape the internet, etc...
✅ Run local or cloud: Run on your own machines or auto-scale to 1000s of cloud GPUs with Lightning Studios.
✅ Enterprise security: Self host or process data on your cloud account with Lightning Studios.
Key Features
Features for optimizing and streaming datasets for model training
✅ Stream raw datasets from cloud storage (beta) 🔗
Effortlessly stream raw files (images, text, etc.) directly from S3, GCS, and Azure cloud storage without any optimization or conversion. Ideal for workflows requiring instant access to original data in its native format.
Prerequisites:
Install the required dependencies to stream raw datasets from cloud storage like Amazon S3 or Google Cloud Storage:
pip install "litdata[extra]" s3fs
pip install "litdata[extra]" gcsfs
Usage Example:
from torch.utils.data import DataLoader
from litdata import StreamingRawDataset
dataset = StreamingRawDataset("s3://bucket/files/")
loader = DataLoader(dataset, batch_size=32)
for batch in loader:
pass
Use StreamingRawDataset to stream your data as-is. Use StreamingDataset for fastest streaming after optimizing your data.
You can also customize how files are grouped by subclassing StreamingRawDataset and overriding the setup method. This is useful for pairing related files (e.g., image and mask, audio and transcript) or any custom grouping logic.
from typing import Union
from torch.utils.data import DataLoader
from litdata import StreamingRawDataset
from litdata.raw.indexer import FileMetadata
class SegmentationRawDataset(StreamingRawDataset):
def setup(self, files: list[FileMetadata]) -> Union[list[FileMetadata], list[list[FileMetadata]]]:
pass
dataset = SegmentationRawDataset("s3://bucket/files/")
loader = DataLoader(dataset, batch_size=32)
for item in loader:
pass
Smart Index Caching
StreamingRawDataset automatically caches the file index for instant startup. Initial scan, builds and caches the index, then subsequent runs load instantly.
Two-Level Cache:
- Local: Stored in your cache directory for instant access
- Remote: Automatically saved to cloud storage (e.g.,
s3://bucket/files/index.json.zstd) for reuse
Force Rebuild:
dataset = StreamingRawDataset("s3://bucket/files/", recompute_index=True)
✅ Stream large cloud datasets 🔗
Use data stored on the cloud without needing to download it all to your computer, saving time and space.
Imagine you're working on a project with a huge amount of data stored online. Instead of waiting hours to download it all, you can start working with the data almost immediately by streaming it.
Once you've optimized the dataset with LitData, stream it as follows:
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset('s3://my-bucket/my-data', shuffle=True)
dataloader = StreamingDataLoader(dataset, batch_size=64)
for batch in dataloader:
process(batch)
Additionally, you can inject client connection settings for S3 or GCP when initializing your dataset. This is useful for specifying custom endpoints and credentials per dataset.
from litdata import StreamingDataset
storage_options = {
"endpoint_url": "your_endpoint_url",
"aws_access_key_id": "your_access_key_id",
"aws_secret_access_key": "your_secret_access_key",
}
dataset = StreamingDataset('s3://my-bucket/my-data', storage_options=storage_options)
dataset = StreamingDataset('s3://my-bucket/my-data', storage_options=storage_options)
Also, you can specify a custom cache directory when initializing your dataset. This is useful when you want to store the cache in a specific location.
from litdata import StreamingDataset
dataset = StreamingDataset('s3://my-bucket/my-data', cache_dir="/path/to/cache")
✅ Stream Hugging Face 🤗 datasets 🔗
To use your favorite Hugging Face dataset with LitData, simply pass its URL to StreamingDataset.
How to get HF dataset URI?
https://github.com/user-attachments/assets/3ba9e2ef-bf6b-41fc-a578-e4b4113a0e72
Prerequisites:
Install the required dependencies to stream Hugging Face datasets:
pip install "litdata[extra]" huggingface_hub
pip install hf_transfer
export HF_HUB_ENABLE_HF_TRANSFER=1
Stream Hugging Face dataset:
import litdata as ld
hf_dataset_uri = "hf://datasets/leonardPKU/clevr_cogen_a_train/data"
dataset = ld.StreamingDataset(hf_dataset_uri)
print("Sample", dataset[0])
dataloader = ld.StreamingDataLoader(dataset, batch_size=4)
for sample in dataloader:
pass
You don’t need to worry about indexing the dataset or any other setup. LitData will handle all the necessary steps automatically and cache the index.json file, so you won't have to index it again.
This ensures that the next time you stream the dataset, the indexing step is skipped..
Indexing the HF dataset (Optional)
If the Hugging Face dataset hasn't been indexed yet, you can index it first using the index_hf_dataset method, and then stream it using the code above.
import litdata as ld
hf_dataset_uri = "hf://datasets/leonardPKU/clevr_cogen_a_train/data"
ld.index_hf_dataset(hf_dataset_uri)
-
Indexing the Hugging Face dataset ahead of time will make streaming abit faster, as it avoids the need for real-time indexing during streaming.
-
To use HF gated dataset, ensure the HF_TOKEN environment variable is set.
Note: For HuggingFace datasets, indexing & streaming is supported only for datasets in Parquet format.
Full Workflow for Hugging Face Datasets
For full control over the cache path(where index.json file will be stored) and other configurations, follow these steps:
- Index the Hugging Face dataset first:
import litdata as ld
hf_dataset_uri = "hf://datasets/open-thoughts/OpenThoughts-114k/data"
ld.index_parquet_dataset(hf_dataset_uri, "hf-index-dir")
- To stream HF datasets now, pass the
HF dataset URI, the path where the index.json file is stored, and ParquetLoader as the item_loader to the StreamingDataset:
import litdata as ld
from litdata.streaming.item_loader import ParquetLoader
hf_dataset_uri = "hf://datasets/open-thoughts/OpenThoughts-114k/data"
dataset = ld.StreamingDataset(hf_dataset_uri, item_loader=ParquetLoader(), index_path="hf-index-dir")
for batch in ld.StreamingDataLoader(dataset, batch_size=4):
pass
LitData Optimize v/s Parquet
Below is the benchmark for the Imagenet dataset (155 GB), demonstrating that optimizing the dataset using LitData is faster and results in smaller output size compared to raw Parquet files.
| LitData Optimize Dataset | 45 | 283.17 | 4000-4700 |
| Parquet Optimize Dataset | 51 | 465.96 | 3600-3900 |
| Index Parquet Dataset (overhead) | N/A | 6 | N/A |
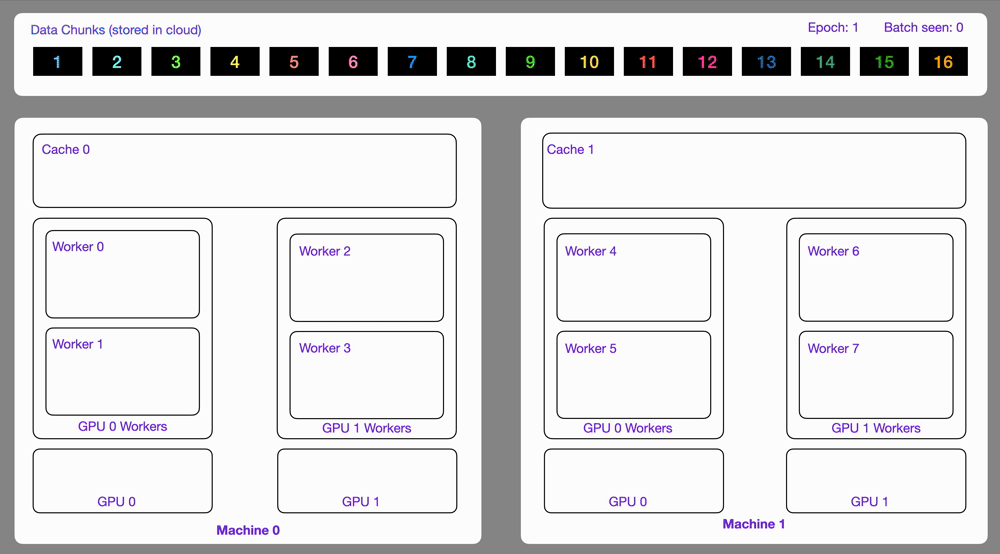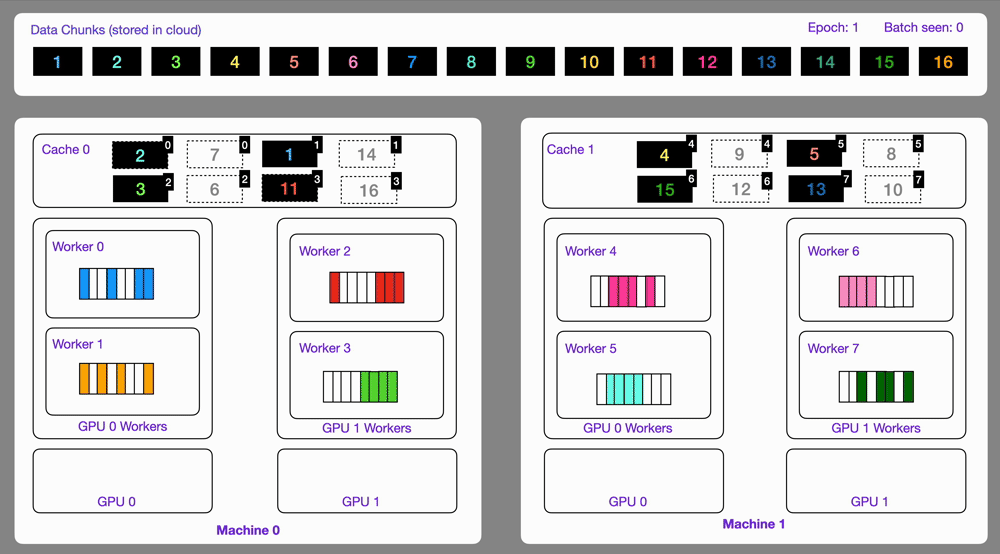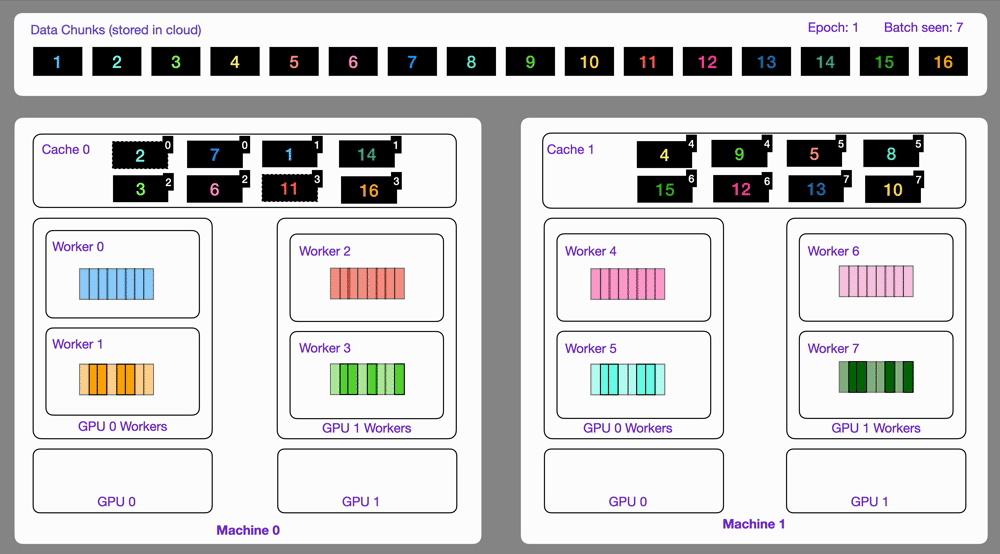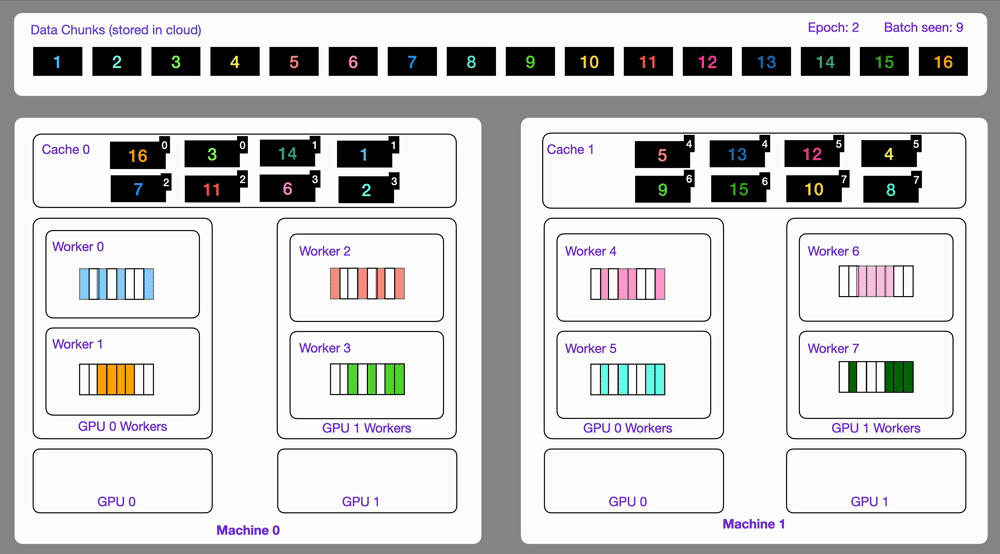
✅ Streams on multi-GPU, multi-node 🔗
Data optimized and loaded with Lightning automatically streams efficiently in distributed training across GPUs or multi-node.
The StreamingDataset and StreamingDataLoader automatically make sure each rank receives the same quantity of varied batches of data, so it works out of the box with your favorite frameworks (PyTorch Lightning, Lightning Fabric, or PyTorch) to do distributed training.
Here you can see an illustration showing how the Streaming Dataset works with multi node / multi gpu under the hood.
from litdata import StreamingDataset, StreamingDataLoader
train_dataset = StreamingDataset('s3://my-bucket/my-train-data', shuffle=True, drop_last=True)
train_dataloader = StreamingDataLoader(train_dataset, batch_size=64)
for batch in train_dataloader:
process(batch)
val_dataset = StreamingDataset('s3://my-bucket/my-val-data', shuffle=False, drop_last=False)
val_dataloader = StreamingDataLoader(val_dataset, batch_size=64)
for batch in val_dataloader:
process(batch)
✅ Stream from multiple cloud providers 🔗
The StreamingDataset provides support for reading optimized datasets from common cloud storage providers like AWS S3, Google Cloud Storage (GCS), and Azure Blob Storage. Below are examples of how to use StreamingDataset with each cloud provider.
import os
import litdata as ld
aws_storage_options={
"aws_access_key_id": os.environ['AWS_ACCESS_KEY_ID'],
"aws_secret_access_key": os.environ['AWS_SECRET_ACCESS_KEY'],
}
aws_session_options = {
"profile_name": os.environ['AWS_PROFILE_NAME'],
"region_name": os.environ['AWS_REGION_NAME'],
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options, session_options=aws_session_options)
aws_storage_options={
"config": botocore.config.Config(
retries={"max_attempts": 1000, "mode": "adaptive"},
signature_version=botocore.UNSIGNED,
)
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
aws_storage_options={
"AWS_ACCESS_KEY_ID": os.environ['AWS_ACCESS_KEY_ID'],
"AWS_SECRET_ACCESS_KEY": os.environ['AWS_SECRET_ACCESS_KEY'],
"S3_ENDPOINT_URL": os.environ['AWS_ENDPOINT_URL'],
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
gcp_storage_options={
"project": os.environ['PROJECT_ID'],
}
dataset = ld.StreamingDataset("gs://my-bucket/my-data", storage_options=gcp_storage_options)
azure_storage_options={
"account_url": f"https://{os.environ['AZURE_ACCOUNT_NAME']}.blob.core.windows.net",
"credential": os.environ['AZURE_ACCOUNT_ACCESS_KEY']
}
dataset = ld.StreamingDataset("azure://my-bucket/my-data", storage_options=azure_storage_options)
✅ Pause, resume data streaming 🔗
Stream data during long training, if interrupted, pick up right where you left off without any issues.
LitData provides a stateful Streaming DataLoader e.g. you can pause and resume your training whenever you want.
Info: The Streaming DataLoader was used by Lit-GPT to pretrain LLMs. Restarting from an older checkpoint was critical to get to pretrain the full model due to several failures (network, CUDA Errors, etc..).
import os
import torch
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset("s3://my-bucket/my-data", shuffle=True)
dataloader = StreamingDataLoader(dataset, num_workers=os.cpu_count(), batch_size=64)
if os.path.isfile("dataloader_state.pt"):
state_dict = torch.load("dataloader_state.pt")
dataloader.load_state_dict(state_dict)
for batch_idx, batch in enumerate(dataloader):
if batch_idx % 1000 == 0:
torch.save(dataloader.state_dict(), "dataloader_state.pt")
✅ Use shared queue for Optimizing 🔗
If you are using multiple workers to optimize your dataset, you can use a shared queue to speed up the process.
This is especially useful when optimizing large datasets in parallel, where some workers may be slower than others.
It can also improve fault tolerance when workers fail due to out-of-memory (OOM) errors.
import numpy as np
from PIL import Image
import litdata as ld
def random_images(index):
fake_images = Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8))
fake_labels = np.random.randint(10)
data = {"index": index, "image": fake_images, "class": fake_labels}
return data
if __name__ == "__main__":
ld.optimize(
fn=random_images,
inputs=list(range(1000)),
output_dir="fast_data",
num_workers=4,
chunk_bytes="64MB" ,
keep_data_ordered=False,
)
Performance Difference between using a shared queue and not using it:
Note: The following benchmarks were collected using the ImageNet dataset on an A10G machine with 16 workers.
shared_queue (keep_data_ordered=False) | 1281 | 5392 | 5732 |
no shared_queue (keep_data_ordered=True (default)) | 1187 | 5257 | 5746 |
📌 Note: The shared_queue option impacts optimization time, not streaming speed.
While the streaming numbers may appear slightly different, this variation is incidental and not caused by shared_queue.
Streaming happens after optimization and does not involve inter-process communication where shared_queue plays a role.
-
📄 Using a shared queue helps balance the load across workers, though it may slightly increase optimization time due to the overhead of pickling items sent between processes.
-
⚡ However, it can significantly improve optimizing performance — especially when some workers are slower than others.
✅ Use a Queue as input for optimizing data 🔗
Sometimes you don’t have a static list of inputs to optimize — instead, you have a stream of data coming in over time. In such cases, you can use a multiprocessing.Queue to feed data into the optimize() function.
-
This is especially useful when you're collecting data from a remote source like a web scraper, socket, or API.
-
You can also use this setup to store replay buffer data during reinforcement learning and later stream it back for training.
from multiprocessing import Process, Queue
from litdata.processing.data_processor import ALL_DONE
import litdata as ld
import time
def yield_numbers():
for i in range(1000):
time.sleep(0.01)
yield (i, i**2)
def data_producer(q: Queue):
for item in yield_numbers():
q.put(item)
q.put(ALL_DONE)
def fn(index):
return index
if __name__ == "__main__":
q = Queue(maxsize=100)
producer = Process(target=data_producer, args=(q,))
producer.start()
ld.optimize(
fn=fn,
queue=q,
output_dir="fast_data",
num_workers=2,
chunk_size=100,
mode="overwrite",
)
producer.join()
📌 Note: Using queues to optimize your dataset impacts optimization time, not streaming speed.
Irrespective of number of workers, you only need to put one sentinel value to signal completion.
It'll be handled internally by LitData.
✅ LLM Pre-training 🔗
LitData is highly optimized for LLM pre-training. First, we need to tokenize the entire dataset and then we can consume it.
import json
from pathlib import Path
import zstandard as zstd
from litdata import optimize, TokensLoader
from tokenizer import Tokenizer
from functools import partial
def tokenize_fn(filepath, tokenizer=None):
with zstd.open(open(filepath, "rb"), "rt", encoding="utf-8") as f:
for row in f:
text = json.loads(row)["text"]
if json.loads(row)["meta"]["redpajama_set_name"] == "RedPajamaGithub":
continue
text_ids = tokenizer.encode(text, bos=False, eos=True)
yield text_ids
if __name__ == "__main__":
input_dir = "./slimpajama-raw"
inputs = [str(file) for file in Path(f"{input_dir}/SlimPajama-627B/train").rglob("*.zst")]
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")),
inputs=inputs,
output_dir="./slimpajama-optimized",
chunk_size=(2049 * 8012),
item_loader=TokensLoader(),
)
import os
from litdata import StreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
dataset = StreamingDataset(
input_dir=f"./slimpajama-optimized/train",
item_loader=TokensLoader(block_size=2048 + 1),
shuffle=True,
drop_last=True,
)
train_dataloader = StreamingDataLoader(dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
for batch in tqdm(train_dataloader):
pass
✅ Filter illegal data 🔗
Sometimes, you have bad data that you don't want to include in the optimized dataset. With LitData, yield only the good data sample to include.
from litdata import optimize, StreamingDataset
def should_keep(index) -> bool:
return index % 2 == 0
def fn(data):
if should_keep(data):
yield data
if __name__ == "__main__":
optimize(
fn=fn,
inputs=list(range(1000)),
output_dir="only_even_index_optimized",
chunk_bytes="64MB",
num_workers=1
)
dataset = StreamingDataset("only_even_index_optimized")
data = list(dataset)
print(data)
You can even use try/expect.
from litdata import optimize, StreamingDataset
def fn(data):
try:
yield 1 / data
except:
pass
if __name__ == "__main__":
optimize(
fn=fn,
inputs=[0, 0, 0, 1, 2, 4, 0],
output_dir="only_defined_ratio_optimized",
chunk_bytes="64MB",
num_workers=1
)
dataset = StreamingDataset("only_defined_ratio_optimized")
data = list(dataset)
print(data)
✅ Combine datasets 🔗
Mix and match different sets of data to experiment and create better models.
Combine datasets with CombinedStreamingDataset. As an example, this mixture of Slimpajama & StarCoder was used in the TinyLLAMA project to pretrain a 1.1B Llama model on 3 trillion tokens.
from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
import os
train_datasets = [
StreamingDataset(
input_dir="s3://tinyllama-template/slimpajama/train/",
item_loader=TokensLoader(block_size=2048 + 1),
shuffle=True,
drop_last=True,
),
StreamingDataset(
input_dir="s3://tinyllama-template/starcoder/",
item_loader=TokensLoader(block_size=2048 + 1),
shuffle=True,
drop_last=True,
),
]
weights = (0.693584, 0.306416)
combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights, iterate_over_all=False)
train_dataloader = StreamingDataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
for batch in tqdm(train_dataloader):
pass
Batching Methods
The CombinedStreamingDataset supports two different batching methods through the batching_method parameter:
Stratified Batching (Default):
With batching_method="stratified" (the default), each batch contains samples from multiple datasets according to the specified weights:
combined_dataset = CombinedStreamingDataset(
datasets=[dataset1, dataset2],
batching_method="stratified"
)
Per-Stream Batching:
With batching_method="per_stream", each batch contains samples exclusively from a single dataset. This is useful when datasets have different shapes or structures:
combined_dataset = CombinedStreamingDataset(
datasets=[dataset1, dataset2],
batching_method="per_stream"
)
✅ Parallel streaming 🔗
While CombinedDataset allows to fetch a sample from one of the datasets it wraps at each iteration, ParallelStreamingDataset can be used to fetch a sample from all the wrapped datasets at each iteration:
from litdata import StreamingDataset, ParallelStreamingDataset, StreamingDataLoader
from tqdm import tqdm
parallel_dataset = ParallelStreamingDataset(
[
StreamingDataset(input_dir="input_dir_1"),
StreamingDataset(input_dir="input_dir_2"),
],
)
dataloader = StreamingDataLoader(parallel_dataset)
for batch_1, batch_2 in tqdm(dataloader):
pass
This is useful to generate new data on-the-fly using a sample from each dataset. To do so, provide a transform function to ParallelStreamingDataset:
def transform(samples: Tuple[Any]):
sample_1, sample_2 = samples
return sample_1 + sample_2
parallel_dataset = ParallelStreamingDataset([dset_1, dset_2], transform=transform)
dataloader = StreamingDataLoader(parallel_dataset)
for transformed_batch in tqdm(dataloader):
pass
If the transformation requires random number generation, internal random number generators provided by ParallelStreamingDataset can be used. These are seeded using the current dataset state at the beginning of each epoch, which allows for reproducible and resumable data transformation. To use them, define a transform which takes a dictionary of random number generators as its second argument:
def transform(samples: Tuple[Any], rngs: Dict[str, Any]):
sample_1, sample_2 = samples
rng = rngs["random"]
return rng.random() * sample_1 + rng.random() * sample_2
parallel_dataset = ParallelStreamingDataset([dset_1, dset_2], transform=transform)
✅ Cycle datasets 🔗
ParallelStreamingDataset can also be used to cycle a StreamingDataset. This allows to dissociate the epoch length from the number of samples in the dataset.
To do so, set the length option to the desired number of samples to yield per epoch. If length is greater than the number of samples in the dataset, the dataset is cycled. At the beginning of a new epoch, the dataset resumes from where it left off at the end of the previous epoch.
from litdata import StreamingDataset, ParallelStreamingDataset, StreamingDataLoader
from tqdm import tqdm
dataset = StreamingDataset(input_dir="input_dir")
cycled_dataset = ParallelStreamingDataset([dataset], length=100)
print(len(cycled_dataset)))
dataloader = StreamingDataLoader(cycled_dataset)
for batch, in tqdm(dataloader):
pass
You can even set length to float("inf") for an infinite dataset!
✅ Merge datasets 🔗
Merge multiple optimized datasets into one.
import numpy as np
from PIL import Image
from litdata import StreamingDataset, merge_datasets, optimize
def random_images(index):
return {
"index": index,
"image": Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8)),
"class": np.random.randint(10),
}
if __name__ == "__main__":
out_dirs = ["fast_data_1", "fast_data_2", "fast_data_3", "fast_data_4"]
for out_dir in out_dirs:
optimize(fn=random_images, inputs=list(range(250)), output_dir=out_dir, num_workers=4, chunk_bytes="64MB")
merged_out_dir = "merged_fast_data"
merge_datasets(input_dirs=out_dirs, output_dir=merged_out_dir)
dataset = StreamingDataset(merged_out_dir)
print(len(dataset))
✅ Transform datasets while Streaming 🔗
Transform datasets on-the-fly while streaming them, allowing for efficient data processing without the need to store intermediate results.
- You can use the
transform argument in StreamingDataset to apply a transformation function or a list of transformation functions to each sample as it is streamed.
torch_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
def transform_fn(x, *args, **kwargs):
"""Define your transform function."""
return torch_transform(x)
dataset = StreamingDataset(data_dir, cache_dir=str(cache_dir), shuffle=shuffle, transform=[transform_fn])
Or, you can create a subclass of StreamingDataset and override its transform method to apply custom transformations to each sample.
class StreamingDatasetWithTransform(StreamingDataset):
"""A custom dataset class that inherits from StreamingDataset and applies a transform."""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.torch_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
def transform(self, x, *args, **kwargs):
"""A simple transform function."""
return self.torch_transform(x)
dataset = StreamingDatasetWithTransform(data_dir, cache_dir=str(cache_dir), shuffle=shuffle)
✅ Split datasets for train, val, test 🔗
Split a dataset into train, val, test splits with train_test_split.
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data")
print(len(dataset))
train_dataset, val_dataset, test_dataset = train_test_split(dataset, splits=[0.3, 0.2, 0.5])
print(train_dataset)
print(val_dataset)
print(test_dataset)
✅ Load a subset of the remote dataset 🔗
Work on a smaller, manageable portion of your data to save time and resources.
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=0.01)
print(len(dataset))
✅ Upsample from your source datasets 🔗
Use to control the size of one iteration of a StreamingDataset using repeats. Contains floor(N) possibly shuffled copies of the source data, then a subsampling of the remainder.
from litdata import StreamingDataset
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=2.5, shuffle=True)
print(len(dataset))
✅ Easily modify optimized cloud datasets 🔗
Add new data to an existing dataset or start fresh if needed, providing flexibility in data management.
LitData optimized datasets are assumed to be immutable. However, you can make the decision to modify them by changing the mode to either append or overwrite.
from litdata import optimize, StreamingDataset
def compress(index):
return index, index**2
if __name__ == "__main__":
optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
)
optimize(
fn=compress,
inputs=list(range(100, 200)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
mode="append",
)
ds = StreamingDataset("./my_optimized_dataset")
assert len(ds) == 200
assert ds[:] == [(i, i**2) for i in range(200)]
The overwrite mode will delete the existing data and start from fresh.
✅ Stream parquet datasets 🔗
Stream Parquet datasets directly with LitData—no need to convert them into LitData’s optimized binary format! If your dataset is already in Parquet format, you can efficiently index and stream it using StreamingDataset and StreamingDataLoader.
Assumption:
Your dataset directory contains one or more Parquet files.
Prerequisites:
Install the required dependencies to stream Parquet datasets from cloud storage like Amazon S3 or Google Cloud Storage:
pip install "litdata[extra]" s3fs
pip install "litdata[extra]" gcsfs
Index Your Dataset:
Index your Parquet dataset to create an index file that LitData can use to stream the dataset.
import litdata as ld
pq_dataset_uri = "s3://my-bucket/my-parquet-data"
ld.index_parquet_dataset(pq_dataset_uri)
Stream the Dataset
Use StreamingDataset with ParquetLoader to load and stream the dataset efficiently:
import litdata as ld
from litdata.streaming.item_loader import ParquetLoader
pq_dataset_uri = "s3://my-bucket/my-parquet-data"
dataset = ld.StreamingDataset(pq_dataset_uri, item_loader=ParquetLoader())
print("Sample", dataset[0])
dataloader = ld.StreamingDataLoader(dataset, batch_size=4)
for sample in dataloader:
pass
✅ Use compression 🔗
Reduce your data footprint by using advanced compression algorithms.
import litdata as ld
def compress(index):
return index, index**2
if __name__ == "__main__":
ld.optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
num_workers=1,
compression="zstd"
)
Using zstd, you can achieve high compression ratio like 4.34x for this simple example.
✅ Access samples without full data download 🔗
Look at specific parts of a large dataset without downloading the whole thing or loading it on a local machine.
from litdata import StreamingDataset
dataset = StreamingDataset("s3://my-bucket/my-data")
print(len(dataset))
print(dataset[42])
✅ Use any data transforms 🔗
Customize how your data is processed to better fit your needs.
Subclass the StreamingDataset and override its __getitem__ method to add any extra data transformations.
from litdata import StreamingDataset, StreamingDataLoader
import torchvision.transforms.v2.functional as F
class ImagenetStreamingDataset(StreamingDataset):
def __getitem__(self, index):
image = super().__getitem__(index)
return F.resize(image, (224, 224))
dataset = ImagenetStreamingDataset(...)
dataloader = StreamingDataLoader(dataset, batch_size=4)
for batch in dataloader:
print(batch.shape)
✅ Profile data loading speed 🔗
Measure and optimize how fast your data is being loaded, improving efficiency.
The StreamingDataLoader supports profiling of your data loading process. Simply use the profile_batches argument to specify the number of batches you want to profile:
from litdata import StreamingDataset, StreamingDataLoader
StreamingDataLoader(..., profile_batches=5)
This generates a Chrome trace called result.json. Then, visualize this trace by opening Chrome browser at the chrome://tracing URL and load the trace inside.
✅ Reduce memory use for large files 🔗
Handle large data files efficiently without using too much of your computer's memory.
When processing large files like compressed parquet files, use the Python yield keyword to process and store one item at the time, reducing the memory footprint of the entire program.
from pathlib import Path
import pyarrow.parquet as pq
from litdata import optimize
from tokenizer import Tokenizer
from functools import partial
def tokenize_fn(filepath, tokenizer=None):
parquet_file = pq.ParquetFile(filepath)
for batch in parquet_file.iter_batches(batch_size=8192, columns=["content"]):
for text in batch.to_pandas()["content"]:
yield tokenizer.encode(text, bos=False, eos=True)
input_dir = "/teamspace/s3_connections/tinyllama-template"
inputs = [str(file) for file in Path(f"{input_dir}/starcoderdata").rglob("*.parquet")]
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")),
inputs=inputs,
output_dir="/teamspace/datasets/starcoderdata",
chunk_size=(2049 * 8012),
)
✅ Limit local cache space 🔗
Limit the amount of disk space used by temporary files, preventing storage issues.
Adapt the local caching limit of the StreamingDataset. This is useful to make sure the downloaded data chunks are deleted when used and the disk usage stays low.
from litdata import StreamingDataset
dataset = StreamingDataset(..., max_cache_size="10GB")
✅ Change cache directory path 🔗
Specify the directory where cached files should be stored, ensuring efficient data retrieval and management. This is particularly useful for organizing your data storage and improving access times.
from litdata import StreamingDataset
from litdata.streaming.cache import Dir
cache_dir = "/path/to/your/cache"
data_dir = "s3://my-bucket/my_optimized_dataset"
dataset = StreamingDataset(input_dir=Dir(path=cache_dir, url=data_dir))
✅ Optimize loading on networked drives 🔗
Optimize data handling for computers on a local network to improve performance for on-site setups.
On-prem compute nodes can mount and use a network drive. A network drive is a shared storage device on a local area network. In order to reduce their network overload, the StreamingDataset supports caching the data chunks.
from litdata import StreamingDataset
dataset = StreamingDataset(input_dir="local:/data/shared-drive/some-data")
✅ Optimize dataset in distributed environment 🔗
Lightning can distribute large workloads across hundreds of machines in parallel. This can reduce the time to complete a data processing task from weeks to minutes by scaling to enough machines.
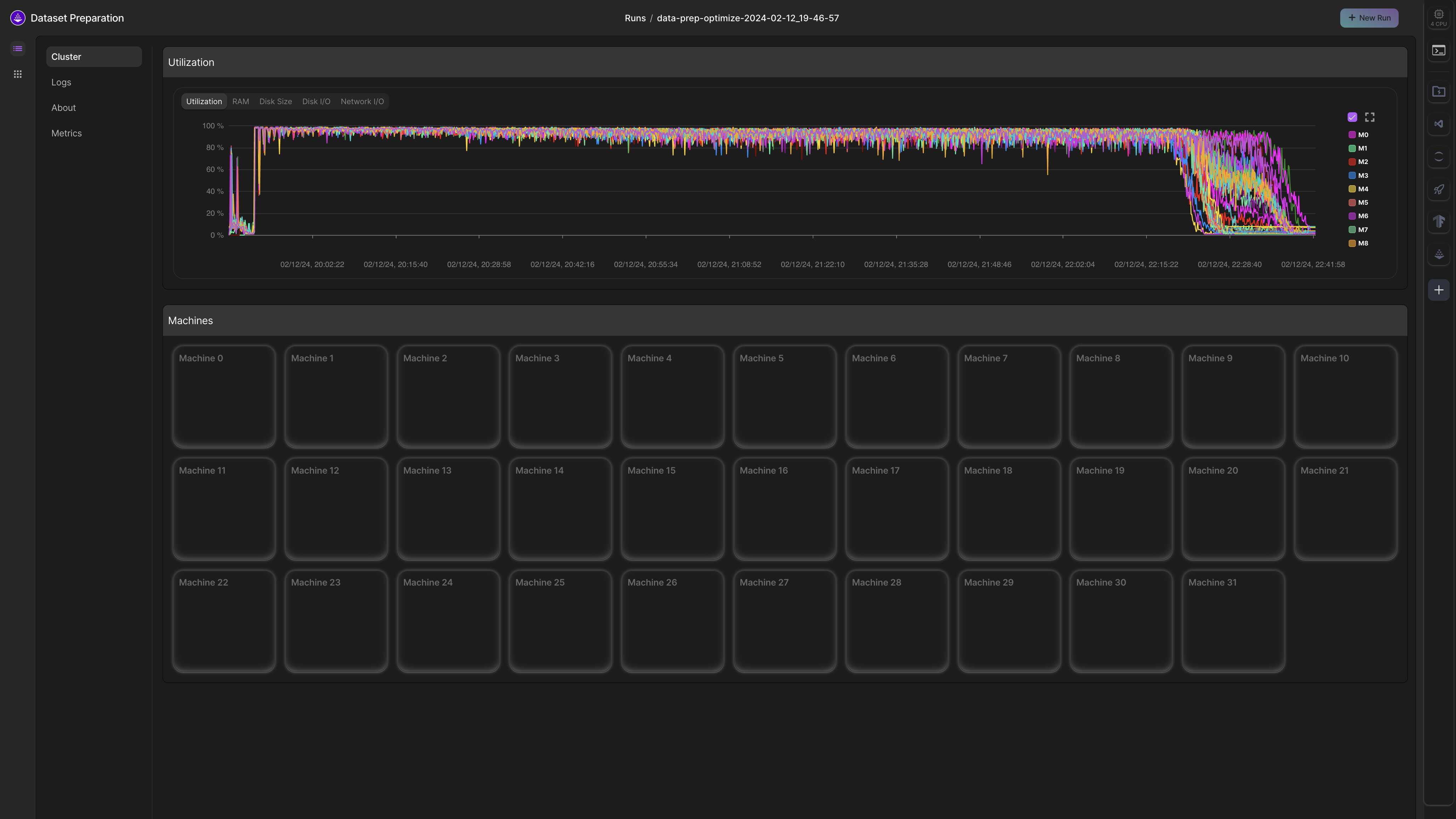
To apply the optimize operator across multiple machines, simply provide the num_nodes and machine arguments to it as follows:
import os
from litdata import optimize, Machine
def compress(index):
return (index, index ** 2)
optimize(
fn=compress,
inputs=list(range(100)),
num_workers=2,
output_dir="my_output",
chunk_bytes="64MB",
num_nodes=2,
machine=Machine.DATA_PREP,
)
If the output_dir is a local path, the optimized dataset will be present in: /teamspace/jobs/{job_name}/nodes-0/my_output. Otherwise, it will be stored in the specified output_dir.
Read the optimized dataset:
from litdata import StreamingDataset
output_dir = "/teamspace/jobs/litdata-optimize-2024-07-08/nodes.0/my_output"
dataset = StreamingDataset(output_dir)
print(dataset[:])
✅ Encrypt, decrypt data at chunk/sample level 🔗
Secure data by applying encryption to individual samples or chunks, ensuring sensitive information is protected during storage.
This example shows how to use the FernetEncryption class for sample-level encryption with a data optimization function.
from litdata import optimize
from litdata.utilities.encryption import FernetEncryption
import numpy as np
from PIL import Image
fernet = FernetEncryption(password="your_secure_password", level="sample")
data_dir = "s3://my-bucket/optimized_data"
def random_image(index):
"""Generate a random image for demonstration purposes."""
fake_img = Image.fromarray(np.random.randint(0, 255, (32, 32, 3), dtype=np.uint8))
return {"image": fake_img, "class": index}
optimize(
fn=random_image,
inputs=list(range(5)),
num_workers=1,
output_dir=data_dir,
chunk_bytes="64MB",
encryption=fernet,
)
fernet.save("fernet.pem")
Load the encrypted data using the StreamingDataset class as follows:
from litdata import StreamingDataset
from litdata.utilities.encryption import FernetEncryption
fernet = FernetEncryption(password="your_secure_password", level="sample")
fernet.load("fernet.pem")
ds = StreamingDataset(input_dir=data_dir, encryption=fernet)
Implement your own encryption method: Subclass the Encryption class and define the necessary methods:
from litdata.utilities.encryption import Encryption
class CustomEncryption(Encryption):
def encrypt(self, data):
return data
def decrypt(self, data):
return data
This allows the data to remain secure while maintaining flexibility in the encryption method.
✅ Debug & Profile LitData with logs & Litracer 🔗
LitData comes with built-in logging and profiling capabilities to help you debug and profile your data streaming workloads.

- e.g., with LitData Streaming
import litdata as ld
from litdata.debugger import enable_tracer
enable_tracer()
if __name__ == "__main__":
dataset = ld.StreamingDataset("s3://my-bucket/my-data", shuffle=True)
dataloader = ld.StreamingDataLoader(dataset, batch_size=64)
for batch in dataloader:
print(batch)
-
Key Points:
- For very large trace.json files (
> 2GB), refer to the Perfetto documentation for using native accelerators.
- If you are trying to connect Perfetto to the RPC server, it is recommended to use Chrome over Brave, as it has been observed that Perfetto in Brave does not autodetect the RPC server.
✅ Lightning AI Data Connections - Direct download and upload 🔗
Lightning Studios have special directories for data connections that are available to an entire teamspace. LitData functions that reference those directories will experience a significant performance increase as uploads and downloads will happen directly from the bucket that backs the folder.
For example, output artifacts from this code will be directly uploaded to the my-data-1 s3 bucket.
from litdata import optimize
def should_keep(data):
if data % 2 == 0:
yield data
if __name__ == "__main__":
optimize(
fn=should_keep,
inputs=list(range(1000)),
output_dir="/teamspace/s3_connections/my-data-1/output",
chunk_bytes="64MB",
num_workers=1
)
Similarly, data will be downloaded directly from the my-data-1 s3 bucket in this example code.
from litdata import StreamingRawDataset
if __name__ == "__main__":
data_dir = "/teamspace/s3_connections/my-bucket-1/data"
raw_dataset = StreamingRawDataset(data_dir)
data = list(raw_dataset)
print(data)
References to any of the following directories will work similarly:
/teamspace/lightning_storage/.../teamspace/s3_connections/.../teamspace/gcs_connections/.../teamspace/s3_folders/.../teamspace/gcs_folders/...
Features for transforming datasets
✅ Parallelize data transformations (map) 🔗
Apply the same change to different parts of the dataset at once to save time and effort.
The map operator can be used to apply a function over a list of inputs.
Here is an example where the map operator is used to apply a resize_image function over a folder of large images.
from litdata import map
from PIL import Image
input_dir = "my_large_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
map(
fn=resize_image,
inputs=inputs,
output_dir="s3://my-bucket/my_resized_images",
)
Benchmarks
In this section we show benchmarks for speed to optimize a dataset and the resulting streaming speed (Reproduce the benchmark).
Streaming speed
LitData Chunks
Data optimized and streamed with LitData achieves a 20x speed up over non optimized data and 2x speed up over other streaming solutions.
Speed to stream Imagenet 1.2M from AWS S3:
| LitData | 5839 | 6692 | 6282 | 7221 |
| Web Dataset | 3134 | 3924 | 3343 | 4424 |
| Mosaic ML | 2898 | 5099 | 2809 | 5158 |
Benchmark details
- Imagenet-1.2M dataset contains
1,281,167 images.
- To align with other benchmarks, we measured the streaming speed (
images per second) loaded from AWS S3 for several frameworks.
Speed to stream Imagenet 1.2M from other cloud storage providers:
| Cloudflare R2 | LitData | 5335 | 5630 |
Speed to stream Imagenet 1.2M from local disk with ffcv vs LitData:
| LitData | PIL RAW | 168 GB | 6647 | 6398 |
| LitData | JPEG 90% | 12 GB | 6553 | 6537 |
| ffcv (os_cache=True) | RAW | 170 GB | 7263 | 6698 |
| ffcv (os_cache=False) | RAW | 170 GB | 7556 | 8169 |
| ffcv(os_cache=True) | JPEG 90% | 20 GB | 7653 | 8051 |
| ffcv(os_cache=False) | JPEG 90% | 20 GB | 8149 | 8607 |
Raw Dataset
Speed to stream raw Imagenet 1.2M from different cloud storage providers:
| AWS S3 | ~6400 +/- 100 | ~3200 +/- 100 |
| Google Cloud Storage | ~5650 +/- 100 | ~3100 +/- 100 |
Note:
Use StreamingRawDataset if you want to stream your data as-is. Use StreamingDataset if you want the fastest streaming and are okay with optimizing your data first.
Time to optimize data
LitData optimizes the Imagenet dataset for fast training 3-5x faster than other frameworks:
Time to optimize 1.2 million ImageNet images (Faster is better):
| LitData | 10:05 min | 00:30 min | 143.1 GB | 2.339 |
| Web Dataset | 32:36 min | 01:22 min | 147.8 GB | 1.144 |
| Mosaic ML | 49:49 min | 01:04 min | 143.1 GB | 2.298 |
Parallelize transforms and data optimization on cloud machines
Parallelize data transforms
Transformations with LitData are linearly parallelizable across machines.
For example, let's say that it takes 56 hours to embed a dataset on a single A10G machine. With LitData,
this can be speed up by adding more machines in parallel
To scale the number of machines, run the processing script on Lightning Studios:
from litdata import map, Machine
map(
...
num_nodes=32,
machine=Machine.DATA_PREP,
)
Parallelize data optimization
To scale the number of machines for data optimization, use Lightning Studios:
from litdata import optimize, Machine
optimize(
...
num_nodes=32,
machine=Machine.DATA_PREP,
)
Example: Process the LAION 400 million image dataset in 2 hours on 32 machines, each with 32 CPUs.
Start from a template
Below are templates for real-world applications of LitData at scale.
Templates: Transform datasets
Templates: Optimize + stream data
LitData is a community project accepting contributions - Let's make the world's most advanced AI data processing framework.
💬 Get help on Discord
📋 License: Apache 2.0
Citation
@misc{litdata2023,
author = {Thomas Chaton and Lightning AI},
title = {LitData: Transform datasets at scale. Optimize datasets for fast AI model training.},
year = {2023},
howpublished = {\url{https://github.com/Lightning-AI/litdata}},
note = {Accessed: 2025-04-09}
}
Papers with LitData
Governance
Maintainers
Emeritus Maintainers
Alumni